Contents
- 计算机系统概论(贯穿本书)
- 计算机的发展及应用(非重点)
- 系统总线
- 存储器
- 高速缓冲存储器
- 计算机的运算方法
- 指令系统
链接 【超详细】计算机组成原理总结及思维导图.
链接 计算机组成原理知识点.
链接 计算机组成原理----思维导图.
链接 【重学计算机】计算机组成原理.
链接 前引_计算机科学导论.
链接 哈工大刘宏伟老师讲课视频.
计算机系统概论(贯穿本书)
- 计算机系统简介
- 计算机的基本组成
- 计算机硬件的主要指标
现在计算机主要是 数字电子计算机
- 计算机组成原理,讲的就是计算机硬件系统的逻辑实现
计算机系统,包括 硬件 + 软件
软件分为两大类:系统软件 和 应用软件
系统软件:又称系统程序,为了使系统资源得到合理调度,高效运行
- 标准程序库、语言处理程序(汇编程序、编译程序)、操作系统(批处理、分时、实时)、服务程序(诊断、调试、连接)、数据库管理系统、网络软件等
应用软件 (通用软件、专用软件):用户根据任务需要编制的程序
层次结构:
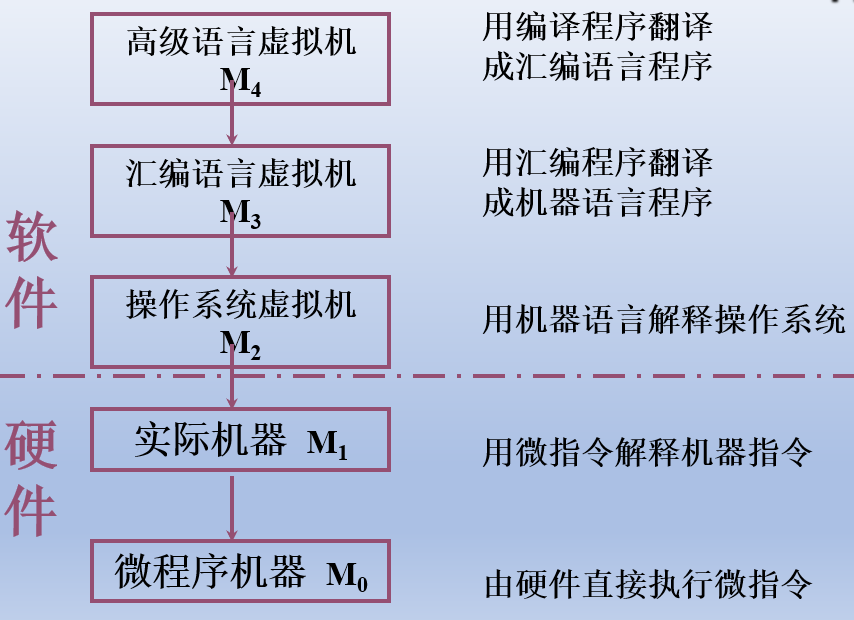
指令 = 操作码 + 地址码
汇编语言 用助记符代替指令,是符号语言,汇编语言指令与机器指令一一对应
高级语言,编写时硬件不相关,开发效率高,可移植性强,运行效率低 (需要转换成低级语言)
翻译程序,有两种 编译程序 和 解释程序
编译程序:将源程序一次性全翻译成机器语言程序(目标程序),再执行机器语言程序
解释程序:特点是翻译一次执行一次,即使下一次重复执行该语句时,也必须重新翻译
- 微指令,指令分解而成,微指令构成的 微程序 = 一条指令
程序,包括运算的全部步骤
指令,是程序中的单个步骤
- 例:计算程序包括:
加法指令、乘法指令、取数指令、存数指令、打印指令、停机指令
冯诺依曼计算机,以运算器为中心
冯诺依曼机工作方式的基本特点是:按地址访问并顺序执行指令
现代计算机改进了一下,以存储器为中心
- 指令和数据以同等地位存于存储器中
有许多运算的结果是无法准确表示的,此时
迭代计算,直到相邻两次的计算差值满足用户的精度要求
例如 求Sin 20.2.18
主存 = 存储体 + MAR + MDR
存储体,若干个存储单元组成 (大楼)
- 存储单元,存放一串二进制代码 (房间),每个存储单元给一个地址 (房间号)
- 存储元件,一个二进制代码位 (床位), 有人为1,没人为0
- 存储字,存储单元中的二进制代码串 (房间中的信息),一个存储单元对应一个存储字
- 存储字长,存储字的长度,存储单元中二进制代码的位数 (床位数)
MAR,存储器地址寄存器 (Memory Address Rejister)
- 保存存储单元的地址,其位数反映存储单元的个数(若 n 位,对应 2n 个存储单元地址)
MDR,存储器数据寄存器 (Data)
-
保存要存入存储体中或刚从存储体中取出的数据,其位数反映存储字长(n 位,对应存储字长 n,因每次取出一个存储字)
-
在指令字长、存储字长、机器字长相等的情况下,
ACC = IR = X = MDR位数
PC = MAR位数;想想为什么 -
指令字长:一个指令字中包含的二进制位数
-
存储字长:已经介绍,是一个存储单元的二进制代码串的位数,存储字长通常 ≤ 机器字长,一般相等
-
机器字长:计算机 (CPU) 能直接处理的二进制数据的位数,通常与CPU寄存器位数有关
该字长越长,数的表示范围越大,计算精度越高 (若该字长过短,运算时一个运算数要拆开表示的话,也会影响计算机运算速度) 一般为 8位 16位 32位等
