结合 Prophet 的原理理解 Prophet 的使用
前言
本文也是时序领域工作学习过程中的一些学习笔记,将会结合 Prophet 的原理,讲一讲如何成为一个合格的 Prophet 调包侠 使用者。如果有任何理解不到位的地方,请多多指正。
Why Prophet?
Prophet 是Meta(Facebook)的一个开源时序预测算法工具,在工作中解决一些特定领域的时序预测问题时能够有非常好的效果,尤其是一些周期性明显的时序数据,如工业场景、运维场景的数据。
-
优势在于准确度高、能够提供预测区间而非单个预测值、具有良好的可解释性、能够通过设置参数的方式方便地融入业务领域的专家知识;
-
缺点在于对比较复杂没什么规律的时序预测能力比较差,此外,一个 prophet 模型只能预测一条时序,如果有多条时序需要预测,则需要每条时序都训练一个 Prophet model,并且在预测时,每条时序的 Model 都应该重新训练再预测(尽管官方提供了 warm-starting 的方法,在面对大量时序需要预测的场景,不一定适合)
Prophet 的原理
简单来说,Prophet 把时序分为四个部分,认为任意时刻的值,就是这四个部分相加的结果(如果是四个部分相乘的情况,通过 log transform 也同样变为加法模式)。这四个部分分别是:
- 趋势成分:时序最内核的一个增长趋势
- 季节性成分:时序中跟时间强烈相关,周期性上升下降的成分
- 节假日影响:时序中跟时间强烈相关,非周期性出现的影响
- 不可预测的假设为正态分布的误差部分

接下来就看看每个成分分别是如何拟合的
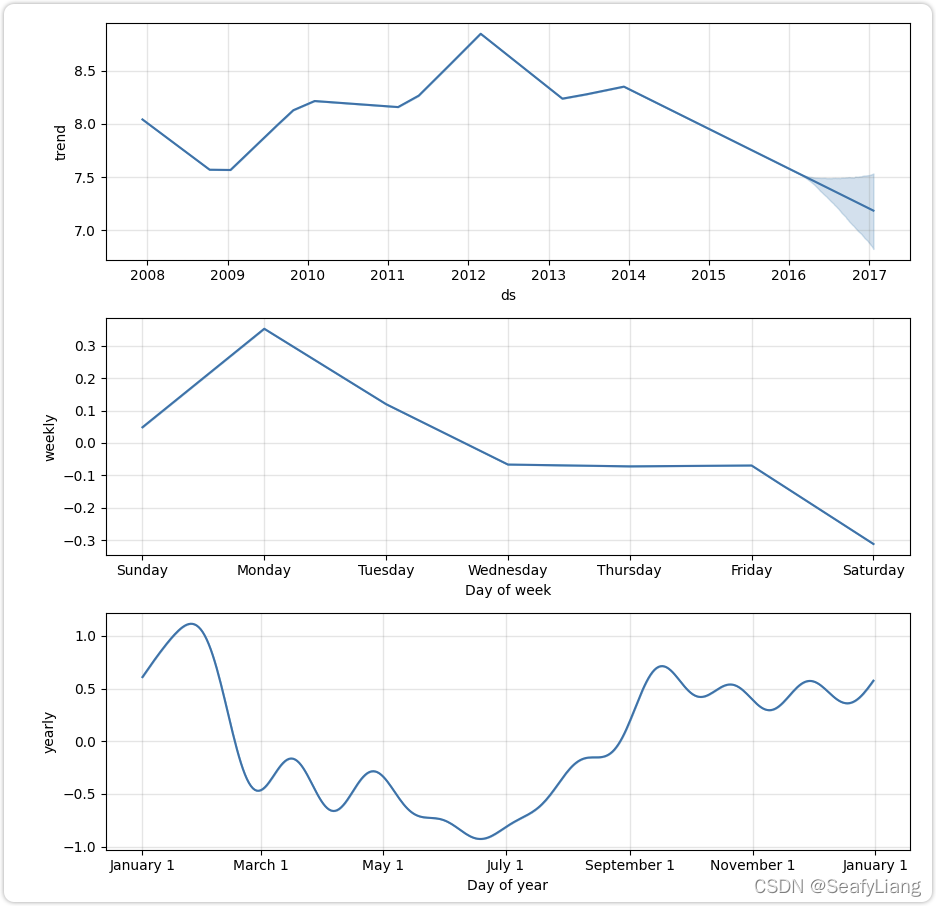
趋势成分
prophet 把趋势成分分为两类,一类是受到人口增长模型启发的 logistics 增长函数,一类是更为简单的分段线性函数
基于人口增长模型的 logistics 增长函数

