在我之前的几篇博客中,我介绍了两种文档向量化的表示方法,如Sklearn的CountVectorizer和TfidfTransformer,今天我们再来学习另外一种文档的向量化表示方法-Doc2Vec。如果你还不太了解Doc2Vec的话,我提供一些资料以便你可以对它有深入的了解:
- Doc2Vec的简介及应用(gensim)
- 基于gensim的Doc2Vec简析
- 词语分布式表示及其组合性
- 关于IMDB情感数据集的Gensim Doc2Vec教程
- 使用word embeddings进行文档分类的教程
本文不会对Doc2Vec的原理进行深入的介绍,我们的目的在于“使用”和“实战”,如果想要深入了解Doc2Vec内部机制和原理可以参考我推荐的上述文档和教程。我们这次使的用数据来自于我上次的博客使用python和sklearn的中文文本多分类实战开发中使用的数据,不过这次我们不再使用CountVectorizer和TfidfTransformer,我们将使用Gensim的Doc2Vec技术对中文文本数据进行量化处理和文档多分类。好了,废话少说,让我们撸起袖子干起来吧!
数据
我们可以从这里下载数据,数据中包含了10 个类别(书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、酒店),共 6 万多条评论数据 首先查看一下我们的数据,这些数据都是来自于电商网站的用户评价数据,我们最终的目的是把不同评价数据归类到不同的分类中去,且每条数据只能对应10个类中的一个类。
%matplotlib inline
import pandas as pd
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
import jieba as jb
import re
from sklearn import utils
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from gensim.models.doc2vec import TaggedDocument
import multiprocessingdf = pd.read_csv('./data/shopping.csv')
df=df[['cat','review']]
print("数据总量: %d ." % len(df))
df.sample(10)
接下来我们还是要做一下数据清洗工作,删掉数据中的空值:
print("在 cat 列中总共有 %d 个空值." % df['cat'].isnull().sum())
print("在 review 列中总共有 %d 个空值." % df['review'].isnull().sum())
df[df.isnull().values==True]
df = df[pd.notnull(df['review'])]
df = df.reset_index(drop=True)![]()
接下来我们统计一下各个类别的数据量:
d = {'cat':df['cat'].value_counts().index, 'count': df['cat'].value_counts()}
df_cat = pd.DataFrame(data=d).reset_index(drop=True)
print(df_cat)df_cat.plot(x='cat', y='count', kind='bar', legend=False, figsize=(8, 5))
plt.title("类目数量分布")
plt.ylabel('数量', fontsize=18)
plt.xlabel('类目', fontsize=18) 
我们看到各个类别的数据量不一致,洗发水、衣服、酒店、水果、平板的数据量最多各有1万条,而热水器的数据量最少只有574条,分布很不均匀。接下来还是老规矩,我们要做数据预处理的工作。
数据预处理
我们要删除文本中的标点符号,特殊符号,还要删除一些无意义的常用词(stopword),因为这些词和符号对系统分析预测文本的内容没有任何帮助,反而会增加计算的复杂度和增加系统开销,所有在使用这些文本数据之前必须要将它们清理干净。首先我们要定义几个清洗文本的函数:
