简介
与其他方法的比较
bag of words (BOW):不会考虑词语出现的先后顺序。
Latent Dirichlet Allocation (LDA):更偏向于从文中提取关键词和核心思想extracting topics/keywords out of texts,但是非常难调参数并且难以评价模型的好坏。
基石:word2vec
Word2vec 是一种计算效率特别高的预测模型,用于学习原始文本中的字词嵌入。它分为两种类型:连续词袋模型 (CBOW) 和 Skip-Gram 模型。从算法上看,这些模型比较相似,只是 CBOW 从源上下文字词(“the cat sits on the”)中预测目标字词(例如“mat”),而 skip-gram 从目标字词中预测源上下文字词。这种调换似乎是一种随意的选择,但从统计学上来看,它有助于 CBOW 整理很多分布信息(通过将整个上下文视为一个观察对象)。在大多数情况下,这对于小型数据集来说是很有用的。但是,skip-gram 将每个上下文-目标对视为一个新的观察对象,当我们使用大型数据集时,skip-gram 似乎能发挥更好的效果。

CBOW: Continuous bag of words creates a sliding window around current word, to predict it from “context” — the surrounding words. Each word is represented as a feature vector. After training, these vectors become the word vectors.
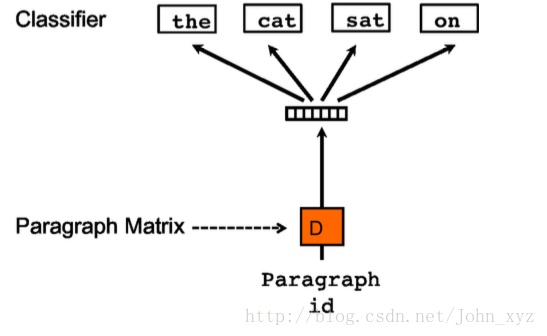
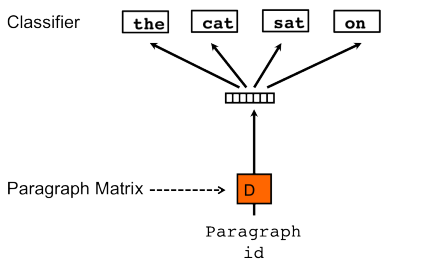
Doc2Vec形成
word2vec + document-unique feature vector = when training the word vectors W, the document vector D is trained as well, and in the end of training, it holds a numeric representation of the document.
Distributed Memory version of Paragraph Vector (PV-DM). It acts as a memory that remembers what is missing from the current context — or as the topic of the paragraph. While the word vectors represent the concept of a word, the document vector intends to represent the concept of a document.
another algorithm, which is similar to skip-gram may be used Distributed Bag of Words version of Paragraph Vector (PV-DBOW).
参数
| Parameters: | - documents (iterable of list of
TaggedDocument, optional) – Input corpus, can be simply a list of elements, but for larger corpora,consider an iterable that streams the documents directly from disk/network. If you don’t supply documents (or corpus_file), the model is left uninitialized – use if you plan to initialize it in some other way. - corpus_file (str, optional) – Path to a corpus file in
LineSentence format. You may use this argument instead of documents to get performance boost. Only one of documents or corpus_file arguments need to be passed (or none of them, in that case, the model is left uninitialized). Documents’ tags are assigned automatically and are equal to line number, as in TaggedLineDocument. - dm ({1,0}, optional) – Defines the training algorithm. If dm=1, ‘distributed memory’ (PV-DM) is used. Otherwise, distributed bag of words (PV-DBOW) is employed.
- vector_size (int, optional) – Dimensionality of the feature vectors.
- window (int, optional) – The maximum distance between the current and predicted word within a sentence.
- alpha (float, optional) – The initial learning rate.
- min_alpha (float, optional) – Learning rate will linearly drop to min_alpha as training progresses.
- seed (int, optional) – Seed for the random number generator. Initial vectors for each word are seeded with a hash of the concatenation of word + str(seed). Note that for a fully deterministically-reproducible run, you must also limit the model to a single worker thread (workers=1), to eliminate ordering jitter from OS thread scheduling. In Python 3, reproducibility between interpreter launches also requires use of the PYTHONHASHSEED environment variable to control hash randomization.
- min_count (int, optional) – Ignores all words with total frequency lower than this.
