1.Doc2vec模型介绍
Doc2Vec模型基于Word2vec模型,并在其基础上增加了一个段落向量。 以Doc2Vec的C-BOW方法为例。算法的主要思想在以下两个方面:
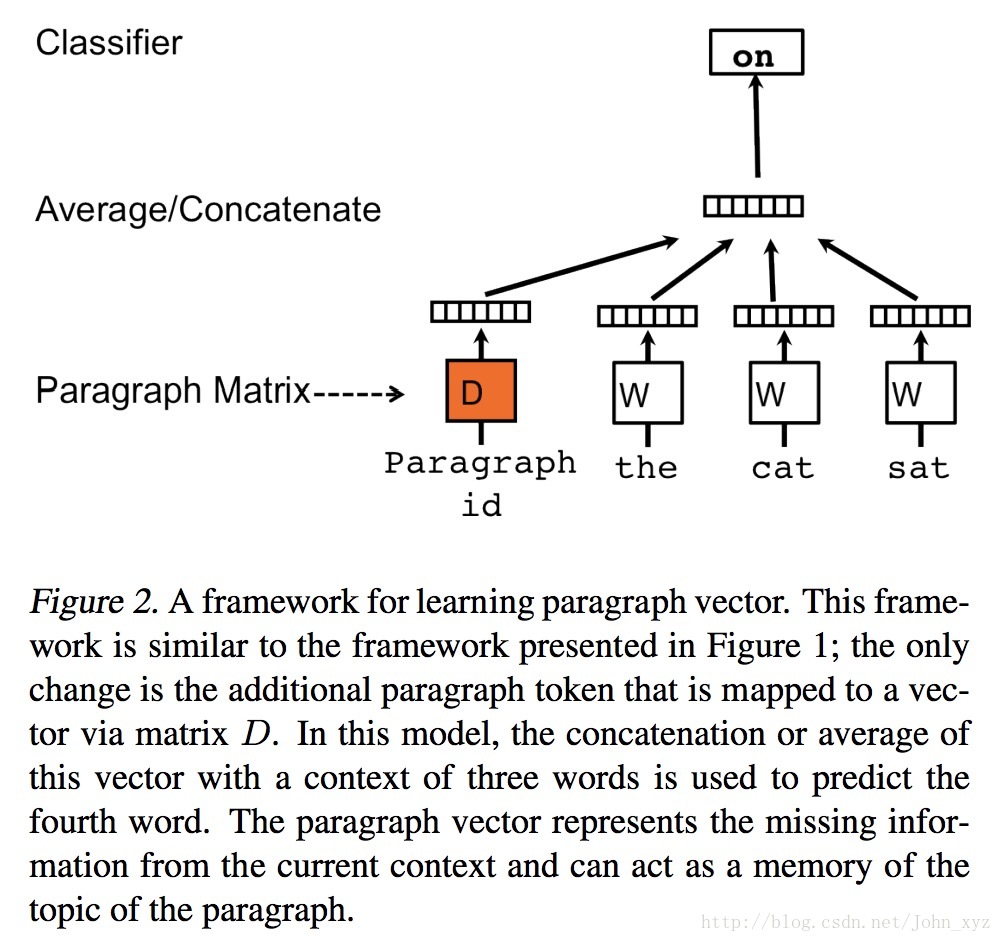
- 训练过程中新增了paragraph id,即训练语料中每个句子都有一个唯一的id。paragraph id和普通的word一样,也是先映射成一个向量,即paragraph vector。paragraph vector与word vector的维数虽一样,但是来自于两个不同的向量空间。在之后的计算里,paragraph vector和word vector累加或者连接起来,作为输出层softmax的输入。在一个句子或者文档的训练过程中,paragraph id保持不变,共享着同一个paragraph vector,相当于每次在预测单词的概率时,都利用了整个句子的语义。
- 在预测阶段,给待预测的句子新分配一个paragraph id,词向量和输出层softmax的参数保持训练阶段得到的参数不变,重新利用梯度下降训练待预测的句子。待收敛后,即得到待预测句子的paragraph vector。
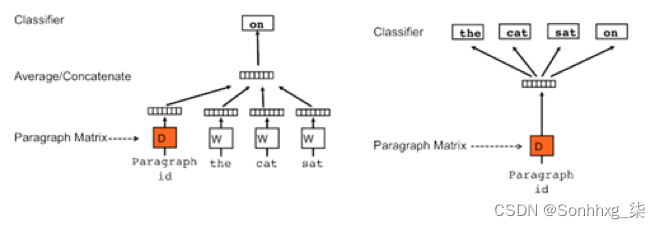
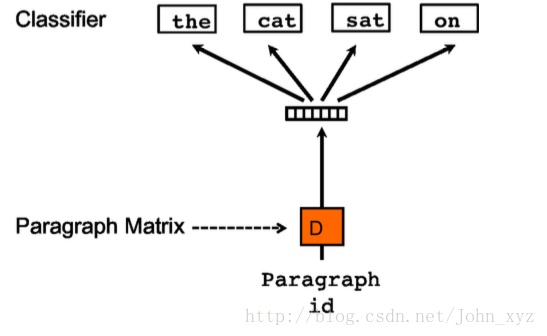
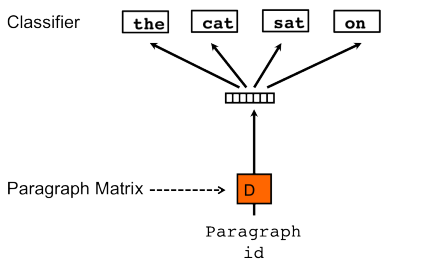
通过对模型结构图来区别Doc2vec与Word2vec。
图1. Word2vec模型结构图

图2. Doc2vec模型结构图

Doc2vec模型通过增加paragraph vector,相当于在进行训练的时候,为每一个word的预测同时考虑到了文章的整体信息,可以理解为主题,也即是给每一个单词都赋予了文章主旨,这样一来,在进行文本相似度计算的时候,也就更多的考虑到了文章整体表达的中心意思。
2.模型训练
对于模型的训练,实现也非常方便,利用Python的gensim.Dco2vec接口即可以进行训练,主要步骤如下:
1. 将原始文本语料进行分词,去停用词处理,最后保存为文本文件。示例:1000 北京 欢迎 各国 朋友1001 中华 民族 团结友爱前面的‘1000’、‘1001’是文档编号,你也可以按自己的方式进行生成。后面训练的时候会用到。2. 将处理后的文档进行paragraph打标处理:gensim.models.doc2vec.TaggedDocument(words=doc.split(), tags=doc_id)其中doc为分词处理后的每篇文档,以空格作为分隔符分隔,doc_id也即为文档编号,是唯一值。