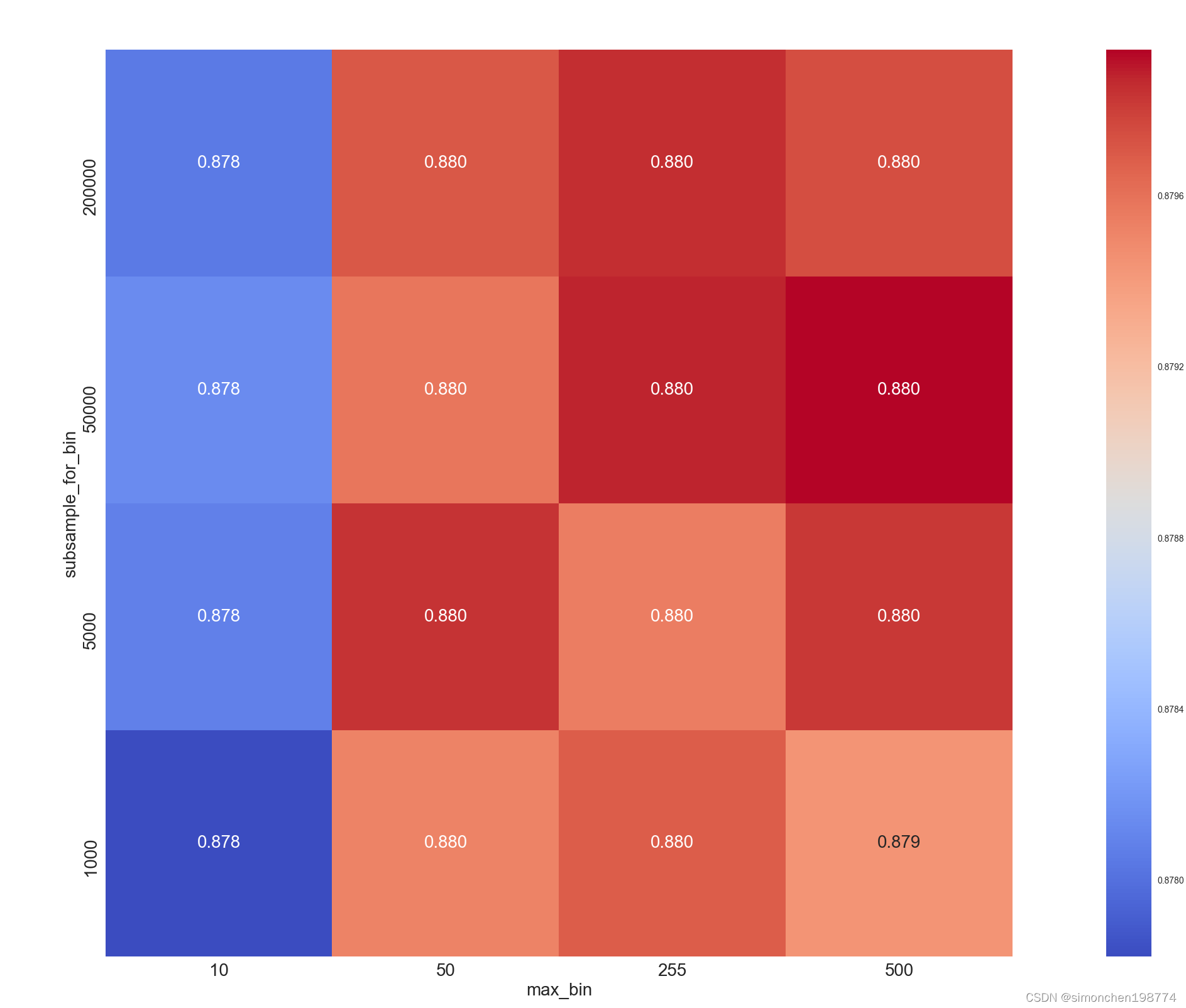
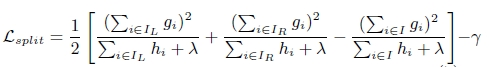下午看廖雪峰的Python2.7教程,看到 字符串和编码 一节,有一点感受,结合 崔庆才的Python博客 ,把这种感受记录下来:
ASCII码:是用一个字节(8bit, 0-255)中的127个字母表示大小写字母,数字和一些符号.主要用来表示现代英语和西欧语言。
所以处理中文就出现问题了,因为中文处理至少需要两个字节,所以中国制定了GB2312。
所以,各国制定了各国的标准。日本制定了Shift_JIS,韩国制定了Euc-kr。。。那么,乱码就来了。
为了统一,Unicode诞生了。统一码把所有语言都统一到一套编码里。解决了乱码问题,但是存储和传输效率低下的问题又来了。
因为ASCII编码是1个字节,而Unicode编码通常是2个字节。你表示一个英文字母一个字节就够了,但是Unicode却不得不用两个字节来表示(另一个字节补0)。
为了节约,出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间(ASCII码可以看成是UTF-8的一部分,所以大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作)。
现在如果我要用Notepad编辑一个python的脚本,我打开文件的过程中,内存中就开辟了一段空间,来临时存储我保存的代码,在计算机内存中,统一使用Unicode编码。
所以我写的中文字符串,要在前面加u表示是Unicode编码的字符串。
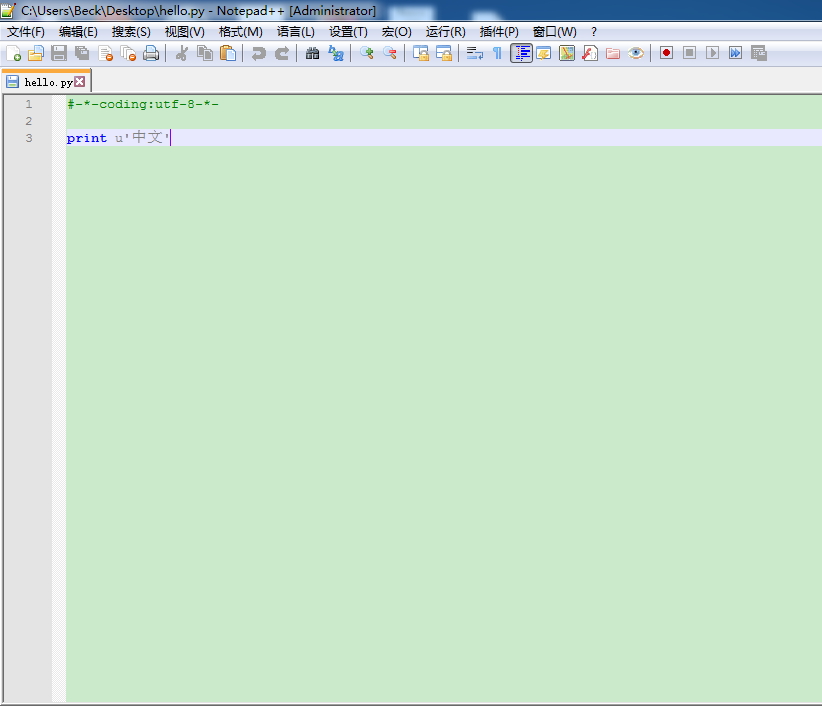
静觅博客中也是:

