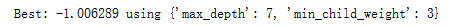1.直接调用LightGBM内嵌的cv寻找最佳的参数n_estimators(弱分类器数目)
Otto商品分类数据
导入必要模型import lightgbm as lgbm
import pandas as pd
import numpy as np
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import log_loss
from matplotlib import pyplot
import seaborn as sns
%matplotlib inline#读取数据
dpath = './logistic/'
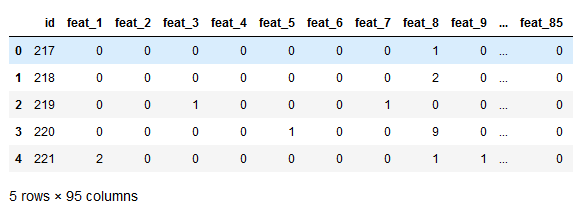
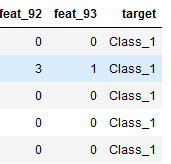
train = pd.read_csv(dpath + "Otto_train_test.csv")
train.head()
Variable Identification
选择该数据集是因为该数据特征单一,我们可以在特征工程方面少做些工作,集中精力放在参数调优上;
Target分布,看看各类样本分布是否均衡sns.countplot(train.target)
pyplot.xlabel('target')
pyplot.ylabel('Number of occurrences')
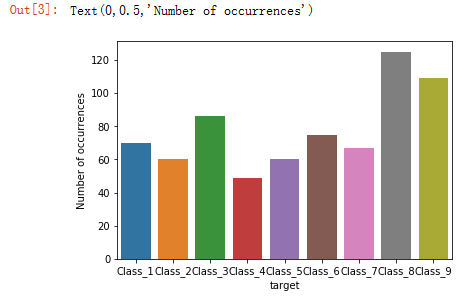
每类样本分布不是很均匀
特征编码# 将类别字符串变成数字
y_train = train['target'] #形式为Class_x
y_train = y_train.map(lambda s: s[6:])
y_train = y_train.map(lambda s: int(s) - 1)#将类别的形式由Class_x变为0-8之间的整数
train = train.drop(["id" , "target"] , axis = 1)
X_train = np.array(train)
默认参数,此时学习率为0.1,比较大,观察弱分类数目的大致范围(采用默认参数配置,看看模型是过拟合还是欠拟合)#直接调用lightgbm内嵌的交叉验证(cv),可对连续的n_estimators参数进行快速交叉验证
#而GridSearchCV只能对有限个参数进行交叉验证,且速度相对较慢
import json
def modelfit(params , alg , X_train , y_train , early_stopping_rounds=10):
lgbm_params = params.copy()
lgbm_params['num_class'] = 9
lgbm_params.pop('silent');
lgbmtrain = lgbm.Dataset(X_train , y_train , silent=True)
#num_boost_round为弱分类器数目,下面的代码参数里因为已经设置了early_stopping_rounds
#即性能未提升的次数超过过早停止设置的数值,则停止训练
cv_result = lgbm.cv(lgbm_params , lgbmtrain , num_boost_round=10000 , nfold=5 , stratified=True , shuffle=True , metrics='multi_logloss' , early_stopping_rounds=early_stopping_rounds , show_stdv=True , seed=0 )
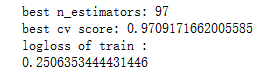
print('best n_estimators:' , len(cv_result['multi_logloss-mean']))
print('best cv score:' , cv_result['multi_logloss-mean'][-1])
#cv_result.to_csv('lgbm1_nestimators.csv' , index_label='n_estimators')
json.dump(cv_result , open('lgbm_1.json' , 'w'))
#采用交叉验证得到的最佳参数n_estimators,训练模型
alg.set_params(n_estimators=len(cv_result['multi_logloss-mean']))
alg.fit(X_train , y_train)
#Predict training set:
train_predprob = alg.predict_proba(X_train)
logloss = log_loss(y_train , train_predprob)
#Print model report:
print("logloss of train :")
print (logloss)params = {'boosting_type': 'gbdt',
'objective': 'multiclass',
'nthread': -1,
'silent': True,#是否打印信息,默认False
'learning_rate': 0.1,
'num_leaves': 80,
'max_depth': 5,
'max_bin': 127,
'subsample_for_bin': 50000,
'subsample': 0.8,
'subsample_freq': 1,
'colsample_bytree': 0.8,
'reg_alpha': 1,
'reg_lambda': 0,
'min_split_gain': 0.0,
'min_child_weight': 1,
'min_child_samples': 20,
'scale_pos_weight': 1}
lgbm1 = lgbm.sklearn.LGBMClassifier(num_class=9 , n_estimators=1000 , seed=0 , **params)
modelfit(params , lgbm1 , X_train , y_train)
 #cv_result = pd.read_json('lgbm_1.json')
#cv_result = pd.read_json('lgbm_1.json')
2.调整树的参数:max_depth & min_child_weight
(参数的步长为1;下一步是在最佳参数周围,将步长降为0.5,进行精细调整)
