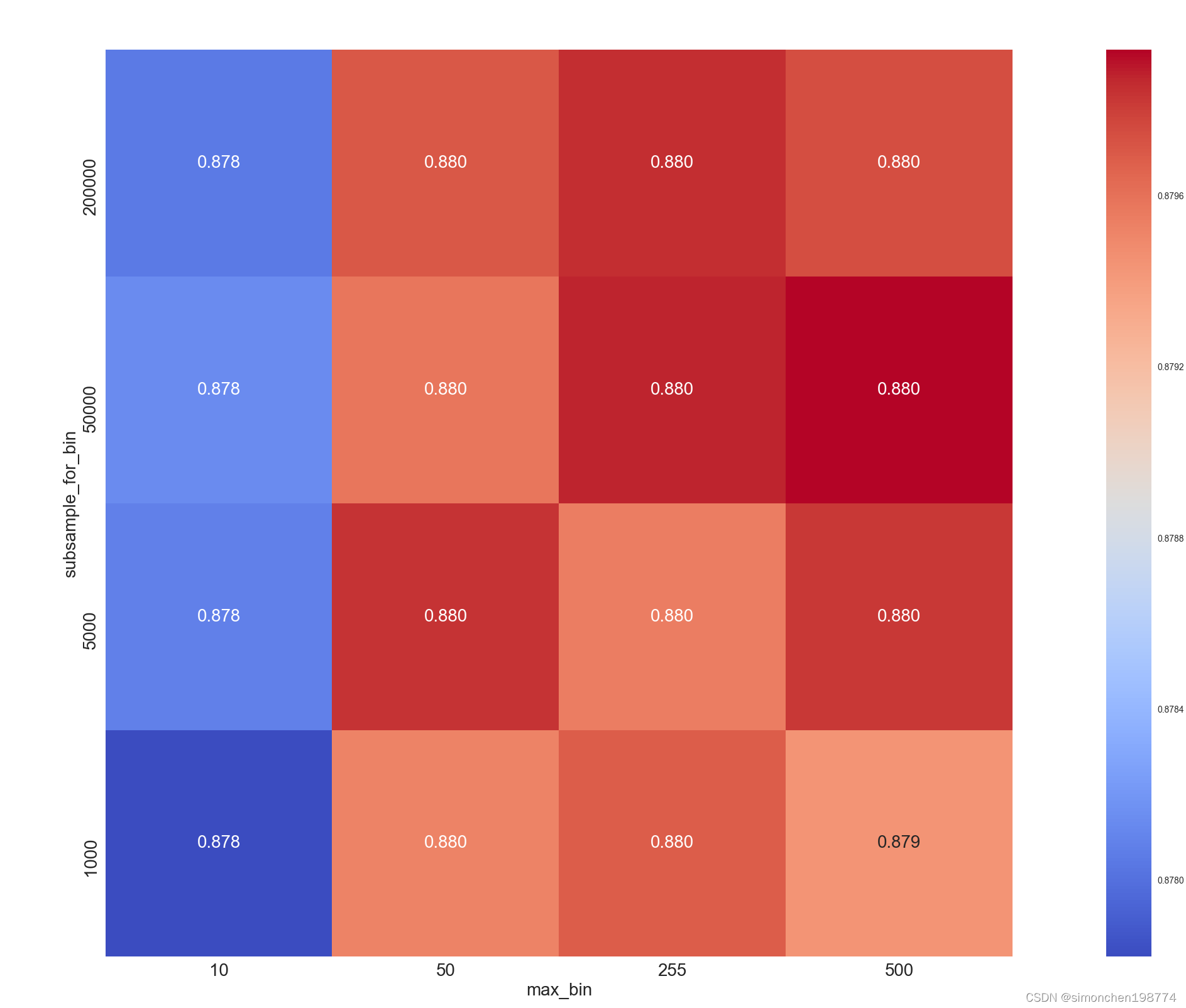
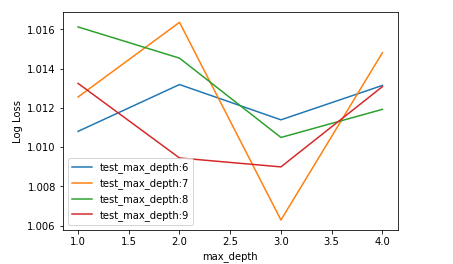
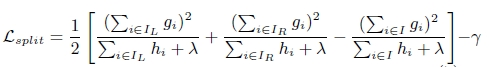算法开发
该深度卷积神经网络以原始心电图数据(以200Hz或每秒200个样本为样本)作为输入,并且每256个样本(或每1.28秒)生成一个预测,我们称之为输出间隔。网络仅以原始心电图样本为输入,网络架构有34层:为了使这种网络的优化变得可处理,采用类似残差网络的架构进行快捷连接。该网络由16个残差块组成,每个块有两个卷积层。卷积层的过滤宽度为16和 32 ∗ 2 K 32*2^K 32∗2K过滤器,其中K是超参,从0开始,每四个残差块增加一个。每个备用残差块对其输入进行子采样2次。在每个卷积层之前,应用批量归一化和Relui激活,采用预激活块设计。由于这种预激活块结构,网络的第一层和最后一层是特殊的。另外还在卷积层之间和非线性之后应用Dropout,概率为0.2。最终完全连接的softmax层输出12类心率时长的概率。网络是从头训练的,随机初始化权重。使用Adam optimizer,默认参数为β1= 0.9,β2= 0.999,minibatch大小为128。学习率初始化为1×10-3,并且当连续两个epoch的训练损失没有改观时其降低10倍。通过grid search和手动调整的组合来选择网络架构和优化算法的超参数。对于该体系结构,主要搜索的超参数与为卷积层的数量,卷积滤波器的大小和数量,以及残差连接的使用。实验中发现,一旦模型的深度超过八层,残差连接就很有用。论文还尝试了RNN,包括LSTM和BiRNN,但发现准确性没有提高,运行时间却大幅增加;因此,因此文章抛弃了这类模型。
仿真实现
源代码

原来的网络结构是用pytorch实现的,而且结构理解比较困难,这里尝试用keras实现。
config.json
{"conv_subsample_lengths": [1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2],"conv_filter_length": 16,"conv_num_filters_start": 32,"conv_init": "he_normal","conv_activation": "relu","conv_dropout": 0.2,"conv_num_skip": 2,"conv_increase_channels_at": 4,"learning_rate": 0.001,"batch_size": 32,}
network
def model_build(params):def zeropad(x):y = K.zeros_like(x)return K.concatenate([x, y], axis=2)def zeropad_output_shape(input_shape):shape = list(input_shape)assert len(shape) == 3shape[2] *= 2return tuple(shape)def type_1(input_data, n_filters, filter_size, max_pool_size,index):x = Conv1D(n_filters, filter_size, strides=1, padding='same', name='type_1' + '_' + 'conv_1'+str(index), kernel_initializer=params["conv_init"])(input_data)x = BatchNormalization(name='type_1'+ '_' + 'BN_1'+str(index))(x)x = Activation('relu', name='type_1'+ '_' + 'relu_1'+str(index))(x)x = Dropout(rate=0.1)(x)x = Conv1D(n_filters, filter_size, strides=1, padding='same', name='type_1'+ '_' + 'conv_2'+str(index),kernel_initializer=params["conv_init"])(x)shortcut = MaxPooling1D(pool_size=max_pool_size,name='short'+ '_' + 