- max_vocab_size (int, optional) – Limits the RAM during vocabulary building; if there are more unique words than this, then prune the infrequent ones. Every 10 million word types need about 1GB of RAM. Set to None for no limit.
- sample (float, optional) – The threshold for configuring which higher-frequency words are randomly downsampled, useful range is (0, 1e-5).
- workers (int, optional) – Use these many worker threads to train the model (=faster training with multicore machines).
- epochs (int, optional) – Number of iterations (epochs) over the corpus.
- hs ({1,0}, optional) – If 1, hierarchical softmax will be used for model training. If set to 0, and negative is non-zero, negative sampling will be used.
- negative (int, optional) – If > 0, negative sampling will be used, the int for negative specifies how many “noise words” should be drawn (usually between 5-20). If set to 0, no negative sampling is used.
- ns_exponent (float, optional) – The exponent used to shape the negative sampling distribution. A value of 1.0 samples exactly in proportion to the frequencies, 0.0 samples all words equally, while a negative value samples low-frequency words more than high-frequency words. The popular default value of 0.75 was chosen by the original Word2Vec paper. More recently, in https://arxiv.org/abs/1804.04212, Caselles-Dupré, Lesaint, & Royo-Letelier suggest that other values may perform better for recommendation applications.
- dm_mean ({1,0}, optional) – If 0 , use the sum of the context word vectors. If 1, use the mean. Only applies when dm is used in non-concatenative mode.
- dm_concat ({1,0}, optional) – If 1, use concatenation of context vectors rather than sum/average; Note concatenation results in a much-larger model, as the input is no longer the size of one (sampled or arithmetically combined) word vector, but the size of the tag(s) and all words in the context strung together.
- dm_tag_count (int, optional) – Expected constant number of document tags per document, when using dm_concat mode.
- dbow_words ({1,0}, optional) – If set to 1 trains word-vectors (in skip-gram fashion) simultaneous with DBOW doc-vector training; If 0, only trains doc-vectors (faster).
- trim_rule (function, optional) –
Vocabulary trimming rule, specifies whether certain words should remain in the vocabulary, be trimmed away, or handled using the default (discard if word count < min_count). Can be None (min_count will be used, look to keep_vocab_item()), or a callable that accepts parameters (word, count, min_count) and returns either gensim.utils.RULE_DISCARD, gensim.utils.RULE_KEEP or gensim.utils.RULE_DEFAULT. The rule, if given, is only used to prune vocabulary during current method call and is not stored as part of the model. The input parameters are of the following types: - word (str) - the word we are examining
- count (int) - the word’s frequency count in the corpus
- min_count (int) - the minimum count threshold.
- callbacks – List of callbacks that need to be executed/run at specific stages during training.
|
|---|
踩坑记录
在最开始使用doc2vec的时候我只label了测试集和验证集的数据(因为这两个是已经被标注的数据分离出来的train_test_split)。结果在预测真正的测试集的数据时就出现了问题。doc2vec目前只能预测他已经见过的词,那些文本样例可以不需要标注,但是必须见过。个人认为这是doc2vec一个比较大的缺点。所以只能再将测试集数据label一遍。我这里说的label可不是对数据分类(不是该文本样例属于哪一个class),具体label代码见下。
from gensim.models import doc2vecdef label_sentences(corpus, label_type):"""Gensim's Doc2Vec implementation requires each document/paragraph to have a label associated with it.We do this by using the TaggedDocument method. The format will be like "TRAIN_i" where "i" isa dummy index of the complaint narrative."""labeled = []for i, v in enumerate(corpus):label = label_type + '_' + str(i)labeled.append(doc2vec.TaggedDocument(v.split(), [label]))return labeled
接着,doc2vec处理文本之后拿到了一个二维的数组。后面接了一个普通的神经网络进行预测。但是发现效果并不好。就想着要不然把这个二维的数组喂给GNU/LSTM看看。当时GNU报错说expected dim=3但是只拿到了dim=2,于是我在参考了网上一些文档之后把x(文本样例),y(分类的标注)reshape分别成了(shape[0], shape[1], 1), 其实就是为了凑够三个维度。模型倒是能跑了。不过我发现loss根本就不下降。
其实doc2vec处理文本以后根本就不可以接GNU/LSTM。因为这两个是循环神经网络,需要序列性的模型,而doc2vec处理文本之后已经没有序列性了。
参考:
- https://medium.com/scaleabout/a-gentle-introduction-to-doc2vec-db3e8c0cce5e