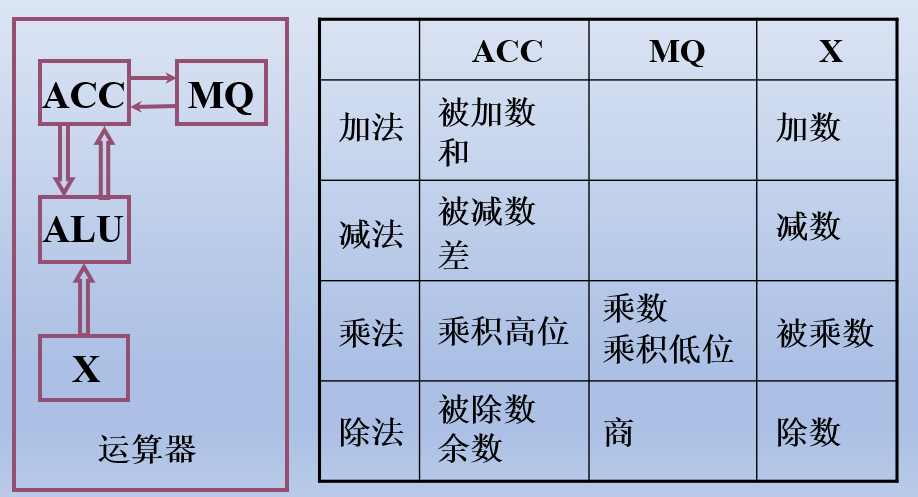
运算器 = X + ALU + ACC + MQ
这个运算器的结构只是课本模型机给出的,实际运算器中寄存器的数量根据不同情况设计
——————
ALU,(Arithmetic Logical Unit) 算术逻辑单元
- 运算器的核心,通常是组合电路,所以一般在其输入端有 两个寄存器
其中一个就是 ACC 累加器 (Accumulator),另一个是称为 X 的 数据寄存器; - 因为乘法得出的结果的长度是操作数的两倍,多出来的长度存放在 MQ 寄存器中,运算结果保存在 ACC 中
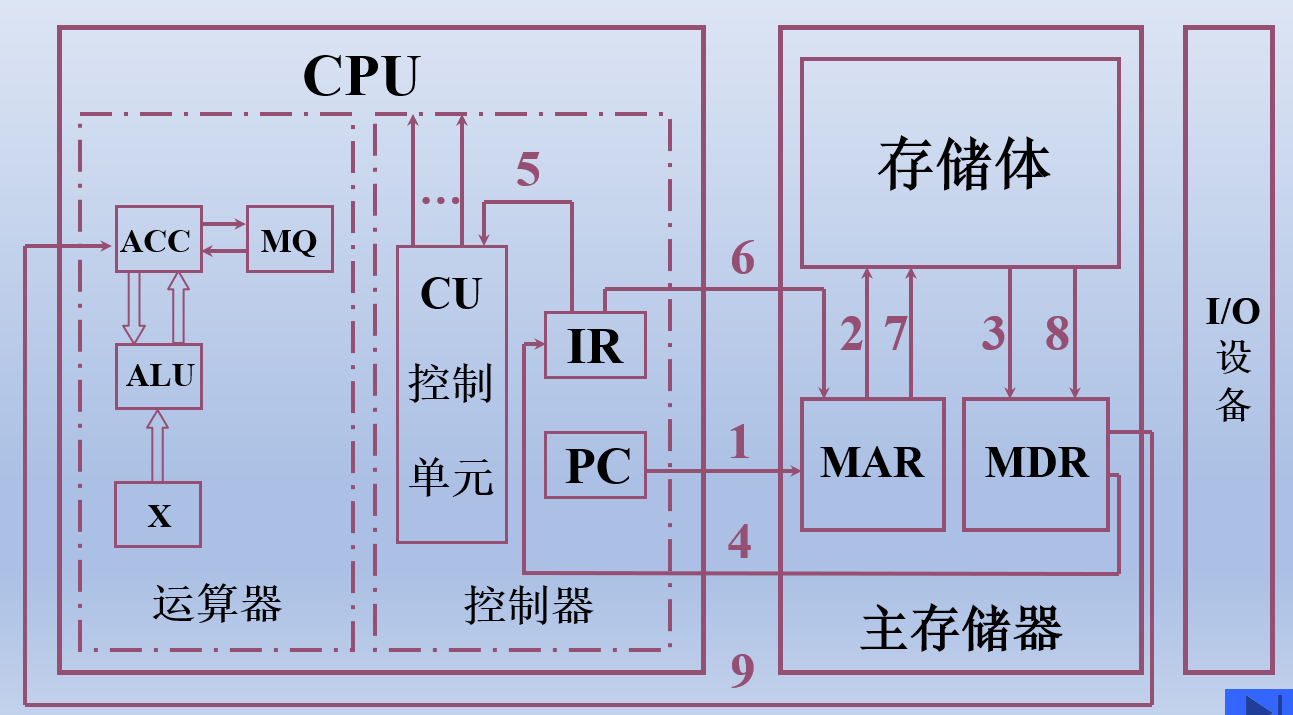
CPU和运算器的关系:CPU = 运算器 + 控制器
8086、286、386、奔腾、酷睿、I5等均指CPU
——————
乘法得出的结果一定是 一行为 被乘数,一行为 0
-
加法指令中有一个操作数的地址 M,另一个操作数在 ACC 中,
- 第一个操作:将地址 M 对应的数据 取出 到 X 中
第二个操作:在 ALU 中执行加法操作,操作数分别来自 ACC 和 X
第三个操作:结果保存至 ACC
- 第一个操作:将地址 M 对应的数据 取出 到 X 中
-
乘法指令的先后顺序,初态 被乘数在 ACC 中,
- 需要[ACC] → X,然后 0 → ACC,最后[X] × [MQ] → ACC // MQ (加中括号表示其中的数据)
由 控制器控制 操作执行顺序,在 ALU 中执行乘法操作
- 需要[ACC] → X,然后 0 → ACC,最后[X] × [MQ] → ACC // MQ (加中括号表示其中的数据)
控制器 = CU + IR + PC
功能:解释指令(包括 取出 分析 执行 等过程),保证指令的有序执行
——————
- CU,控制单元,发出控制信号
- IR,Instruction Register 指令寄存器,保存当前要执行的指令
- PC,Programming Counter 程序计数器,保存要执行指令的地址 (会自动 +1)
链接 见计算机科学导论第3章.
-
主机完成一条取数指令:
-
一个程序在计算机上的运行过程:(其中OP是指令的操作码字段,Ad是地址码字段)

如何区分从存储器中取出的是指令还是数据?二者是从不同阶段取出,以此区分 20.2.22
机器字长,
- CPU一次能处理数据的位数,通常与CPU中寄存器位数相等
为简化问题,模型机中存储字长也与之相等
运算速度,
- 主频一般与之成正比,核数也是,不过二者与运算速度没有直接关系
吉普森法,加权平均值,用指令执行速度衡量,分为指令的静态使用频率,动态使用频率
CPI,执行一条指令需要多少个时钟周期,越少越好
IPC,一个时钟周期能完成多少个指令,用于超流水线,超标量的计算机
MIPS,每秒执行百万条指令
从指令执行的角度衡量,指令执行是手段,目的还是完成算术或逻辑运算
FLOPS,每秒浮点运算次数,更直接
存储容量,
- 存放二进制信息的总位数,
主存容量,存储单元个数 × 存储字长 例如:1K × 8位
辅存容量,字节数表示,例如:80GB
计算机的发展及应用(非重点)
- 计算机的发展史
- 计算机的应用
- 计算机的展望
ENIAC(埃尼亚克🤐),给了冯诺依曼启发 1946-1955退役
没有存储器,5000次加法/秒,耗费48万,属军方
现代计算机产生的驱动力:需求,技术发展
计算机的各种更新换代:链接 计算机科学导论.