其中最关键的是增长上限C(t)和增长变化率k
prophet 认为时序在每个时刻的增长上限都是不同的,而这是和时序代表的业务知识强烈相关的,比如产品的需求量的时序,在进行预测时,每个成熟的业务员,都比程序员更懂得如何推算这个产品未来的市场蛋糕到底有多大,天花板在哪里,所以这部分往往是需要业务人员帮助给出的专家经验。
同样,prophet 认为增长率 k 也不是一个固定的值,在某些事件出现的时刻,比如产品广告上线、产品活动,这些特殊的事件发生点,其增长率也不能用日常的情况来代表,这些时刻被称为 changepoints。这些 changepoints 可以由业务人员给出,prophet 也提供了自动寻找的功能,在自动寻找时,prophet 在整个时序上找到一些点标为 changepoints,然后在 Laplace 分布上采样,作为该 changepoints 对应的 k 的变化值,即 k 在这个 changepoint 上要变化多少。Laplace 分布和正态分布长得非常像,这里的方差可以人为调整,于是我们就能根据时序的实际情况,决定 changepoint 上的变化程度。
分段线性函数增长
分段线性函数则简单许多,同样确定了 changepoints 之后,只是在 changepoints 之间构建线性函数,保证它们连续即可,整体就是 y = kx + b,细节这里不详细叙述。

趋势成分的预测
涉及到 changepoints 的话,未来也同样是有 changepoints 的,同样地,可以通过人为给出,也可以依赖 prophet 的自动寻找能力。
prophet 的自动寻找是以“未来的 changepoints 和过去差不多”为前提的,比如我们的时序一共有 T 个点,其中有 S 个 changepoints,那么在预测未来的 H 个点时,每个点都有 S/T 的概率被标记为 changepoint,其相应的变化值也是从 Laplace 分布上采样而来,只是这里的 Laplace 分布的方差,则通过历史中 S 个 changepoints 的方差计算而来,当然也可以用其他更严谨的统计方法,计算历史 changepoints 对应 k 变化值的 Laplace 分布方差。
此时,如果采样多组,那么就能计算得到多个可能的趋势,这些趋势能够构成一定的区间,通过不同时刻的区间的相对宽窄,能够反映该时刻的预测的置信程度
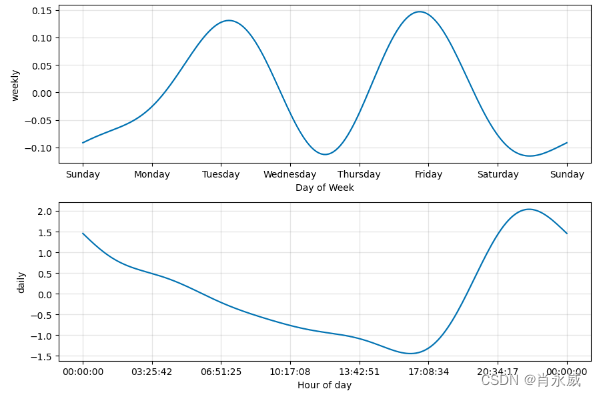
季节性成分
Prophet 通过 Fourier 变换拟合季节性成分,这里我们只需要知道,季节性成分都是周期性的,一个时序最后呈现的形态,可能是多种不同周期的季节性成分作用到趋势成分上导致的结果,而每一种周期的季节性成分,都可以用一组正弦波的叠加去拟合

