AD FS提供简化安全的身份联合验证和Web SSO。
ADFS和Azure AD O365联合起来的话,用户就可以拿本地的凭据来访问云上的所有资源。所以,ADFS就将本地资源和云上资源整合起来,至关重要。
ADFS部署在Azure上有以下有点:
- 高可用:因为有Azure Availability Set, 可以提高高可用性
- 容易扩容
- 跨地理冗余
- 容易管理
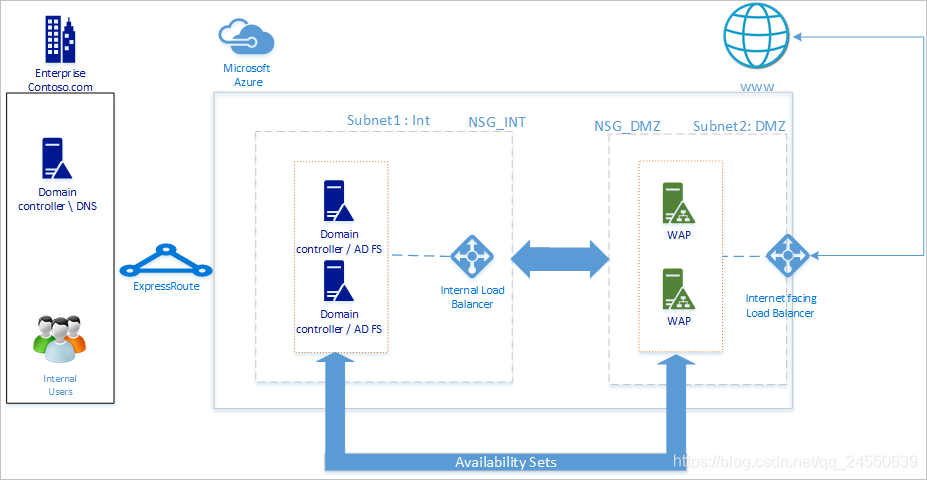
-
DC/ADFS:如果只有不到1000个用户ADFS角色可以直接部署在DC上。如果不想让ADFS影响DC的性能或者用户多于1000个,这样的话就要单独不部署一个ADFS
Server。 -
WAP(Web Application
Proxy)如果有外网用户想要访问,就必须要部署WAP,WAP要部署在DMZ外围网中。 -
DMZ:外围网,WAP部署在此。
-
负载平衡:在ADFS server 和WAP前面都要放置负载平衡器
-
可用性集:就是给相似的工作负载部署多台虚机,这样提高可用性。
-
存储账户:建议有两个存储账户,如果只有一个存储账户的话,很容易有单点故障。
-
网络分割:WAP要部署在外围网中,必须要把Vnet分为两个子网,然后把WAP部署在其中一个隔离的子网中。这个隔离用NGS network group security 来设置,设置两个子网中的通信限制。
用Azure Traffic Manager来部署ADFS跨地理位置的高可用部署
Azure Traffic Manager用来实现ADFS跨地理位置的高可用,通过用路由的方法来满足需求。
跨地理位置的高可用可以让ADFS可以:
- 可以克服单点故障
- 性能提高
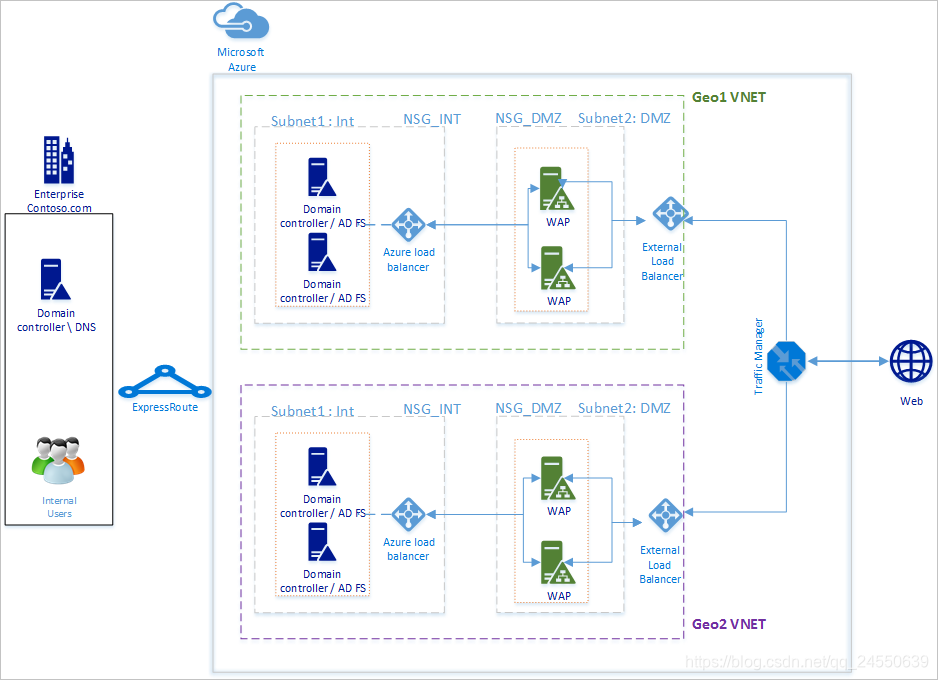
上图和Azure ADFS 没太大差别,就是拓展了另一个地理区域。
有以下几点需要考虑:
- 虚拟网络: 第二个地理区域需要重新建一个新的Vnet。
- DC和新地理位置的ADFS server: 建议在新的地理位置的部署自己的DC,这样就不用跑老远去找遥远的DC去进行验证,这样慢、性能差。
- 存储账户:新地儿要建立一个新的存储账户
- NSG:一个地儿的NSG不能用在新地儿,所以要在新地方重新创建一个差不多的NSG
- Azure Traffic Manager: Azure Traffic Manager把流量全球范围内进行分发, Azure Traffic Manager工作在DNS级别,DNS将客户端流量转去全球分布的终端点,这样客户端就直接和终端点链接,可以自定义不同的路由方式,权重,优先级,从而来自定义来满足自己的需求。
- 两个区域内V-net和V-net之间的连接:不需要建立虚拟网络之间的连接,因为每个虚拟网络可以访问自己的DC,有自己的ADFS、WAP,所以联合身份验证在没有虚拟网络连接的区域之间也可以正常工作。