第一轮参数调整得到的n_estimators最优值(97),其余参数继续默认值
用交叉验证评价模型性能时,用scoring参数定义评价指标。评价指标是越高越好,因此用一些损失函数当评价指标时,需要再加负号,如neg_log_loss,neg_mean_squared_error详见sklearn文档:http://scikit-learn.org/stable/modules/model_evaluation.html#log-loss#max_depth 建议3-10,min_child_weight=1 / sqrt(ratio_rare_event) = 5.5
max_depth = range(6 , 10 , 1)
min_child_weight = range(1 , 5 , 1)
param_test2_1 = dict(max_depth=max_depth , min_child_weight=min_child_weight)
param_test2_1
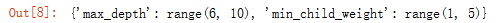 #prepare cross validation
#prepare cross validation
from sklearn.model_selection import StratifiedKFold
kfold = StratifiedKFold(n_splits=5 , shuffle=True , random_state=3)params2 = {'boosting_type': 'gbdt',
'objective': 'multiclass',
'nthread': -1,
'silent': True,
'learning_rate': 0.1,
'num_leaves': 80,
'max_depth': 5,
'max_bin': 127,
'subsample_for_bin': 50000,
'subsample': 0.8,
'subsample_freq': 1,
'reg_alpha': 1,
'reg_lambda': 0,
'min_split_gain': 0.0,
'min_child_weight': 1,
'min_child_samples': 20,
'scale_pos_weight': 1}
lgbm2_1 = lgbm.sklearn.LGBMClassifier(num_class=9 , n_estimators=97 , seed=0 , **params2)
#GridSearchCV参数说明:(学习器 ,参数范围 ,评价指标 , cpu核心的使用数(-1为并行,使用全部的核) , 交叉验证一共多少折)
gsearch2_1 = GridSearchCV(lgbm2_1 , param_grid=param_test2_1 , scoring='neg_log_loss' , n_jobs = -1 , cv = kfold)
gsearch2_1.fit(X_train , y_train)
gsearch2_1.grid_scores_ , gsearch2_1.best_params_ , gsearch2_1.best_score_
 gsearch2_1.cv_results_{'mean_fit_time': array([0.76969552, 1.18755584, 1.14692926, 1.10005512, 1.48944592,
gsearch2_1.cv_results_{'mean_fit_time': array([0.76969552, 1.18755584, 1.14692926, 1.10005512, 1.48944592,
1.59057088, 1.21840544, 1.12013426, 1.28924704, 1.24068198,
1.15943041, 1.1189312 , 1.28796062, 1.25322876, 1.47233396,
1.35659175]),
'std_fit_time': array([0.37958056, 0.05846628, 0.04375209, 0.00765705, 0.22566673,
0.07160577, 0.06428244, 0.00558019, 0.01377198, 0.01874956,
0.03336754, 0.01611188, 0.00576565, 0.02922022, 0.20602699,
0.26722857]),
'mean_score_time': array([0.00937595, 0.00937572, 0.009376 , 0.00624833, 0.00845222,
0.00660481, 0.00760546, 0.00660472, 0.00312538, 0.0093771 ,
0.00312519, 0.00745149, 0.00600429, 0.00920706, 0.01297846,
0.00625076]),
'std_score_time': array([7.65543414e-03, 7.65523945e-03, 7.65547306e-03, 7.65261232e-03,
7.10425215e-03, 3.93223963e-03, 1.96087089e-03, 3.66865115e-03,
6.25076294e-03, 7.65636865e-03, 6.25038147e-03, 7.02576503e-03,
4.10190833e-07, 2.22884135e-03, 3.48157103e-03, 7.65558986e-03]),
'param_max_depth': masked_array(data=[6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8, 8, 9, 9, 9, 9],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False],
fill_value='?',
dtype=object),
'param_min_child_weight': masked_array(data=[1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False],
fill_value='?',
dtype=object),
'params': [{'max_depth': 6, 'min_child_weight': 1},
{'max_depth': 6, 'min_child_weight': 2},