3. 定义模型结构及参数model = gensim.models.Doc2Vec(vector_size=256, window=10, min_count=5,workers=4, alpha=0.025, min_alpha=0.025, epochs=12)关于各参数的解释如下,· vector_size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好.· window:表示当前词与预测词在一个句子中的最大距离是多少· alpha: 是学习速率· min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5· workers参数控制训练的并行数。· epochs: 迭代次数,默认为54. 将处理后的数据带入模型进行训练model.build_vocab(train_data)train_data是第二步将所有文档处理后的数据,也即为模型训练所用的数据。model.train(train_data, total_examples=model.corpus_count, epochs=12)5. 模型的保存model.save("./models/doc2vec.model")
3.文本相似度计算
文本相似度的计算方式有很多,比较常用的也就是余弦相似度。
余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。
余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量的方向越接近;越趋近于-1,他们的方向越相反;接近于0,表示两个向量近乎于正交。
最常见的应用就是计算文本相似度。将两个文本根据他们词,建立两个向量,计算这两个向量的余弦值,就可以知道两个文本在统计学方法中他们的相似度情况。实践证明,这是一个非常有效的方法。
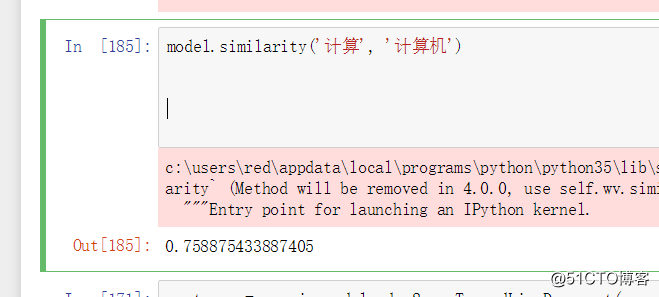
公式:def similarity(a_vect, b_vect)
a_vect, b_vect是文本处理后得到的向量。
通过model.wv[w]得到单个词语的向量。最后给出该项目的地址:https://github.com/KAIKAIZHANG/text_similarity.git
欢迎阅读,如有不当之处,欢迎交流。参考了以下两篇文章:
https://blog.csdn.net/juanjuan1314/article/details/75461180
https://www.cnblogs.com/softmax/p/9042397.html