#定义删除除字母,数字,汉字以外的所有符号的函数
def remove_punctuation(line):line = str(line)if line.strip()=='':return ''rule = re.compile(u"[^a-zA-Z0-9\u4E00-\u9FA5]")line = rule.sub('',line)return line#停用词列表
def stopwordslist(filepath): stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()] return stopwords #加载停用词
stopwords = stopwordslist("./data/chineseStopWords.txt")然后我们开始数据清洗工作,清洗工作包括删除标点符号和停用词等,我们将会在数据集中增加两个字段clean_review和cut_review。
#删除除字母,数字,汉字以外的所有符号
df['clean_review'] = df['review'].apply(remove_punctuation)#分词,并过滤停用词
# df['cut_review'] = df['clean_review'].apply(lambda x: " ".join([w for w in list(jb.cut(x)) if w not in stopwords]))
df['cut_review'] = df['clean_review'].apply(lambda x: [w for w in list(jb.cut(x)) if w not in stopwords])
df.head() 
数据清洗工作完成以后,我们要开始创建训练集和测试集,我们将使用7:3的比例来拆分数据,然后就是创建训练集和测试集的标签化文档TaggedDocument:
#创建训练集和测试集
train, test = train_test_split(df, test_size=0.3, random_state=42,stratify = df.cat.values)#创建标签化文档
train_tagged = train.apply(lambda r: TaggedDocument(words=r['cut_review'], tags=[r['cat']]), axis=1)
test_tagged = test.apply(lambda r: TaggedDocument(words=r['cut_review'], tags=[r['cat']]), axis=1)
Doc2vec模型配置
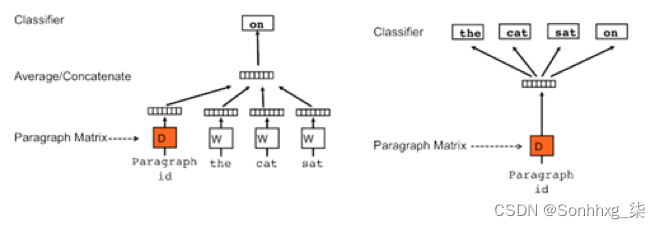
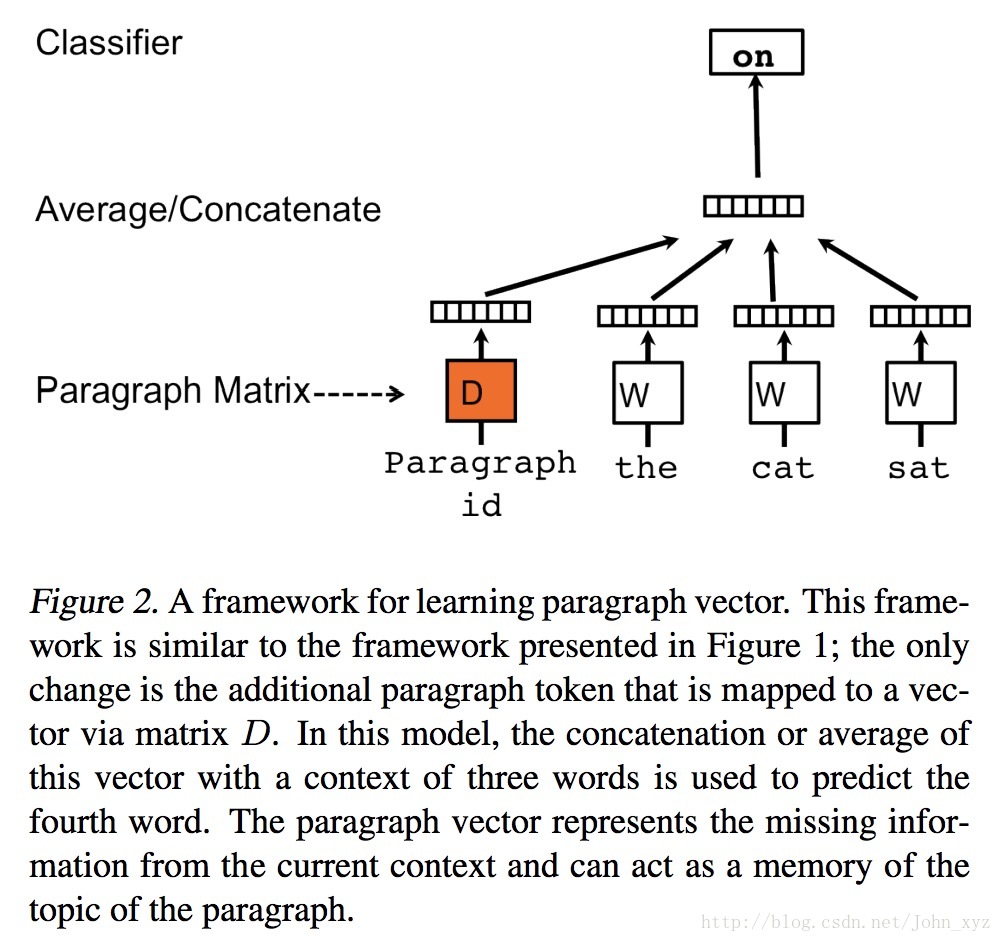
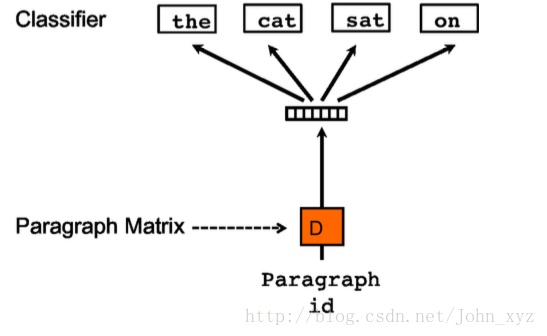
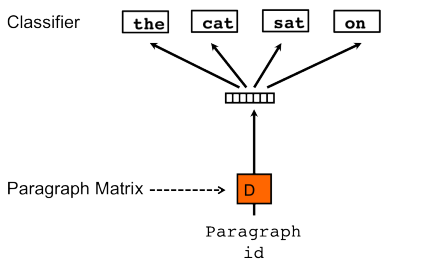
Doc2vec是基于Word2Vec的方法,在Word2Vec架构中有两个算法:连续词袋(CBOW)和Skip-gram(SG)。而在Doc2vec架构中也有两个算法与之相似的算法它们是分布式存储(DM)和分布式词袋(DBOW).
分布式词袋(DBOW)
我们将首先使用Doc2vec的DBOW算法,它类似于word2vec中的Skip-gram算法。 通过训练神经网络来获得文档向量,该神经网络用于预测段落中的单词的概率分布,给出来自段落的随机采样的单词。我们将使用下列DBOW算法的参数:
- dm=0 : 使用Doc2vec的DBOW算法,如果dm=1 使用DM算法。
- min_count=2 : 忽略词频小于2的词语。
- negative=5 : 将使用负采样,并指定应绘制多少“噪音词”(通常在5-20之间)。 如果设置为0,则不使用负采样。
- hs=0 : 如果设置为0,则负数将不为零,负采样将会用到。
- sample=0 : 配置哪些高频词随机下采样的阈值,可以用范围是(0,1e-5)。