'max_pooling_'+str(index))(input_data)x = add([x, shortcut], name='type_1' + '_' + 'add'+str(index))return xdef type_2(input_data, n_filters, filter_size, max_pool_size,index):x = BatchNormalization(name='type_2'+ '_' + 'BN_1'+str(index))(input_data)x = Activation('relu', name='type_2'+ '_' + 'relu_1'+str(index))(x)x = Conv1D(n_filters, filter_size, strides=max_pool_size, padding='same', name='type_2'+ '_' + 'conv_1'+str(index),kernel_initializer=params["conv_init"])(x)x = BatchNormalization(name='type_2'+ '_' + 'BN_2'+str(index))(x)x = Activation('relu', name='type_2'+ '_' + 'relu_2'+str(index))(x)x = Dropout(rate=0.1)(x)x = Conv1D(n_filters, filter_size, strides=1, padding='same', name='type_2'+ '_' + 'conv_2'+str(index),kernel_initializer=params["conv_init"])(x)shortcut = MaxPooling1D(pool_size=max_pool_size,padding='same',name='short'+ '_' + 'max_pooling_'+str(index))(input_data)if index in (5,9,13):shortcut = Lambda(zeropad, output_shape=zeropad_output_shape)(shortcut)x = add([x, shortcut], name='type_2' + str(index) + '_' + 'add')return xinput_ecg = Input(shape=(5000, 12), name='input')x = Conv1D(filters=32, kernel_size=16, strides=1, padding='same', kernel_initializer=params["conv_init"], name='conv_1')(input_ecg)x = BatchNormalization(name='BN_1')(x)x = Activation('relu', name='relu_1')(x)x = type_1(x, n_filters=params["conv_num_filters_start"], filter_size=params["conv_filter_length"], max_pool_size=1,index=1) x = type_2(x, n_filters=params["conv_num_filters_start"], filter_size=params["conv_filter_length"], max_pool_size=2,index=2)x = type_2(x, n_filters=params["conv_num_filters_start"], filter_size=params["conv_filter_length"], max_pool_size=1,index=3)x = type_2(x, n_filters=params["conv_num_filters_start"], filter_size=params["conv_filter_length"], max_pool_size=2,index=4)x = type_2(x, n_filters=params["conv_num_filters_start"]*2, filter_size=params["conv_filter_length"], max_pool_size=1,index=5)x = type_2(x, n_filters=params["conv_num_filters_start"]*2, filter_size=params["conv_filter_length"], max_pool_size=2,index=6)x = type_2(x, n_filters=params["conv_num_filters_start"]*2, filter_size=params["conv_filter_length"]//2, max_pool_size=1,index=7)x = type_2(x, n_filters=params["conv_num_filters_start"]*2, filter_size=params["conv_filter_length"]//2, max_pool_size=2,index=8)x = type_2(x, n_filters=params["conv_num_filters_start"]*4, filter_size=params["conv_filter_length"]//2, max_pool_size=1,index=9)x = type_2(x, n_filters=params["conv_num_filters_start"]*4, filter_size=params["conv_filter_length"]//2, max_pool_size=2,index=10)x = type_2(x, n_filters=params["conv_num_filters_start"]*4, filter_size=params["conv_filter_length"]//2, max_pool_size=1,index=11)x = type_2(x, n_filters=params["conv_num_filters_start"]*4, filter_size=params["conv_filter_length"]//2, max_pool_size=2,index=12)x = type_2(x, n_filters=params["conv_num_filters_start"]*8, filter_size=params["conv_filter_length"]//2, max_pool_size=1,index=13)x = type_2(x, n_filters=params["conv_num_filters_start"]*8, filter_size=params["conv_filter_length"]//2, max_pool_size=2,index=14)x = type_2(x, n_filters=params["conv_num_filters_start"]*8, filter_size=params["conv_filter_length"]//2, max_pool_size=1,index=15)x = type_2(x, n_filters=params["conv_num_filters_start"]*8, filter_size=params["conv_filter_length"]//2, max_pool_size=2,index=16)x = BatchNormalization(name='BN_2')(x)x = Activation('relu', name='relu_2')(x) #x = TimeDistributed(Dense(5, activation='softmax', name='output'))(x) x = GlobalAveragePooling1D(name='average_pooling')(x)#x = MaxPooling1D(name='max_pooling')(x)#x = Concatenate(axis=1)([x1, x2])#x = Flatten(name='flatten')(x)#全连接层#x = Dense(64,kernel_regularizer=l2(0.01), name='FC1')(x)#隐藏层#x = Activation('relu', name='Dense_relu_1')(x)#x = Dropout(rate=0.2)(x)x = Dense(12, activation='softmax', name='output')(x)model = Model(inputs=input_ecg, outputs=x)return model