Doc2vec是基于Word2Vec方法,有两种训练方法,为Distributed Memory (DM) 和Distributed Bag of Words (DBOW); Distributed Memory version of Paragraph Vector
(PV-DM)方法与CBOW方法类似,Bag of Words version of Paragraph Vector (PV-DBOW)与Skip-gram方法类似;同时给文章也给定向量并训练更新。
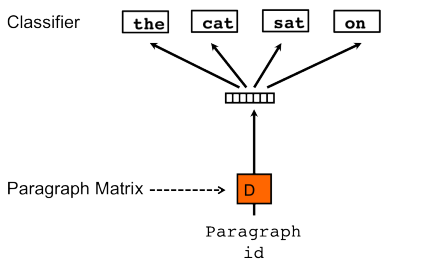
在Doc2vec中,每一句话用唯一的向量来表示,用矩阵D的某一列来代表。每一个词也用唯一的向量来表示,用矩阵W的某一列来表示。


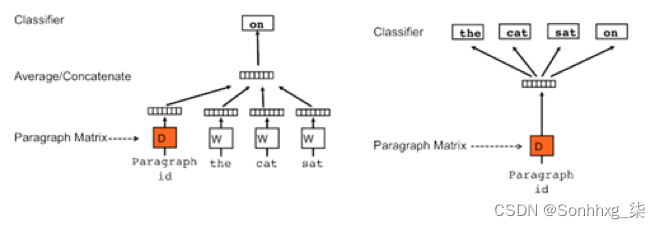
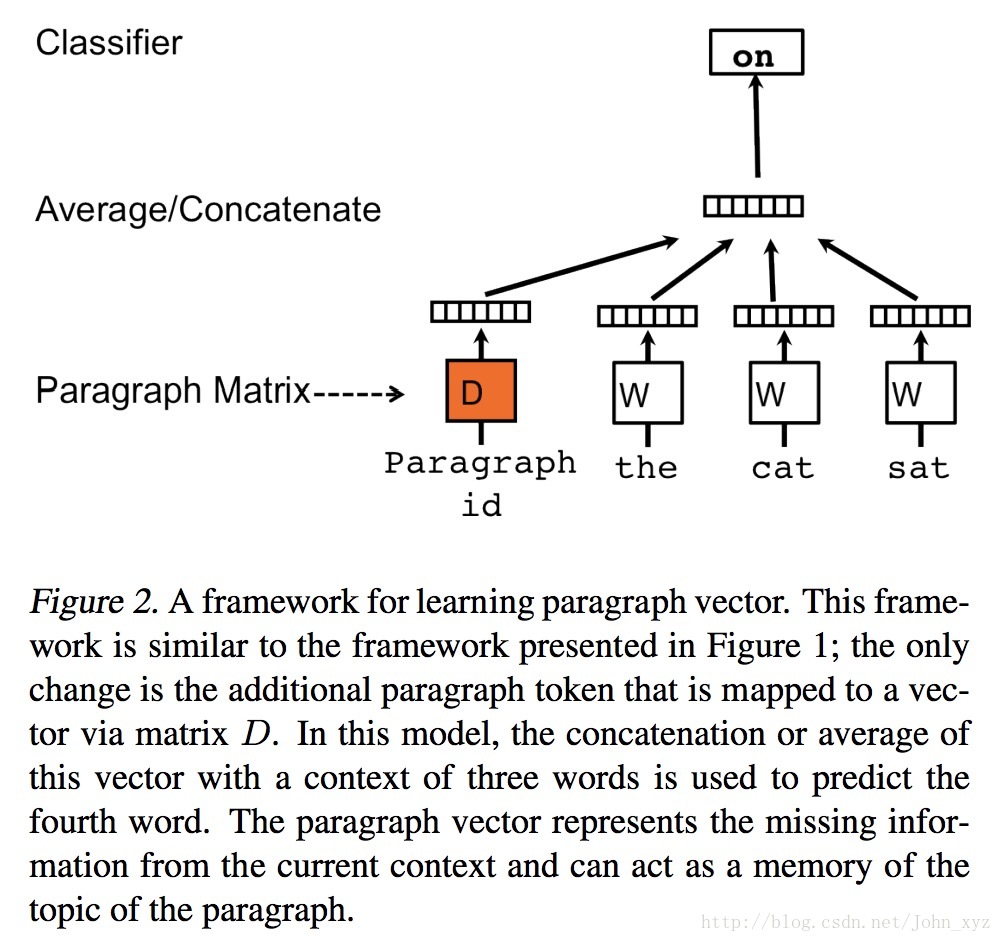
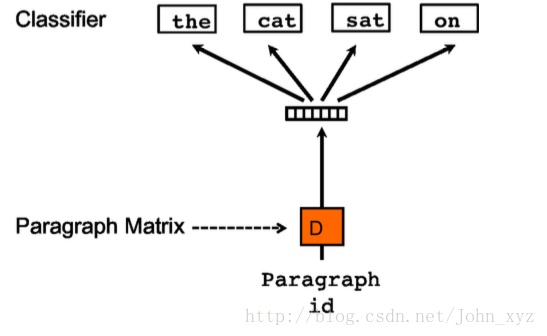
左图为PV-DM(CBOW)模式,右图为PV-DBOW(skip-gram)模式
以PV-DM模式为例,取一句话中的一个词作预测词,其他词作输入词,其他词对应的词向量word vector和本句话对应的句子向量Paragraph vector作为输入层的输入,将Paragraph vector与其他词的词向量相加求均值或累加为新向量 X,使用向量 X 预测取出的词向量。
Doc2vec 增添了句子向量Paragraph vector,Paragraph vector可看作是一个词向量。
词袋模型中,每次训练只截取句子中一小部分词训练,忽略了本次训练词以外该句子中的其他词,仅仅训练了每个词的向量,句子只是每个词的向量累加在一起表达的,忽略了文本的词序。Paragraph vector 则弥补了这个不足,每次训练也是滑动截取句子中一小部分词来训练,Paragraph Vector 在同一个句子的训练中是共享的,这样同一句话会有多次训练,每次训练中输入都包含Paragraph vector,可被看作句子主旨,这样每次训练是句子的主旨向量也会被训练更新。训练完后会得到训练样本中所有的词向量和每句话对应的句子向量。
在预测新的句子的时候,将Paragraph vector随机初始化,放入模型中再重新根据随机梯度下降迭代求得稳定的句向量。预测过程中,模型里的词向量还有投影层到输出层的softmax weights参数不变,在不断迭代中只更新Paragraph vector,其他参数均已固定,很快就可获得预测的句向量。
x_train和x_test中存放的是gensim.models.doc2vec.TaggedDocument类的数据,