- IBM System / 360,50亿美金。。。,成功了,一个系列
计算机直接跨入高速,提出计算机系统结构,定义了软硬件交界面
微处理器芯片 1971,存储器芯片 1970;微型计算机
- Moore 定律,芯片上集成晶体管数量每三年翻一倍
起初 每台机器的机器语言都不同
- 汇编语言,面向机器,就是改01代码为符号
高级语言,面向问题
系统软件,语言处理程序、操作系统、数据库管理系统、网络软件……
开发周期长,制作成本昂贵,软件产品质量检测的特殊性
- 科学计算与数据处理:HPC(高性能计算机),建模
工业控制和实时控制:通过后者实现无人驾驶
网络技术:电子商务、网络教育、敏捷制造
虚拟现实,办公自动化,多媒体,人工智能,详见计算机科学导论
计算机要足够快,超级智能,谷歌大脑、百度大脑
-
芯片集成度,受物理极限制约;成本
-
光计算机;DNA生物计算机;量子计算机
系统总线
- 总线的基本概念
- 总线的分类
- 总线特性及性能指标
- 总线结构
- 总线控制
各部件之间,通过总线连接
- 总线,设备之间连接的接口,公共的传输线,Bus,
各部件共享信息的传输介质
任意时刻只允许一个设备发送信息,可以有不止一个设备接收信息
总线的信息传输方式,
- 串行,一位一位的传
- 并行,多位多位的传,传输距离较短
- 看似并行快,但高速信号的传输采用的是串行,原因:连接线大大减少,更易实现,成本低
总线种类,
- 1.片内总线,在芯片内部
- 2.通信总线,计算机系统之间,构成一个更大的系统,(串行、并行)
- 3.系统总线 (板级总线),各部件之间,系统总线按传输数据的不同又分为三类:
- 数据总线,双向
通常情况下数据总线宽度 ≤ 机器字长、存储字长
数据总线宽度决定CPU和外界数据传送速度 - 地址总线,由CPU单向发出,
与存储地址、I/O地址有关
按字节编址,寻址到字节;按字寻址,一个字含多个字节
地址总线宽度表明CPU寻址能力 - 控制总线,有出、有入 (非双向)
主要用来传输 控制信号、时序信号 (定时信号,操作命令,请求/回答信号等等)
常见信号:
CPU发出的, 读/写信号、片选信号、中断响应信号 等
反馈给CPU的,中断申请信号、复位信号、总线请求信号 等
- 数据总线,双向
- 寻址:CPU从存储器读数据的时候给出地址,地址信息通过地址总线传输,n 位地址总线可寻址范围为 2n 个存储单元
- 按字编址:简单来说就是一次寻址一个字,因为存储单元的最小编址单位是字,将存储单元划分为若干个字 (此字非存储字),从0开始编号,地址范围比按字节编址要小,因每个地址对应的存储容量大些
- 按字节编址:就是把存储单元按字节划分,一个字节一个地址,从0开始编号
- 参考链接 按字节编址与按字编址.
总线印刷在主板上,留出一些接口,其他部件通过接口连接到主板
总线特性,
- 机械特性,机械连接方面,尺寸、管脚数、排列顺序
- 电气特性,信号传输方向 ,有效电平范围 (例:多大的电平算是高电平) (通常CPU发出的为输出信号)
- 功能特性,每根线上传的到底是什么信号,功能:数据、地址、控制
- 时间特性,信号的时序关系
总线性能指标,
- 总线宽度,即 数据线根数
- 标准传输率,每秒传输最大字节数 MBps
- 时钟同步/异步,同步、异步
- 总线复用,例 8086,20条地址线中16条数据线,减少芯片管脚数
不同信号在同一条信号线上分时传输;通常是地址线与数据线复用 - 信号线数,地址线 + 数据线 + 控制线 根数的总和
- 总线带宽,衡量总线本身所能达到最高传输速率的重要指标
总线带宽 = 总线时钟频率 × 总线宽度 (/ 8)
时钟频率 = 1 / 时钟周期
带宽,数字信号系统中,用来表示通信线路传送数据的能力(bps)
总线标准,为了集成各部件而提出的标准,制定统一的标准,可使芯片级、模块级、设备级等各级别的产品都具有兼容性和互换性,充分保证了整个计算机系统的可维护性和可扩充性
常用的三种标准包括
- ISA(IndustrialStandardArchitecture)总线,也叫 AT 总线,是一种简单的多主控总线
EISA (ExtendedISA) 总线,扩充了100根线,与原ISA总线完全兼容
PCI(PeripheralComponentInterconnect)总线,是一种高性能的32位局部总线
总线结构
-
单总线,严重影响 CPU 运行速度,延迟;总线争用:硬盘优于 CPU;总线成为发展瓶颈
面向CPU的双总线结构,一条 I/O 总线连接外设,一条 M 总线连接主存;不过有时 CPU 执行仍会被打断
以存储器为中心的双总线结构,一条系统总线,一条存储总线,现在仍是分时工作的 -
总线结构,(有点乱)
双总线结构,I/O总线和主存总线通过通道连接;
三总线,DMA总线 (连主存与高速I/O);局部总线 (连CPU与Cache);
主存总线 (连CPU与主存);I/O总线 (连CPU与I/O);
扩展总线 (通过扩展总线接口连扩展总线与系统总线/高速总线);
系统总线 (连Cache/桥与主存);
四总线,系统 + 局部 + 高速 + 扩展;高低速设备分离;
VESA(VL-BUS V萨🤐)总线、PCI总线连高速设备,ISA、EISA总线连低速设备;
VESA目前被PCI取代了,EISA能完全兼容ISA;
PCI总线可扩展,通过桥电路;20.3.1
多层PCI总线结构,一级一级的桥,就是扩展的一根一根的PCI总线
AGP总线,显卡专用的局部总线;
USB总线,(Universal Serial Bus) 通用串行总线;
总线控制,仲裁机构
根据是否能提出总线请求,把总线上的设备分为
- 主设备 (主模块),对总线有控制权,可以提出占用请求
- 从模块,只能响应从主设备发来的总线信号
总线判优控制,集中式和分布式,目的:判断由哪个主设备占用总线
集中式:数据线用于数据的传输,地址线用于从设备的查找
- 链式查询方式,结构简单,BS 总线忙、BR 总线请求、BG 总线同意;离总线控制部件越近,I/O 优先级越高;对电路故障特别敏感
- 计数器定时查询方式,少了BG,多了个设备地址线 (计数器给出其中地址),其宽度为 log2n,其中 n 为设备数;计数,每次从上次停止计数的值开始,循环优先级
- 独立请求方式,少了BS,内部排队器,响应快,缺点是用的线比较多
总线通信控制,目的:解决通信双方 协调配合的问题
- 总线传输周期,四个时钟周期
- 1.申请分配阶段,主模块提出申请
2.寻址阶段,给出地址找到从模块,给出命令
3.传数阶段,主从交换数据
4.结束阶段,主模块撤销相关信息
总线通信的四种方式
- 同步通信,统一时标,强制 主从模块同步数据传送
- 异步通信,应答方式,握手方式
不互锁 (主设备发出请求后就不管了,从设备应答后也不管了,该撤回时都撤回了),
半互锁 (主请求信号在收到应答后撤回,半锁),
全互锁 (主设备的请求信号撤回后,从设备才撤回应答信号) - 半同步通信,同步异步结合,插入等待周期
发送方,用系统时钟前沿 发信号;接收方,用系统时钟后沿 判断、识别
允许不同速度的模块和谐工作,从模块发出WAIT信号,WAIT信号置低电平,增加一个 T 等待周期,直到 WAIT 为高电平 - 分离式通信,把传输周期划分为功能独立的两个子周期;20.3.10 充分挖掘系统总线每个瞬间的潜力
子周期1,主模块申请系统总线,发出地址、命令后解除总线占用
子周期2,从模块申请占用总线,发送信息 (从模块成为主模块)
和前三种方式相比,传输周期中间从模块准备数据的过程让出了总线使用权,而且其总线上所有模块都可以成为主模块
数据帧
- 帧,从起始位到终止位是一个数据帧
- 比特率,又称数据传输率,用来表示带宽的
- 比特率 / 波特率 = 有效位 / 数据帧总位数
存储器
- 概述
- 主存储器
- 高速缓冲存储器
- 辅助存储器
存储器可分哪些类型?
按存储介质分类
- 半导体存储器,MOS 易失,TTL 功耗高
- 磁表面存储器,磁头
- 磁芯存储器,硬磁材料 Core Memory
- 光盘存储器,激光
按存取方式分类
- 存取方式与地址无关 (随机访问),随机、只读;RAM,在程序的执行过程中,可读可写
- 存取方式和地址有关 (串行访问),顺序存取 (磁带)、直接存取 (磁盘) 存储器
按在计算机中的作用分类
- 主存 (内存),RAM、ROM
- 辅存 (外存),磁带、U盘
- Flash Memory,闪存
- 高速缓冲存储器 (Cache) (通常是用SRAM做的),在主板上,部分被集成到CPU芯片内;里面保存的信息是主存的副本,功耗比主存大,速度比主存快
现代存储体系的层次结构,以及为什么要分层?
存储体系,软硬件将 存储介质 结合成一个整体,该整体高速低价,对应用程序员透明 (体系结构)
-
程序的局部性原理,时间、空间的局部性
-
主存 - 辅存层次,为了解决容量问题,
这两个构成的整体叫做虚拟存储器,虚地址,逻辑地址(从0开始) -
缓存 - 主存层次,为了解决速度问题,
使用的是主存储器的地址,实地址,物理地址 20.3.16
主存储器–概述
- 主存的基本组成
存储体 + 地址总线 MAR 译码器 驱动器 + 数据总线 MDR 读写电路 控制电路 - 主存与CPU之间的关系
MAR连地址总线 单向连主存,MDR连数据总线 双向连主存
CPU发出的控制信号主要有,读和写,单向连主存 - 存储单元地址的分配
12345678H 这个数据中,12是高字节,78是低字节 (两个16进制数正好8Bit一个字节)
大端方式,高字节地址为字地址
小端方式,低字节地址为字地址 (字地址都是第一个高位字节)
设地址线24根,按字节寻址,寻址范围为 224 = 16MB
若字长为16位,按字寻址,即一次两个字节,16 / 2 = 8MW (兆字)
若字长32位,按字寻址,就是 4MW (强行解释😅)
寻址范围,地址总线宽度决定寻址能力,通俗讲就是最多能用到多少内存 - 技术指标
存储容量,主存存放二进制代码的总位数
存储速度,存储器的访问时间 (存取时间)
存取周期,连续两次独立的存储器操作所需的最小时间间隔
存储器的带宽,单位时间能读或写多少位,位(字节) / 秒
半导体芯片简介
- 半导体芯片基本结构
存储矩阵,译码驱动电路 + 读写电路
译码驱动电路作用,翻译地址信号,即 将地址信号翻译成对应存储单元的选择信号;译码器,如74138,使能端:保证其正常工作
地址线 单向,数据线 双向,数据线条数 指定存储单元中的二进制信息位数 (基本单元电路数),一条一位,一位一个基本单元电路
片选线,CS、CE (芯片选择、芯片使能) 低电平有效,表示芯片被选中
读写控制线,单线 WE 低写高读,双线 OE 低读、WE 低写 - 译码驱动方式
线选法,容量大的话线太多,容量小的可以选择
重合法,行列地址分别译码,行地址打开数据,列地址打开管子 (通道),二者交叉处的存储单元数据可以通过管子输入输出
随机存取存储器 RandomAccessMemory
- SRAM Static
保存01的原理:核心是触发器
基本单元电路的构成:六个晶体管,双稳态触发器,六管静态RAM,基本单元电路 (控制01)
对单元电路的读入写出::行地址控制一行上所有的行开关,列地址控制列开关
典型的芯片结构,芯片的读入写出:Intel 2114 RAM芯片,矩阵 64 × 64,分四组,每组16列,每个列选信号需要选中4列
- DRAM Dynamic
保存01的原理:电容充放电,有电为1,没电为0
基本单元电路的构成:两种基本单元电路,三管、单管动态RAM,单管有一个电容 还有一个晶体管用于读写
对单元电路的读入写出:
三管中,读出与原存信息相反,写入与输入信息相同
单管中,读出时数据线有电流,信息为 1,写入时充电为 1
典型的芯片结构,芯片的读入写出:
Intel 1103,三管动态RAM芯片,每行读写信号分两行控制
刷新放大器,每过一段时间用来刷新电容信息,因为电容会漏电消失
Intel 4116,单管 (16K × 1位),只有7根地址线,分两次传送地址,第一次7位行地址,第二次7位列地址
63行到64行间,每列都有一个读放大器 (跷跷板电路,一端为0 另一端必为1)
因此0~63行的信息读出相反,64 ~ 127行读出的信息相同(没有经过跷跷板)
读 打开管子后,信息通过 I/O缓冲 > 输出驱动 - 动静比较

DRAM的刷新方式 动态的RAM需要刷新
- 为什么刷新?
不刷新 电容自然放电,信息丢失;刷新只和行地址有关,每次刷一行的单元电路;默认刷新周期2ms - 集中刷新,
存取周期0.5微秒,128 ×128,4000周期
死区,因在刷新的时候不能进行读写,故刷新的时间区间称为死区
0.5 × 128 扫描完所有行需 64微秒,前3872个周期读写,最后128个周期集中刷新
死时间率为 (刷新周期 / 总周期数) 128 / 4000 × 100% = 3.2% - 分散刷新,
存取周期1微秒,其中一半用来读写一半用来刷新,无死区,周期变长,芯片性能下降
读写用0.5微秒,刷新用0.5微秒,过度刷新,过于频繁 - 异步刷新,上两种结合
2ms要刷新128行,把2ms分成128份,每份15.6微秒
相对于每一份,是集中式刷新,相对于总体,是分散式刷新
每份死区0.5微秒,将死区(刷新)放在指令译码阶段,可以降低其对读写的影响,不会出现死区
ROM,ReadOnlyMemory 只读存储器 见 计导第三章硬件的存储设备.
存储器与 CPU 之间的连接
1.存储器容量的扩展
- 位扩展;两个1K × 4位构成一个1K × 8位 这是一组
- 字扩展;两个1K × 8位构成一个2K × 8位 这是不同组 多的那根地址线用来片选
- 同时扩展;先位后字 八个1K × 4位 构成一个 4K × 8位 多的两根地址线用片选译码
2.存储器与 CPU 的连接
基本方法
- 地址线的连接 高位地址线用作片选
数据线的连接
读/写命令线的连接 比较简单
片选线的连接 高位地址线 确保访问的芯片在给定地址范围内
合理选择存储芯片
- 选ROM 系统程序区,配置信息区 (内容不轻易改变)
- 选RAM 用户程序区,系统程序运行区(系统程序工作区)
- 芯片数量尽可能少,片选逻辑尽可能简单
举例
注:MREQ 访存控制信号,低电平有效;其为低电平时访问的是存储器,高电平时访问的是I/O端口(勿忘)
例1
- 要求 6000H - 67FFH是系统程序区 ,6800H - 6BFFH是用户程序区,CPU有16根地址线
- 具体步骤见下题

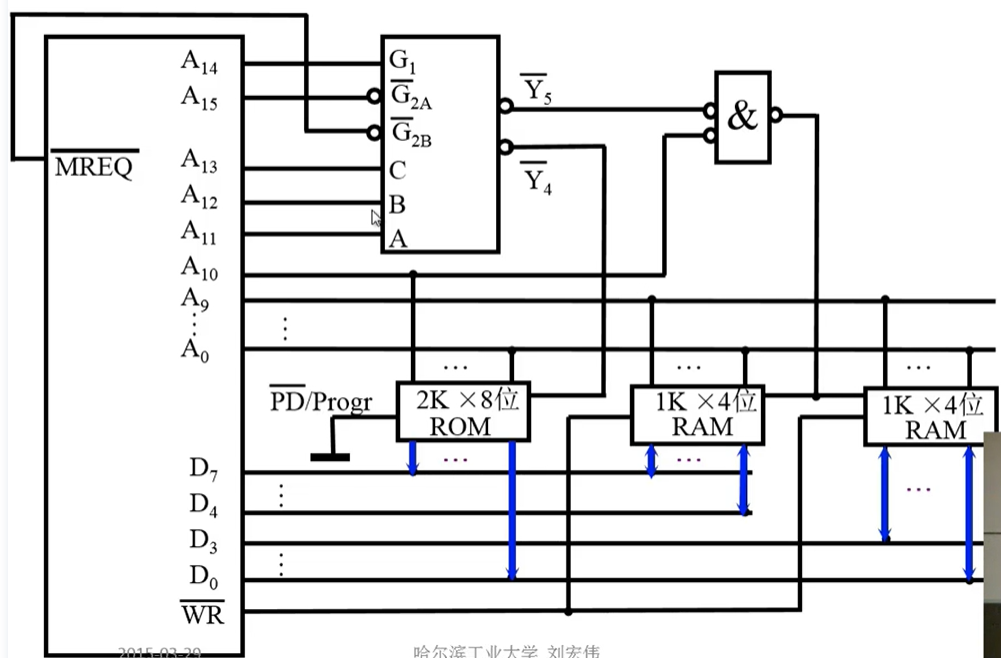
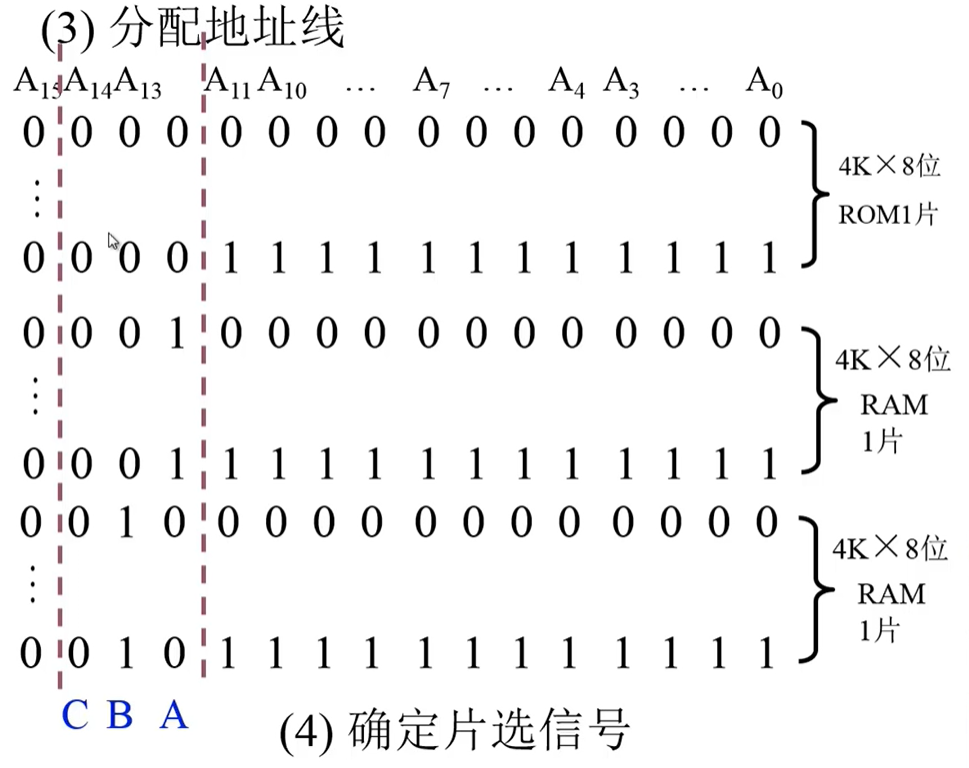
例2
