word2vec 与 doc2vec的区别:
两者从字面意思上就可以大致判断出区别来,word2vec主要针对与单词,而doc2vec主要针对于文本:
顾名思义,Word2Vec是在单个单词上训练的,而Doc2vec是在可变长度的文本上训练的,因此,每个模型可以完成的任务是不同的。使用Word2Vec,您可以根据上下文预测单词,反之则可使用Vera,而使用Doc2vec则可以测量完整文档之间的关系。
概述:
文本向量化是自然语言处理中的基础工作,文本的表示直接影响到了整个自然语言处理的性能。
最简单的文本向量化方式是采用one-hot的词袋模型(Bag of word)进行,将单词转换成独热编码,但是维度过大所以渐渐的出现了很多新的方法:word2vec 与 doc2vec
Bag of word的缺点:
- 维度灾难
- 无法保留词序的信息
- 存在语义鸿沟(相同的单词往往在不同的句子中有不同的意思)
word2vec
Word2vec 是 Word Embedding 的方法之一,他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
在 Word2vec 出现之前,已经有一些 Word Embedding 的方法,但是之前的方法并不成熟,也没有大规模的得到应
Word Embedding?
word embedding 是文本表示的一类方法。跟 one-hot 编码和整数编码的目的一样,不过他有更多的优点。

- 他可以将文本通过一个低维向量来表达,不像 one-hot 那么长。
- 语意相似的词在向量空间上也会比较相近。
- 通用性很强,可以用在不同的任务中。
Word Embedding三种方法
- Frequency based Embedding:
a. Count Vectors
b. TF-IDF
c. Co-Occurrence Matrix
- Prediction based Embedding(word2vec)
a. CBOW
b. Skip-Gram
- gloVe(Global Vector)
Count Vectors: 通过向量基于每个单词的频率
Document1 = ‘He is a lazy boy. She is also lazy.’
Document2 = ‘Neeraj is a lazy person.’

TF-IDF:它表示单词对文档的贡献,即与文档相关的单词应经常使用。例如:有关Messi的文件应包含大量“Messi“字样。

- IDF = log(N/n), (N为文本数量,n为在多少个文本出现)
- IDF(This) = log(2/2) = 0.
- IDF(Messi) = log(2/1) = 0.301.
- TF-IDF(This,Document1) = (1/8) * (0) = 0
- TF-IDF(This, Document2) = (1/5) * (0) = 0
- TF-IDF(Messi, Document1) = (4/8)*0.301 = 0.15
Co-Occurrence Matrix:具有上下文窗口的统计方法
主要使用PCA,SVD的方法起义分解,得到分解矩阵,好处在于可以更好的联系句子中单词之间的关系。

word2vec详细
CBOW
通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。cbow输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量,即先验概率。
训练的过程如下图所示,主要有输入层(input),映射层(projection)和输出层(output)三个阶段。

Skip-gram
用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。

Negative Sampling(负采样)
传统的神经网络模型(NNLM):

在word2vec中我们预测的是当前单词与其他单词的一起出现的概率,每一个单词与多个单词形成组合形成了大量的分类,导致计算复杂,为了简化计算,采用负分类的是想,将公式转化,通过判断两个单词的组合是否正确将问题转换为二分类问题
负采样主要思想:将多分类的softmax转成二分类的sigmoid。
以“今天|天气|非常|不错|啊”举例,假设上下文只有一个词,选择目标词是“天气”,那么出现的情况有:今天|天气,非常|天气,不错|天气,啊|天气由于我们假设上下文只有一个词,那么在这些情况中只有【今天|天气,非常|天气】是正确的样本。当我们采用【今天|天气】这个样本时,我们希望输入【天气】,会输出标签【今天】,其他概率都是0。
对于原始的skip-gram模型来说,这对应是一个4分类问题,当输入【今天|天气】时,那么我们可能出现的概率是P(今天|天气)、P(非常|天气)、P(不错|天气)和P(啊|天气),我们的目标就是让P(今天|天气)这个概率最大,但是我们得同时计算其他三类的概率,并在利用反向传播进行优化的时候需要对所有词向量都进行更新。这样计算量很大,比如我们这里就要更新5*100=500个参数(假设词向量维度是100维的)。
但是如果采用负采样,当输入【今天|天气】时,我们从【非常|不错|啊】中选出1个进行优化,比如【不错|天气】,即我们只需计算P(D=1|天气,今天)和P(D=0|天气,不错),并且在更新的时候只更新【不错】、【天气】和【今天】的词向量,这样只需更新300个参数,计算量大大减少了。
参考:https://www.cnblogs.com/linhao-0204/p/9126037.html
GloVe?
正如论文的标题而言,GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。我们通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性。
步骤:
- 根据语料库构建一个共现矩阵矩阵中的每一个元素Xij代表单词i和上下文单词j在特定大小的上下文窗口(context window)内共同出现的次数。
- 构建词向量和共现矩阵的关系
- 构造损失函数
- 训练(看似无监督训练,其实在训练的过程中提供了共现矩阵中的值,这些值是通过训练集的样本计算而来的。)
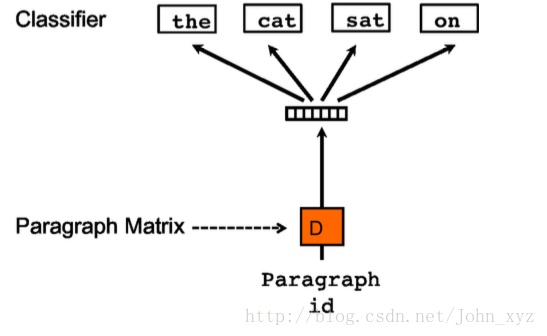
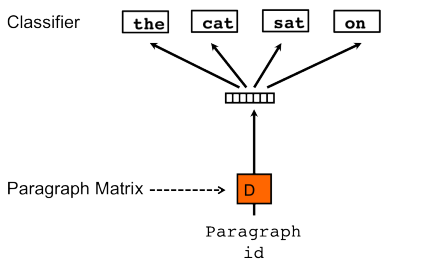
dec2vec?
dec2vec是wordvec的衍生,它主要用于对句子的分类上,word2vec将词语分类后,给每个句子创建一个id,通过id和词语进行进一步的训练,将句子分类,从而达到分句的效果。
汇总: