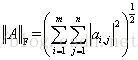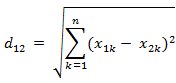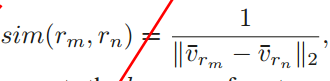欧式距离,l2范数,l2-loss,l2正则化
- 1.欧氏距离
- 2.L2范数
- 范数计算公式
- L1范数L2范数在机器学习方面的区别
- 为什么L2范数可以防止过拟合?
- 3.L2-Loss
- 4.L2正则化
- 正则化
- L2正则化
- 参考文献
1.欧氏距离
距离度量(Distance)用于衡量个体在空间上存在的距离,距离越远说明个体间的差异越大。欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。欧氏距离又称欧几里得距离或欧几里得度量,它是欧几里得空间中两点间“普通”(即直线)距离。使用这个距离,欧氏空间成为度量空间。相关联的范数称为欧几里得范数(Euclidean norm)。
欧氏距离公式如下:

因为计算是基于各维度特征的绝对数值,所以欧氏度量需要保证各维度指标在相同的刻度级别,比如对身高(cm)和体重(kg)两个单位不同的指标使用欧式距离可能使结果失效。
2.L2范数
范数是具有“长度”概念的函数。在向量空间内,为所有的向量的赋予非零的增长度或者大小。不同的范数,所求的向量的长度或者大小是不同的。
L1范数是指向量中各个元素绝对值之和,L2范数定义为向量所有元素的平方和的开平方。
常用到的几个概念,含义相同:
欧几里得范数(Euclidean norm) ==欧式长度 =L2 范数 ==L2距离
范数计算公式
对于 x ∈ R n , y ∈ R n \mathbf{x} \in R^n, \mathbf{y} \in R^n x∈Rn,y∈Rn,
- x 的 L 2 范 数 \mathbf{x}的L2范数 x的L2范数定义为:
∥ x ∥ 2 = ∑ i n x i 2 = x 1 2 + x 2 2 + . . . + x n 2 \left\|\mathbf{x}\right\|_2 =\sqrt{\sum^n_i{x_i^2}} = \sqrt{x_1^2+x_2^2+...+x_n^2} ∥x∥2=i∑nxi2=x12+x22+...+xn2 - x , y 的 L 2 范 数 \mathbf{x,y}的L2范数 x,y的L2范数定义为:
∥ x , y ∥ 2 = ∑ i n ( x i − y i ) 2 \left\|\mathbf{x,y}\right\|_2 =\sqrt{\sum^n_i{(x_i-y_i)^2}} ∥x,y∥2=i∑n(xi−yi)2
对于两个向量,L2范数可认为是空间汇中两点的距离。
L1范数L2范数在机器学习方面的区别
- L1范数可以进行特征选择,即让特征的系数变为0。
- L2范数可以防止过拟合,提升模型的泛化能力,有助于处理 condition number不好下的矩阵(数据变化很小矩阵求解后结果变化很大)。(核心:L2对大数,对outlier离群点更敏感!)
- 下降速度:最小化权值参数L1比L2变化的快。
- 模型空间的限制:L1会产生稀疏 L2不会。
- L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。
为什么L2范数可以防止过拟合?
在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”。L2范数强大功效是改善机器学习里面一个非常重要的问题:过拟合。
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的哦。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。为什么越小的参数说明模型越简单?一种理解是:“限制了参数很小,实际上就限制了多项式某些分量大小,使分量的影响很小,这样就相当于减少参数个数”。
3.L2-Loss
l2-loss也叫平方损失函数,均方误差(MSE),二次损失,L2损失。
均方误差是最常用的回归损失函数,它是我们的目标变量和预测值的差值平方和。

4.L2正则化
正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况。正则化是机器学习中通过显式的控制模型复杂度来避免模型过拟合、确保泛化能力的一种有效方式。如果将模型原始的假设空间比作“天空”,那么天空飞翔的“鸟”就是模型可能收敛到的一个个最优解。在施加了模型正则化后,就好比将原假设空间(“天空”)缩小到一定的空间范围(“笼子”),这样一来,可能得到的最优解能搜索的假设空间也变得相对有限。有限空间自然对应复杂度不太高的模型,也自然对应了有限的模型表达能力。这就是“正则化有效防止模型过拟合的”一种直观解析。

L2正则化
在深度学习中,用的比较多的正则化技术是L2正则化,其形式是在原先的损失函数后边再加多一项: 1 2 λ θ i 2 \frac{1}2λθ^2_i 21λθi2,那加上L2正则项的损失函数就可以表示为:
L ( θ ) = L ( θ ) + λ ∑ i n θ i 2 \mathbf{L}(θ)=\mathbf{L}(θ)+λ\sum^n_i{θ^2_i} L(θ)=L(θ)+λi∑nθi2
其中θ就是网络层的待学习的参数,λ则控制正则项的大小,较大的取值将较大程度约束模型复杂度,反之亦然。
L2约束通常对稀疏的有尖峰的权重向量施加大的惩罚,而偏好于均匀的参数。这样的效果是鼓励神经单元利用上层的所有输入,而不是部分输入。所以L2正则项加入之后,权重的绝对值大小就会整体倾向于减少,尤其不会出现特别大的值(比如噪声),即网络偏向于学习比较小的权重。所以L2正则化在深度学习中还有个名字叫做“权重衰减”(weight decay),也有一种理解这种衰减是对权值的一种惩罚,所以有些书里把L2正则化的这一项叫做惩罚项(penalty)。
我们通过一个例子形象理解一下L2正则化的作用,考虑一个只有两个参数 w 1 w_1 w1和 w 2 w_2 w2的模型,其损失函数曲面如下图所示。从a可以看出,最小值所在是一条线,整个曲面看起来就像是一个山脊。那么这样的山脊曲面就会对应无数个参数组合,单纯使用梯度下降法难以得到确定解。但是这样的目标函数若加上一项 0.1 × ( w 1 2 + w 2 2 ) 0.1×(w^2_1+w^2_2) 0.1×(w12+w22),则曲面就会变成b图的曲面,最小值所在的位置就会从一条山岭变成一个山谷了,此时我们搜索该目标函数的最小值就比先前容易了,所以L2正则化在机器学习中也叫做“岭回归”(ridge regression)。

参考文献
[1] https://blog.csdn.net/rocling/article/details/90290576
[2]L1正则化和L2正则化 https://www.cnblogs.com/skyfsm/p/8456968.html
[3]L1正则化和L2正则化 https://www.jianshu.com/p/76368eba9c90
[4]L1范数与L2范数的区别 https://blog.csdn.net/rocling/article/details/90290576
[5]机器学习之欧式距离和相似度 https://blog.csdn.net/wangdong2017/article/details/81302799