- 要求 最小的4K为系统程序区,相邻的8K为用户程序区
步骤:
1.写出对应的二进制地址码
2.确定芯片的数量及类型
3.分配地址线
4.确定片选信号 (不要忘了 MREQ)
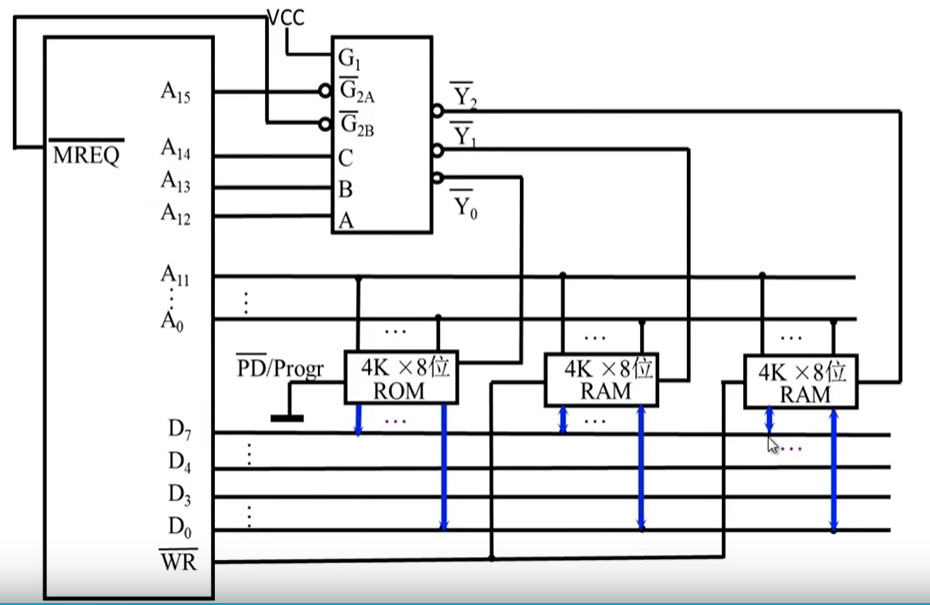
G1接高电平 G2AG2B接低电平
CPU的地址线 要么连芯片 要么连片选译码的输入端
勿忘 MREQ
存储器的校验
1.为什么要对存储器的信息进行校验?
- 电容充放电和触发器反转,总之存储信息出错,导致程序运行错误,甚至更大的事故
2.为了能够检验出信息是否正确,如何进行编码?
- 合法代码集合:集合之外的代码即为出错代码
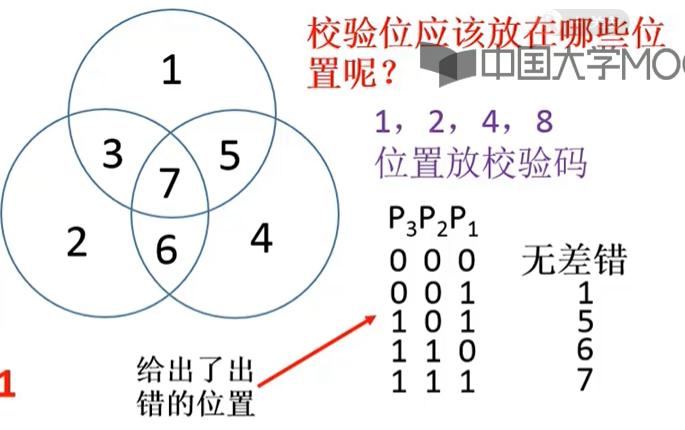
例{000, 111}三倍冗余,检 1 纠 1 - 汉明编码
第 i 组在 2i-1 的位置上是检测位,该位由该组独占,即 检测位一组一位
公式:2^k ≥ n + k + 1
含义:n位信息,k位校验,共 n+k位,可分 k 组
检测结果要能指出 这 n+k 位中哪位出错了,还有一种情况是没错误,所以一共 n+k+1个状态
一共 k 个检测位,可表示 2k 个状态,公式由此推出- 按 配偶原则 配置 0011 的汉明码
步骤:
1.n = 4 根据公式求出 k = 3
2.列表 (汉明码的分组在下面)

- 按 配偶原则 配置 0011 的汉明码
3.纠错和检错能力和什么因素有关?
- 编码的最小距离
定义:任两组 合法代码之间 二进制位数 的 最小差异
换句话说:把一个合法代码改变为另一个合法代码最小需要改的位数
公式
L - 1 = D + C
L 最小距离; D 检错位数; C 纠错位数
4.检出错误后如何进行纠错?
- 将校验后的 P4P2P1 写出即可
- 检测位出错可以不用纠错,对信息无影响
汉明编码 具有1位纠错能力,是一种分组的奇偶校验,默认用 偶校验,分组的作用 是缩小检错范围
- 汉明码的非划分分组
提高访存速度的措施
存储墙:CPU再快,执行程序需要的指令、数据来自内存,运行结果要保存到 内存,内存速度跟不上
1.采用高速器件
- 高性能存储芯片:SDRAM,CPU无需等待;RDRAM,解决存储器带宽问题;带 Cache 的 DRAM 有利于猝发式读取
详见 计导第三章_存储设备.