这样一组正弦波需要 2N 个参数,在变换的过程中都会算出来,但我们需要决定一个 N,来保证拟合的准确度的同时,防止过拟合,也减少算力的压力。Prophet 发现,对于以年为周期的成分,使用 N=10;对于以周为周期的成分,使用 N=3,都能在大部分问题上取得不错的效果,不过我们也可以通过 AIC 这类方法,辅助选择模型的超参数。此外,prophet 还对这 2N 个参数进行高斯平滑,这个平滑的程度也会决定季节性成分变化的速度,同样可以通过这个参数调控季节性成分的强度,即对时序最终的形态的影响



节假日成分
还有一些和时间紧密相关的事件,比如某些节假日,从漫长的时间尺度上来说,并不是周期性出现的,但是符合一定的出现规则。这样的重要影响则通过数据表的形式喂入模型,如一张列名为 [节假日的名字, 国家, 年份, 日期] 的表。
prophet 统计每个节假日出现的时间,给每种节假日都附加一个影响值 k (从正态分布采样),在每个节假日对应时刻(或节假日为中心的一个窗口内的所有时刻)都增加一个节假日的影响值,作为 h(t) 的值
模型的评估与分析
参考 Prophet 的官网,通过 Prophet 的 API 即可完成上述成分的拟合,但 prophet 还提供了后续分析模型效果的思路。
baseline
模型的评估都离不开 baseline 的比较,通常选择 last value 或者 sample mean 作为 baseline,这方面无需详述
评估指标
对于一个 H 个点的预测,它的误差等于这 H 个点构成的向量,和真实值向量之间的“距离”。“距离”的计算方式有很多,需要根据实际问题来选择,比如时序预测问题常用的 MAPE 就也算是一种计算的方式
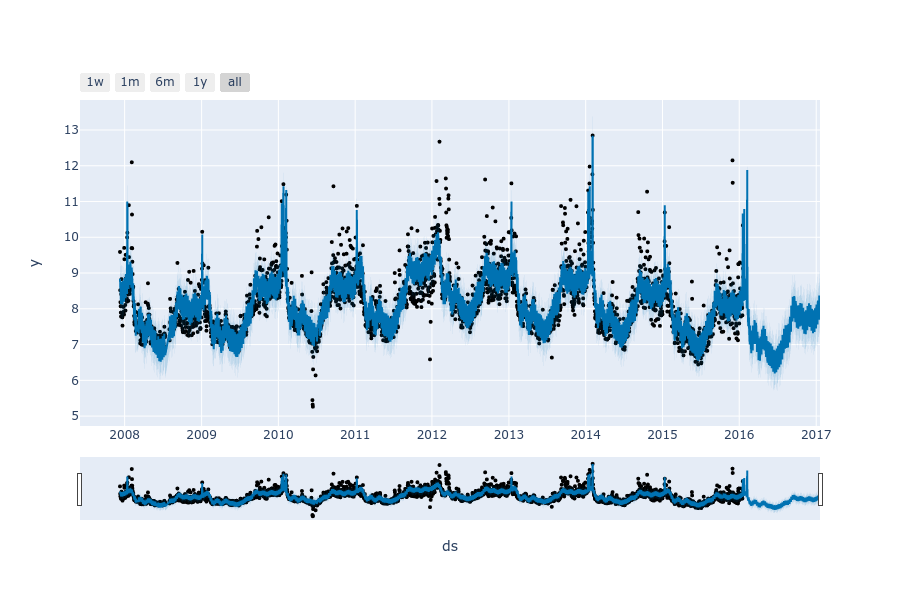
可视化
prophet 推荐使用点的方式绘图,避免连线造成的插值感
-
SHF(simulated historical forecasts)
prophet 提出,不光要算一个 H 下的准确度,还要算多个不同大小的 H 下的准确度,以求更全面的反映一个模型的表现,达到普通的机器学习任务中 cross-validation 同样的效果 (因为时序的先后顺序是严格约束的,不能像普通的机器学习任务一样,在全部的训练样本上随机的 cross-validation )
SHF 就是在历史中的某几个点上,用点之前的数据 fit,对点之后的 H 个点进行 predict。比如设置 N 个点,我们称为 cutoff,每个 cutoff 处都用之前的数据训练,对之后的 H 个点预测,这 N 个地方的结果的期望,就是模型对于 H 这个 forecast horizon 时的比较客观的表现