{'max_depth': 6, 'min_child_weight': 3},
{'max_depth': 6, 'min_child_weight': 4},
{'max_depth': 7, 'min_child_weight': 1},
{'max_depth': 7, 'min_child_weight': 2},
{'max_depth': 7, 'min_child_weight': 3},
{'max_depth': 7, 'min_child_weight': 4},
{'max_depth': 8, 'min_child_weight': 1},
{'max_depth': 8, 'min_child_weight': 2},
{'max_depth': 8, 'min_child_weight': 3},
{'max_depth': 8, 'min_child_weight': 4},
{'max_depth': 9, 'min_child_weight': 1},
{'max_depth': 9, 'min_child_weight': 2},
{'max_depth': 9, 'min_child_weight': 3},
{'max_depth': 9, 'min_child_weight': 4}],
'split0_test_score': array([-1.1095002 , -1.10093944, -1.11068332, -1.12581965, -1.10990165,
-1.11763534, -1.10955467, -1.12785983, -1.1136691 , -1.11892955,
-1.11057671, -1.1226148 , -1.11458382, -1.11135853, -1.11057671,
-1.1226148 ]),
'split1_test_score': array([-0.98243464, -0.98239904, -0.99364646, -0.98426716, -0.9881632 ,
-0.99487678, -0.9818681 , -0.98405452, -0.99288509, -0.99638123,
-0.98479146, -0.9849888 , -0.9911613 , -0.98937118, -0.98431879,
-0.98514942]),
'split2_test_score': array([-1.00126664, -1.01613241, -1.00794652, -1.00294229, -1.01308502,
-1.00274243, -1.00408767, -1.01815955, -1.01927451, -1.01020295,
-1.01639531, -1.00958675, -1.0077591 , -1.00663798, -1.00333139,
-1.00958675]),
'split3_test_score': array([-1.01232842, -1.02250884, -1.0030879 , -1.01277954, -1.01514669,
-1.01574748, -0.99794459, -1.00521546, -1.01651413, -1.02306997,
-1.00166031, -1.00335696, -1.01769405, -1.01429272, -1.01154655,
-1.00335696]),
'split4_test_score': array([-0.9463619 , -0.94191154, -0.9392704 , -0.93742344, -0.93413134,
-0.94852178, -0.93567824, -0.93623709, -0.93590173, -0.92139132,
-0.93674013, -0.93661415, -0.93260223, -0.92303758, -0.93283531,
-0.9423284 ]),
'mean_test_score': array([-1.01080394, -1.01318863, -1.01139132, -1.01314344, -1.01255294,
-1.01635726, -1.00628856, -1.01480885, -1.01612362, -1.01453347,
-1.01049274, -1.01192524, -1.01324849, -1.00944898, -1.00899433,
-1.01308246]),
'std_test_score': array([0.05450906, 0.05262808, 0.05568242, 0.06236204, 0.05702129,
0.05579946, 0.05724072, 0.06336497, 0.05748917, 0.06324661,
0.05705526, 0.06132002, 0.05889466, 0.06050685, 0.05798539,
0.05995049]),
'rank_test_score': array([ 5, 11, 6, 10, 8, 16, 1, 14, 15, 13, 4, 7, 12, 3, 2, 9]),
'split0_train_score': array([-0.22483986, -0.23538244, -0.25604178, -0.28157385, -0.22259988,
-0.23411482, -0.25594814, -0.28056406, -0.22186875, -0.23392338,
-0.2555759 , -0.28162284, -0.2221092 , -0.23315246, -0.2555759 ,
-0.28162284]),
'split1_train_score': array([-0.2345002 , -0.24488599, -0.26307177, -0.28744509, -0.23171022,
-0.24164092, -0.26087359, -0.2863303 , -0.23128738, -0.24139842,
-0.26197134, -0.28735066, -0.23066162, -0.24099122, -0.26102265,
-0.28680798]),
'split2_train_score': array([-0.23258495, -0.24242771, -0.26181423, -0.2903389 , -0.22922374,
-0.23886099, -0.25941357, -0.29098331, -0.2285759 , -0.23862621,