2.采用层次结构 Cache - 主存
3.调整主存结构
- 单体多字系统 增加存储器带宽
- 多体并行系统
高位交叉 顺序编址体号 + 体内地址存储器容量扩展
低位交叉 各个体轮流编址体内地址 + 体号
不改变存取周期的前提下,增加存储器带宽和访问速度 (联系 分离式通信)

高速缓冲存储器
- 概述
- Cache-主存的地址映射
- 替换算法 (略)
概述
程序访问的局部性原理
- 时间局部性,当前被访问的指令和数据以后还有可能被访问
- 空间局部性,当前被访问的 相邻的指令和数据有可能被访问
所以Cache块中存放的:当前访问的指令和数据 + 相邻的指令和数据
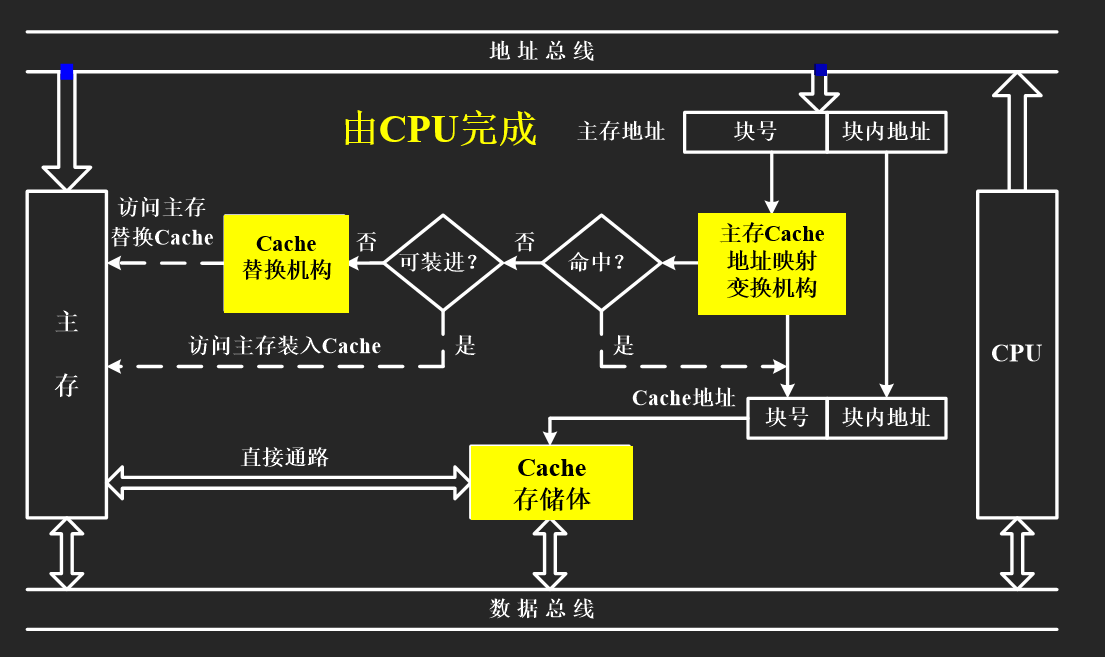
工作原理
- 主存 M 块,Cache C 块,M >> C (主存和Cache按块存储,块大小相同)
主存与Cache之间的传输中,块是一个整体
编址:块号 + 块内地址
(实际应用中,Cache 地址意义不大)
标记,是主存块号地址所对应的,CPU给出的地址会先与标记比较,从而判断Cache中是否有
命中与未命中
- 命中,主存块 已调入 缓存,主存块与缓存块对应关系 已建立 (未命中则相反)
- 用 标记 记录建立了对应关系的 主存块号
命中率:CPU 欲访问信息在 Cache 中的比率 (与Cache的 容量 和 块长 有关)
- 一般块大小取4~8个字 (块长取一个存储周期内从主存调出的信息长度)
(块如果太小,存储的信息不够,就没有充分利用局部性原理
块如果太大,存储的信息只有部分对CPU执行程序有用,且Cache总容量有限,块数会减少) - 多体交叉,几体 块长就取几个存储字
Cache-主存系统访问效率 e 与命中率有关 e = 访问Cache的时间 / 平均访问时间 × 100%
平均访问时间,可用 h × tc + (1 - h) × tm 计算 (设命中率 h 访问Cache 主存时间分别为 tc tm)
(若先访问Cache,没找到,再访问主存,公式会发生变化)
Cache的基本结构
Cache的读写操作
写,需要解决Cache和主存的一致性问题
- 写直达法 (Write-through),都写入,写操作时间 = 访问主存的时间
优点 时刻保持一致
缺点 可能造成频繁CPU与内存信息交换 - 写回法 (Write-back),写操作时间 = 访问Cache的时间
若所给地址对应块已在Cache中,只在Cache中写,直到该块被替换,写回主存,不能
Cache的改进
- 1.增加级数,片载 片外
- 2.统一缓存,分立缓存 (分为指令Cache 和数据Cache 流水线)
Cache-主存的地址映射
- 直接映射
- 全相联映射
- 组相联映射
计算机的运算方法
- 无符号数和有符号数
- 数的定点表示和浮点表示
- 定点运算
- 浮点四则运算
- 算术逻辑单元
无符号数,数据放在寄存器或存储器中,位数反映范围
有符号
- 真值,带符号的数
- 机器数,把符号数字化的数 (0正1负)
- 小数,符号位 后是小数点位置
- 整数,数值位 后是小数点位置
其中表示 +0 -0,只有补码表示的一样(还有移码),原码和反码都有两种表示
对于正数,三种表示都一样
在小数定点机中,只有补码可以表示 -1
在整数定点机中,三种机器数均可表示 -1
原码表示法(x 表示真值,下面的 n 都指整数位数)
- 整数
正,x
负,2n - x
用逗号 隔开符号和数值 - 小数
正,x
负,1 - x
用小数点 隔开符号和数值 - 小数点和逗号都不存,只是为了方便看
- 定点小数中,原码不能表示 -1
补码表示法 (主要是为了把减法换成加法)
(加法结果超出 mod 模 的表示范围时,最高位会被丢掉)
- 整数
正,x
负,2n+1 + x (mod 2n+1)
逗号隔开 - 小数
正,x
负,2 + x (mod 2) (2 用1 0来表示)
小数点隔开
快捷算法
- 前提:真值为负 (负数)
- 原码到补码,数值位取反,末位 + 1
时刻记住,表示在机器中的数的时候,一定受计算机中存储资源的限制
例如:要存6位,限制4位,那么最后两位就会被丢掉
反码表示法
- 整数
正,x
负,(2n+1 - 1) + x (mod 2n+1 - 1) (就是补码中的 1 不加了)
逗号隔开 - 小数
正,x
负,(2 - 2-n) + x (mod 2 - 2-n) (在小数中,加的 1 = 2-n)
小数点隔开
移码表示法 (方便判断大小)
- 无论正负,2n + x (不过只表示整数),通常用来表示浮点数的阶码部分
- 补码和移码只差一个符号位
定点表示,即小数,小数点在数符位后,整数,小数点在数值位后
浮点表示
N = S × r j,S 尾数, j 阶码, r 尾数的基值
S 小数,正负皆可
j 整数,正负皆可
- 最大正数:j = 2m - 1,则最大为 2j · (1 - 2-n),对应最小负数
- 最大负数:-2-j · 2-n,对应最小正数
浮点数的规格化形式,为了保证精度,让尾数中有效位尽可能多(形式和基数 r 有关)