- workers=cores : 指定多少个工作线程来训练模型(在多核CPU上训练,速度更快)。
#CPU内核数
cores = multiprocessing.cpu_count()下面开始创建词汇表
from gensim.models import Doc2Vec
from tqdm import tqdmmodel_dbow = Doc2Vec(dm=0, negative=5, hs=0, min_count=2, sample = 0, workers=cores)
model_dbow.build_vocab([x for x in tqdm(train_tagged.values)])![]()
训练模型
下面我们开始训练模型,我对模型进行30个周期的训练:
%%time
for epoch in range(30):model_dbow.train(utils.shuffle([x for x in tqdm(train_tagged.values)]), total_examples=len(train_tagged.values), epochs=1)model_dbow.alpha -= 0.002model_dbow.min_alpha = model_dbow.alpha
我们完成了dbow模型训练耗时1分15秒。
创建特征集
这里有些概念需要陈清一下,我们的模型dbow并不是用来预测的,训练模型的目的仅仅是让dbow可以生成文本的特征向量,其作用类似于Sklearn的CountVectorizer和TfidfTransformer。 模型训练完成以后就可以创建文本的特征向量。
def vec_for_learning(model, tagged_docs):sents = tagged_docs.valuestargets, regressors = zip(*[(doc.tags[0], model.infer_vector(doc.words, steps=20)) for doc in sents])return targets, regressorsy_train, X_train = vec_for_learning(model_dbow, train_tagged)
y_test, X_test = vec_for_learning(model_dbow, test_tagged)预测
有了特征向量,接下来我们可以进行预测了,我们使用sklearn的逻辑回归来进行训练和预测。
#使用逻辑回归来预测
logreg = LogisticRegression(n_jobs=1, C=1e5)
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)评估
预测完成以后,接下来我们对预测结果进行评估
from sklearn.metrics import accuracy_score, f1_scoreprint('Testing accuracy %s' % accuracy_score(y_test, y_pred))
print('Testing F1 score: {}'.format(f1_score(y_test, y_pred, average='weighted')))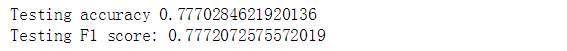
准确率为77%,这个成绩还算只能算一般般,在我之前的博客中 我们用TfidfVectorizer分别在朴素贝叶斯、逻辑回归、支持向量机进行了预测和评估,其中其中逻辑回归和支持向量机的预测准确率都在80%以上,有心的读者可以将DBOW模型的特征向量在别的分类器上测试一下,看看效果如何。
分布式存储(DM)
接下来我们将使用Doc2vec的DM算法,它类似于word2vec中的CBOW算法。回我们将dm参数设置为1,同样在训练30个周期
model_dmm = Doc2Vec(dm=1, dm_mean=1, window=10, negative=5, min_count=1, workers=5, alpha=0.065, min_alpha=0.065)
model_dmm.build_vocab([x for x in tqdm(train_tagged.values)])%%time