但是为什么有时候,我们要用到decode('utf-8'),再结合静觅博客来看:
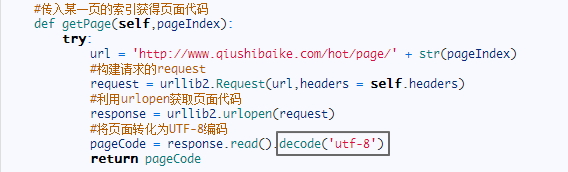
因为糗事百科的服务器发送给客户端(也就是浏览器)的响应的编码就是‘UTF-8':
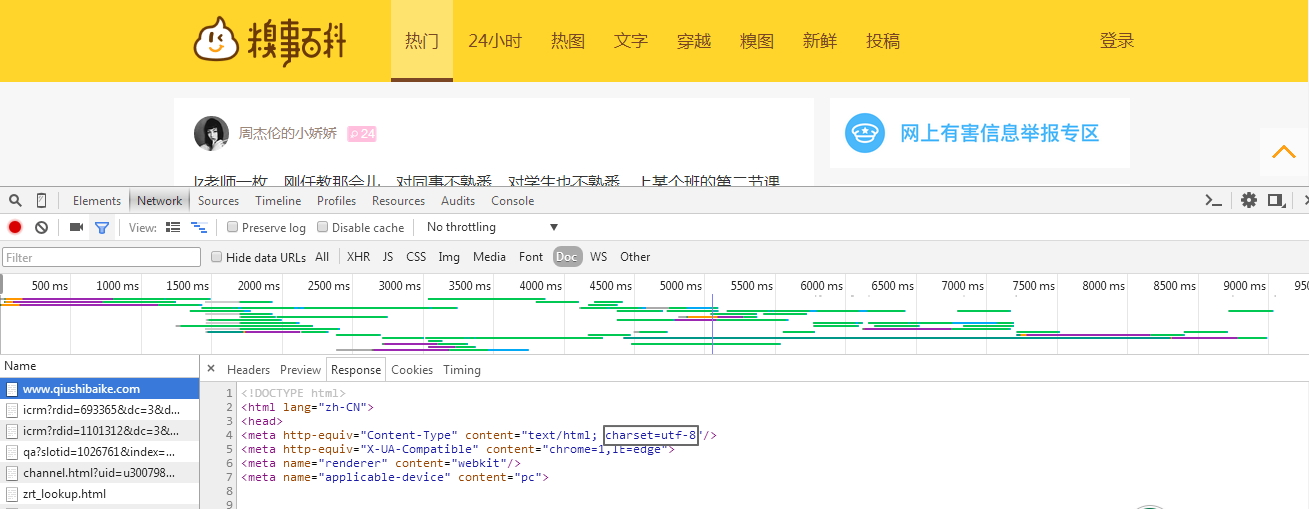

为了在文本编辑(读取文本)时,内存中需要Unicode编码,所以用decode('utf-8')解码,把UTF-8转化为Unicode编码(同理,encode('utf-8')是把Unicode转化为UTF-8编码)。
当保存文本到保存到硬盘或者需要传输的时候,就转换为UTF-8编码,所以我们需要在python脚本开头定义#-*-coding:utf-8-*-

图片来源
廖雪峰的官方网站:https://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001386819196283586a37629844456ca7e5a7faa9b94ee8000
静觅 崔庆才的个人博客:http://cuiqingcai.com/990.html