左规 右规,r 越大,可表示的浮点数的范围越大,浮点数的精度降低
定点运算
移位运算,注:小数点不动,左移指数据相对于小数点左移
- 移位规则,正数,都添 0
负数,原码 添 0,反码 添 1,补码 左添 0,右添 1
移位的硬件实现
算术移位,有符号
逻辑移位,无符号
加减运算
- 补码
直接相加减 条件 整数 mod 为2n+1,小数 mod 为2
连同符号位一起相加,符号位产生的进位会自然丢掉
溢出判断,符号相同,结果符号不同,即为溢出
最高有效位的进位 ⊕ 符号位的进位 = 1 溢出
双符号位,不同,溢出,最高位决定正负溢出
乘法运算,笔算乘法,改进:用加+移位实现
指令系统
- 机器指令
- 操作数类型和操作类型
- 寻址方式
- 指令格式举例‘
- RISC技术
机器指令
扩展操作码技术:操作码随地址数的减少而增加
- 假设:一个指令:操作码+三个地址
- 三地址指令,二地址、一地址、零地址
- 三地址指令操作码每减少一种,二地址可多构成 2n 个 (n为三地址指令中操作码位数)
地址码
(A1)OP(A2) → A3 4次访存
- 第一次访存:取出指令,得到A4地址
- 第二次访存:取出A1
- 第三次访存:取出A2
- 第四次访存:结果存入A3
总结:1.当用一些硬件资源代替指令中的地址码字段后 例如ACC、A1等
- 可扩大指令寻址范围 (指令长度固定,地址码数减少,地址码长度增加,操作码长度不变),二地址,一地址,零地址
- 可缩短指令字长 (指令长度不固定,地址码数减少,地址码长度不变,指令长度减少)
- 减少访存次数,减少为3、2、1
2.当地址的指令字段为寄存器时
- 可缩短指令字长
- 指令执行阶段不访存 (取指令的时候访存一次)
指令字长
被 操作码长度、操作数地址的长度、操作数地址的个数 影响
- 若指令字长固定,则指令字长 ≤ 存储字长
- 若指令字长可变,按字节倍数变化
操作数类型和操作类型
操作数类型:地址、数字、字符、逻辑数
数据在存储器中的存储方式
- 从任意位置开始存储,优点不浪费,缺点存取周期长,读写控制难
- 从一个存储字的起始位置开始访问,优点访存快,读写简单,缺点浪费大
- 边界对准方式:上面两个的折中;数据存放的起始地址是数据长度的整数倍 (按编址单位进行计算)
操作类型
- 数据传送:源,目的地,MOVE
- 算术逻辑操作
- 移位操作
- 转移:
- 1.无条件转移 JMP
- 2.条件转移 SKP JZ
- 3.调用和返回
- 4.陷阱指令 Trap:意外事故的中断,CPU自动执行的隐指令
- 5.输入输出,端口内容 输入 CPU寄存器,反之输出
寻址方式
为什么设置多个寻址方式
包括指令的寻址、指令当中数据的寻址
指令的寻址,指令寻址
- 顺序 PC+1,加的 1 是一个编制单位
- 跳跃,由转移指令指出
指令中数据的寻址,数据寻址;格式:操作码 + 寻址特征 + 形式地址 A;有效地址 EA:操作数的真实地址
- 1.立即寻址,寻址特征
#;不访存
A就是操作数,立即数,A位数决定立即数范围 - 2.直接寻址,访存一次
EA = A,A位数决定操作数寻址范围,操作数地址不易修改 - 3.隐含寻址,操作数地址隐含在操作码中
指令中减少了一个地址码字段,缩短指令字长 - 4.间接寻址,访存两次 或 多次
EA = (A),有效地址由形式地址间接提供,扩大寻址范围,便于编写程序 - 5.寄存器寻址,不访存,寄存器中存的是操作数
有效地址即寄存器编号,EA = Ri,也称寄存器直接寻址,速度快,指令字长缩短 - 6.寄存器间接寻址,访存一次,寄存器中存的是 EA
有效地址在寄存器中,操作数在存储器中,便于编制循环程序 - 7.基址寻址,分为采用专用和通用寄存器作为基址寄存器
- 采用专用,BR 专用寄存器,EA = (BR) + A,BR不变,A可变,操作系统和管理员可修改BR;有利于多道程序,扩大寻址范围
- 通用,用户可以指定哪个寄存器作为基址寄存器R0,但不可更改其内容,R0不变,A可变
- 8.变址寻址,也分专用和通用
- EA = (IX) + A,与基址寻址不同之处在于 IX 用户可以修改,但 A 不能变,便于处理数组问题
- 例:ADD X, D (D为形式地址)
- 9.相对寻址,寻址特征:
*;A是相对于当前指令的偏移量,即相对距离- EA = (PC) + A,A的位数决定操作数寻址范围(相对距离的范围),利于程序浮动,广泛用于转移指令
- 注意按字节寻址,需要修正PC
- 10.堆栈寻址,进栈:(SP) - 1,出栈:(SP) + 1
- P104

![[车联网安全自学篇] Android安全之ARM汇编指令集手册「精简汇总版」](https://img-blog.csdnimg.cn/1f5949f3c5bc471aac030227abedcd80.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6I-g6JCdX-apmeeVmemmmQ==,size_20,color_FFFFFF,t_70,g_se,x_16)