spark开发教程
目录
- spark开发教程
- 前言
- 一、初始化spark
- 二、获取数据源
- 1.创建数据结构
- 2.连接外部数据
- textfile
- jdbc
- hive
- 3. 数据处理
- rdd算子
- transform算子
- action算子
- dataframe操作
- dataset操作
- 4. 共享变量
- 5.写入数据
- 总结
前言
spark开发主要的基于RDD、Datasets、DataFrame、sql 。其中rdd是最核心的底层,Datasets、DataFrame、sql都是基于rdd封装的高级api,dataframe是datasets的一种(类型为row)。
一、初始化spark
一个spark脚本的提交,会产生一个driver,如何通过把driver的运行逻辑传递给各个executor,就是通过sparkcontext。
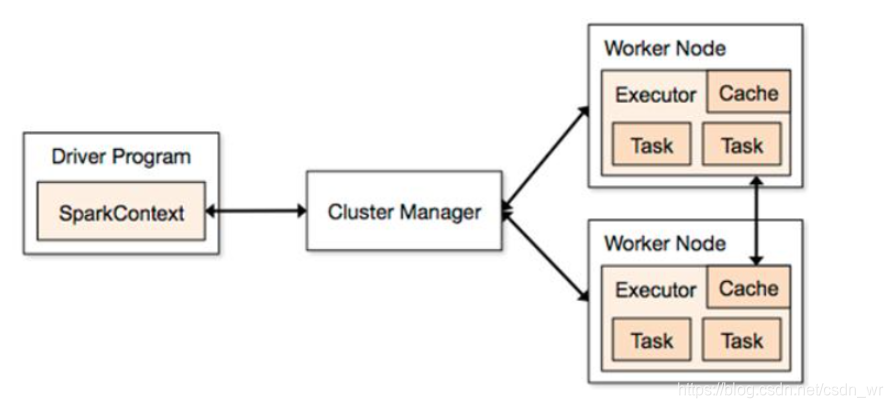
SparkContext是与ClusterManager打交道的,clusterManager类似yarn的resourceManager负责资源的分配。
初始化脚本
val conf = new SparkConf().setAppName(appName).setMaster(master)
new SparkContext(conf)
Spark2.0中只要创建一个SparkSession就够了,SparkConf、SparkContext和SQLContext都已经被封装在SparkSession当中。
参考:spark原理
二、获取数据源
1.创建数据结构
- RDD创建
val lines=sc.parallelize(List("pandas", "apple"))
- DataFrame创建
val df=spark.createDataFrame(Seq(("ming", 20, 15552211521L),("hong", 19, 13287994007L),("zhi", 21, 15552211523L))) toDF("name", "age", "phone")
- DataSet创建
val person1 = new Person("Andy", 32);
val person2 = new Person("katy", 33);
import spark.implicits._
val javaBeanDS= spark.createDataset(List(person1,person2))
SparkSession内部封装了SparkContext,创建sparksession就可以了。
- spark-sql
spark-sql的使用,一般是直接使用sql,通过dataframe 转化为临时表
2.连接外部数据
textfile
可以从本地文件系统或者hdfs文件系统读取数据
spark.sparkContext.textFile(path,1)
-
如果textFile指定分区数量为0或者1的话,defaultMinPartitions值为1,则有多少个文件,就会有多少个分区。
-
如果不指定默认分区数量,则默认分区数量为2,则会根据所有文件字节大小totalSize除以分区数量partitons的值goalSize,然后比较goalSize和hdfs指定分块大小(这里是32M)作比较,以较小的最为goalSize作为切分大小,对每个文件进行切分,若文件大于大于goalSize,则会生成该文件大小/goalSize + 1个分区。
-
如果指定分区数量大于等于2,则默认分区数量为指定值,生成分区数量规则同2中的规则。
参考textFile解读
jdbc
val jdbcDF = spark.read.format("jdbc").options(Map("url" -> "jdbc:mysql://localhost:3306/ontime?user=root&password=mysql","dbtable" -> "ontime.ontime_sm","fetchSize" -> "10000","partitionColumn" -> "yeard", "lowerBound" -> "1988", "upperBound" -> "2015", "numPartitions" -> "48")).load()
hive
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")val session = SparkSession.builder().config(conf)// 指定hive的metastore的端口 默认为9083 在hive-site.xml中查看.config("hive.metastore.uris", "thrift://hadoop-01:9083,thrift://hadoop-02:9083")
3. 数据处理
rdd算子
transform算子
- map
- filter
- flatmap
- mapPartition和mapPartitionWithIndex
- sortBy和sortByKey
- groupBy和groupByKey
- reduceByKey、aggregateByKey、foldByKey、combineByKey
- distinct
- union
- intersection
- join、leftJoin 、rightJoin
- cogroup 类似fulloutJoin
- zip
action算子
- collect
- reduce
- fold
- aggregate
- count
- take top first
- foreach foreachPartition
- saveAsTextFile
-
map
Return a new distributed dataset formed by passing each element of the source through a function func. -
filter(func)
Return a new dataset formed by selecting those elements of the source on which func returns true. -
flatMap(func)
Similar to map,but each input item can be mapped to 0 or more output items(so func should return a Seq rather than a single item). -
union(otherDataset)
Return a new dataset that contain the union of the elements in the source dataset and the argument. -
join(otherDataset,[numTasks])
When called on datasets of type(K,V) and (K,W),returns a dataset of (K,(V,W)) pairs with all pairs of elements for each key.Outer joins are supported leftOutJoin, rightOuterJoin,and fullOuterJoin. -
intersection(otherDataset)
Return a new RDD that contains the intersection of elements in the source dataset and the argument. -
distinct([numTasks])
Return a new dataset that contains the distinct elements of the source dataset. -
groupByKey([numTasks])
When called on a dataset of (K,V) pairs,returns a dataset of (K,Iterable) pairs.