for epoch in range(30):model_dmm.train(utils.shuffle([x for x in tqdm(train_tagged.values)]), total_examples=len(train_tagged.values), epochs=1)model_dmm.alpha -= 0.002model_dmm.min_alpha = model_dmm.alpha
训练dm模型耗时3分9秒,这个要比前面训练dbow要慢一些。 接下来我们进行一下预测和评估:
y_train, X_train = vec_for_learning(model_dmm, train_tagged)
y_test, X_test = vec_for_learning(model_dmm, test_tagged)logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)print('Testing accuracy %s' % accuracy_score(y_test, y_pred))
print('Testing F1 score: {}'.format(f1_score(y_test, y_pred, average='weighted')))![]()
我们看到结果很不理想,准确率只有33.8%
合成一个新模型
在Gensim Doc2Vec Tutorial on the IMDB Sentiment Dataset教程中提到一个新的方法,就是将分布式存储(DM)和分布式存储(DM)合成为一个新模型,然后再用这个新模型来创建文档特征向量,据说这样能提高模型的性能,我们也来试一下吧。
首先,我们删除临时训练数据以释放RAM。
model_dbow.delete_temporary_training_data(keep_doctags_vectors=True, keep_inference=True)
model_dmm.delete_temporary_training_data(keep_doctags_vectors=True, keep_inference=True)然后我们合成一个新模型:
from gensim.test.test_doc2vec import ConcatenatedDoc2Vec
new_model = ConcatenatedDoc2Vec([model_dbow, model_dmm])接下来我们创建文档向量
def get_vectors(model, tagged_docs):sents = tagged_docs.valuestargets, regressors = zip(*[(doc.tags[0], model.infer_vector(doc.words, steps=20)) for doc in sents])return targets, regressorsy_train, X_train = get_vectors(new_model, train_tagged)
y_test, X_test = get_vectors(new_model, test_tagged)最后我们来预测和评估一下新模型的表现
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)print('Testing accuracy %s' % accuracy_score(y_test, y_pred))
print('Testing F1 score: {}'.format(f1_score(y_test, y_pred, average='weighted')))
似乎真的有改善,新模型的准确率比之前的分布式词袋(DBOW)模型提高了1%
总结
今天我们学习了另一种文档表示法:Doc2vec,其中包含了2个算法:分布式词袋(DBOW)和分布式存储(DM)。在我们的数据集上经过测试后发现DBOW的表现要优于DM,但是将这两个模型合成一个新模型后,新模型的表现又比DBOW要好一些。总之如果大家还想更深入了解doc2vec的话请研读gensim的教程。
完整代码可以在此下载