有words和tags两个属性,两者都是列表,前一个存words列表,后一个存段落标签。
def train(x_train, x_test, unsup_reviews, vector_size=400, epoch_num=10):# 实例 DM 和 DBOW 模型model_dm = gensim.models.Doc2Vec(min_count=1, window=10, vector_size=vector_size,sample=1e-3, negative=5, dm=1, workers=3)model_dbow = gensim.models.Doc2Vec(min_count=1, window=10, vector_size=vector_size,sample=1e-3, negative=5, dm=0, workers=3)all_words = []all_words.extend(x_train)all_words.extend(x_test)all_words.extend(unsup_reviews)# 使用所有的数据建立词典,model_dm.build_vocab(all_words)model_dbow.build_vocab(all_words)# 将训练所需数据合并train_data= []train_data.extend(x_train)train_data.extend(unsup_reviews)# total_words 或 total_examples 需要赋值,epoches也需要给出# 如果模型执行过build_vocab(),则使用corpus_count即可获取total_words的值model_dm.train(train_data, epochs=epoch_num, total_words=model_dm.corpus_count) model_dbow.train(train_data, epochs=epoch_num, total_words=model_dm.corpus_count)return model_dm, model_dbow
参考:
https://radimrehurek.com/gensim/models/doc2vec.html(gemsim使用doc2vec实例)
https://cs.stanford.edu/~quocle/paragraph_vector.pdf(原始paper)
http://ai.stanford.edu/~amaas/data/sentiment/(IMDB影评数据)
基于gensim的Doc2Vec简析_林海山波的博客-CSDN博客_doc2vec gensim
Doc2Vec模型介绍及使用 - 灰信网(软件开发博客聚合)