Note:If you are grouping in order to perform an aggregation(such as a sum or average) over each key,using reduceByKey or combineByKey will yield much better performance. -
reduceByKey(func,[numTasks])
When called on a dataset of (K,V) pairs,returns a dataset of (K,V) pairs where the values for each key are aggregated using the given reduce function func,which must be of type(V,V)=>V. Like in groupByKey,the number of reduce tasks is configurable through an optional second argument. -
sortByKey([ascending],[numTasks])
When called on a dataset of (K,V) pairs where K implements Ordered,return a dataset of (K,V) pairs sorted by keys in ascending or descending order,as specified in the boolean ascending argument. -
cogroup
For each key k inthisorother, return a resulting RDD that contains a tuple with the
list of values for that key inthisas well asother.
dataframe操作
- selectExpr
Selects a set of SQL expressions. This is a variant ofselectthat accepts
The following are equivalent:
ds.selectExpr(“colA”, “colB as newName”, “abs(colC)”)
ds.select(expr(“colA”), expr(“colB as newName”), expr(“abs(colC)”))
val df1=spark.createDataFrame(List(( "a" , 1) ,( "a" , 2) ,( "b" , 3),("a",1) ,( "b" , 4) ,("c" , 4))).toDF("a","b")df1.select("dfd","b").show()df1.selectExpr("concat(a,\"b\") as a","b+10").show()
- select
Selects a set of columns. This is a variant ofselectthat can only select
existing columns using column names (i.e. cannot construct expressions).
ds.select(“colA”, “colB”)
ds.select($“colA”, $“colB”)
val df1=spark.createDataFrame(List(( "a" , 1) ,( "a" , 2) ,( "b" , 3),("a",1) ,( "b" , 4) ,("c" , 4))).toDF("a","b")df1.select("dfd","b").show()df1.selectExpr("concat(a,\"b\") as a","b+10").show()
- group
(Scala-specific) Compute aggregates by specifying the column names and
aggregate methods. The resultingDataFramewill also contain the grouping columns.
The available aggregate methods areavg,max,min,sum,count.
// Selects the age of the oldest employee and the aggregate expense for each department
df.groupBy(“department”).agg(
“age” -> “max”,
“expense” -> “sum”
)
df.groupBy("department").agg("age" -> "max","expense" -> "sum")
其他类似RDD算子
dataset操作
dataset与dataframe的区别
4. 共享变量
- 累加变量Accumulator
val list1=spark.sparkContext.parallelize( List(( 'a' , 1) ,( 'a' , 2) ,( 'b' , 3),('a',1) ,( 'b' , 4) ,( 'c' , 4)),4)val accum1=spark.sparkContext.collectionAccumulator[String]("a")list1.foreachPartition(x=> accum1.add("123"))println(accum1.value)
- 广播变量
val temp=List(1,2,2,3,4)val broad1=spark.sparkContext.broadcast(temp)list1.foreachPartition(x=> println(broad1.value))
broadcast:通过调用SparkContext的broadcast()方法,来针对某个变量创建广播变量。然后在算子的函数内,使用到广播变量时,每个节点只会拷贝一份副本了。每个节点可以使用广播变量的value()方法获取值。记住,广播变量,是只读的。
Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能。但是确给我们提供了多个task对一个变量并行操作的功能。但是task只能对Accumulator进行累加操作,不能读取它的值。只有Driver程序可以读取Accumulator的值。
参考
5.写入数据
总结
spark离线开发王者