-0.26003545, -0.28989784, -0.22866432, -0.239149 , -0.25920104,
-0.28989784]),
'split3_train_score': array([-0.22121767, -0.23215098, -0.25292121, -0.28210613, -0.22001708,
-0.2292082 , -0.25010069, -0.28048109, -0.21965813, -0.22997443,
-0.25059737, -0.28105454, -0.22053079, -0.22889495, -0.24872066,
-0.28105454]),
'split4_train_score': array([-0.23422352, -0.24482203, -0.26375801, -0.29152319, -0.23042566,
-0.24206089, -0.260888 , -0.29126432, -0.23031942, -0.24173811,
-0.25993661, -0.28903779, -0.22975252, -0.2404106 , -0.26083158,
-0.29096251]),
'mean_train_score': array([-0.22947324, -0.23993383, -0.2595214 , -0.28659743, -0.22679532,
-0.23717717, -0.2574448 , -0.28592462, -0.22634192, -0.23713211,
-0.25762334, -0.28579274, -0.22634369, -0.23651964, -0.25707037,
-0.28606914]),
'std_train_score': array([0.00542477, 0.00521394, 0.00427741, 0.00410824, 0.00462124,
0.00488863, 0.00409058, 0.00474626, 0.00468937, 0.00454263,
0.00408976, 0.00373223, 0.00418021, 0.00472275, 0.00460995,
0.00410038])}#用交叉验证得到的最佳max_depth和min_child_weight进行训练及预测
params2 = {'boosting_type': 'gbdt',
'objective': 'multiclass',
'nthread': -1,
'silent': True,#是否打印信息,默认False
'learning_rate': 0.1,
'num_leaves': 80,
'max_depth': 7,#第二次交叉验证得到的参数
'max_bin': 127,
'subsample_for_bin': 50000,
'subsample': 0.8,
'subsample_freq': 1,
'colsample_bytree': 0.8,
'reg_alpha': 1,
'reg_lambda': 0,
'min_split_gain': 0.0,
'min_child_weight': 3,#第二次交叉验证得到的参数
'min_child_samples': 20,
'scale_pos_weight': 1}
lgbm2 = lgbm.sklearn.LGBMClassifier(num_class=9 , n_estimators=97 , seed=0 , **params2)
lgbm2.fit(X_train , y_train)
#Predict training set:
train_predprob = lgbm2.predict_proba(X_train)
logloss = log_loss(y_train , train_predprob)
#Print model report:
print("logloss of train :")
print (logloss)

注:因数据是原来6万多的基础上,随便在各个分类找的一共701条数据,此处交叉验证后得到的最佳参数的性能还没原来的好,lightgbm处理数据的颗粒度比XGBoost大,所以在数据很少的情况下,性能比不上XGBoost;#summarize results
print("Best: %f using %s" % (gsearch2_1.best_score_ , gsearch2_1.best_params_))
test_means = gsearch2_1.cv_results_['mean_test_score']
test_stds = gsearch2_1.cv_results_['std_test_score']
train_means = gsearch2_1.cv_results_['mean_train_score']
train_stds = gsearch2_1.cv_results_['std_train_score']
pd.DataFrame(gsearch2_1.cv_results_).to_csv('my_preds_maxdepth_min_child_weight.csv')
# plot results
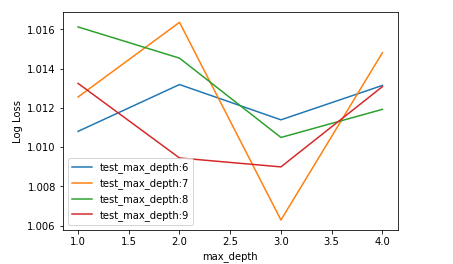
test_scores = np.array(test_means).reshape(len(max_depth) , len(min_child_weight))
train_scores = np.array(train_means).reshape(len(max_depth) , len(min_child_weight))
for i,value in enumerate(max_depth):
pyplot.plot(min_child_weight , -test_scores[i] , label='test_max_depth:' + str(value))
#for i,value in enumerate(min_child_weight):
#pyplot.plot(max_depth , train_scores[i] , label='train_min_child_weight:' + str(value))
pyplot.legend()
pyplot.xlabel('max_depth')
pyplot.ylabel('Log Loss')
pyplot.savefig('max_depth_vs_min_child_weight_1.png')