通过多设置这样的 cutoff 时刻,记录每个 cutoff 处的 SHF,会有更多角度的分析:
- 相比 baseline 模型有明显差距时,说明模型可能定义的参数不对
- 某时刻,几乎所有模型都表现很差时,说明可能是异常值,需要重新处理训练数据
- 当某一个 cutoff 处的“距离”相比上一个 cutoff 显著变大,说明可能这之间有一个没有被捕捉到的changepoints或者忽视了什么季节性成分、非周期事件影响,同样需要重新审视模型
Prophet 的使用
-
首先,大家可能会发现找不到 prophet 的 API reference,这可能是因为项目最初是围绕着 R 语言构建的,R 语言能够很方便地自动生成 API 文档:Prophet API 文档-R 语言
因此,这里更推荐在 notebook 或者别的地方使用 prophet 的时候,使用 help() 的方式,查阅 API 的说明

比如不知道 cross-validation 怎么用于和官网不同的非日期间隔数据,就可以使用
help(prophet.diagnostics.cross_Validation)
-
可以看到几个参数都对应我们上面描述过的原理
- growth : linear 还是 logistic,对应我们说的两类趋势成分的分类
- C(t) 是通过在时序数据增加一列 ‘cap’ 实现的,给出每个时刻对应的增长上限,具体官网就有说明。值得注意的是,如果你添加了 cap 列,在使用 make_future_dataframe 的时候,也应该加上这一列
- changepoints:list of dates,对应的就是人为指出 changepoints 的方式
- n_changepoints 默认为25,changepoints_range默认为0.8,表示默认情况下,prophet 会在输入的数据的前百分之80个店里面选25个作为变点,变化值对应changepoint_prior_scale决定的Laplace分布上采样的值
- changepoint_prior_scale:对应前面提到的 Laplace 分布的方差,调大会导致 changepoint 处的 k 的变化值比较容易出现大的值,从而导致整个 trend 变化比较大,导致趋势成分更 flexible
- seasonality 部分我们提到 N 和平滑这些参数的正态分布的方差
- yearly_seasonlaity, weekly_seasonality 等,都可以指定一个数值代表 N。如果我们的时序是非日期数据,还可以通过 Prophet().add_seasonlaity 函数添加一个成分,指定它的周期,并指定 N 表示要用多少阶 Fourier 去拟合它
- 而平滑用的正态分布,对应 seasonality_prior_scale
- 节假日影响则通过 holidays 参数给出,如前文所述,需要提供一个表示节假日的pd.DataFrame
- holiday 列:如 ‘mid-autumn’ 这样的节假日名字
- ds 列:日期,但需要是 date type 的数据,不能是字符串
- [lower_window] ([]表示可选):整数,如 -2 表示日期之前的两天,也视为该节日,受到同等影响
- [upper_window]: 同理
- prior_scale:对应前文提到的“影响值 k 从正态分布中采样”,本参数就是确认这个正态分布的方差的
-
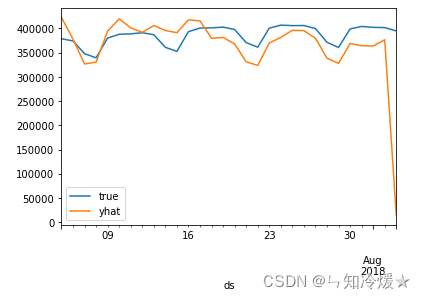
在可视化的时候,直接使用 prophet 提供的 plot,往往没有测试集的真实值在图上,因为我们一般在训练之前就会把测试集分出来,此时可以传入 ax,以供我们继续在 prophet 画的图上补真实值的线
fig, ax_tar = plt.subplot() model.plot(res, figsize=(20, 10), ax=ax_tar) data[-periods:].plot(kind='scatter', x='ds', y='y', color='lightcoral', alpha=0.5, ax=ax_tar)
Reference
-
Prophet doc
-
Taylor SJ, Letham B. 2017. Forecasting at scale. PeerJ Preprints 5:e3190v2 https://doi.org/10.7287/peerj.preprints.3190v2