add by zhj: 不同操作系统下换行符不同,如下:
\n: UNIX
\n\r: window
\r: MAC OS
我们经常遇到的一个问题就是,Unix/Mac系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix/Mac下打开的话,在每行的结尾可能会多出一个^M符号。
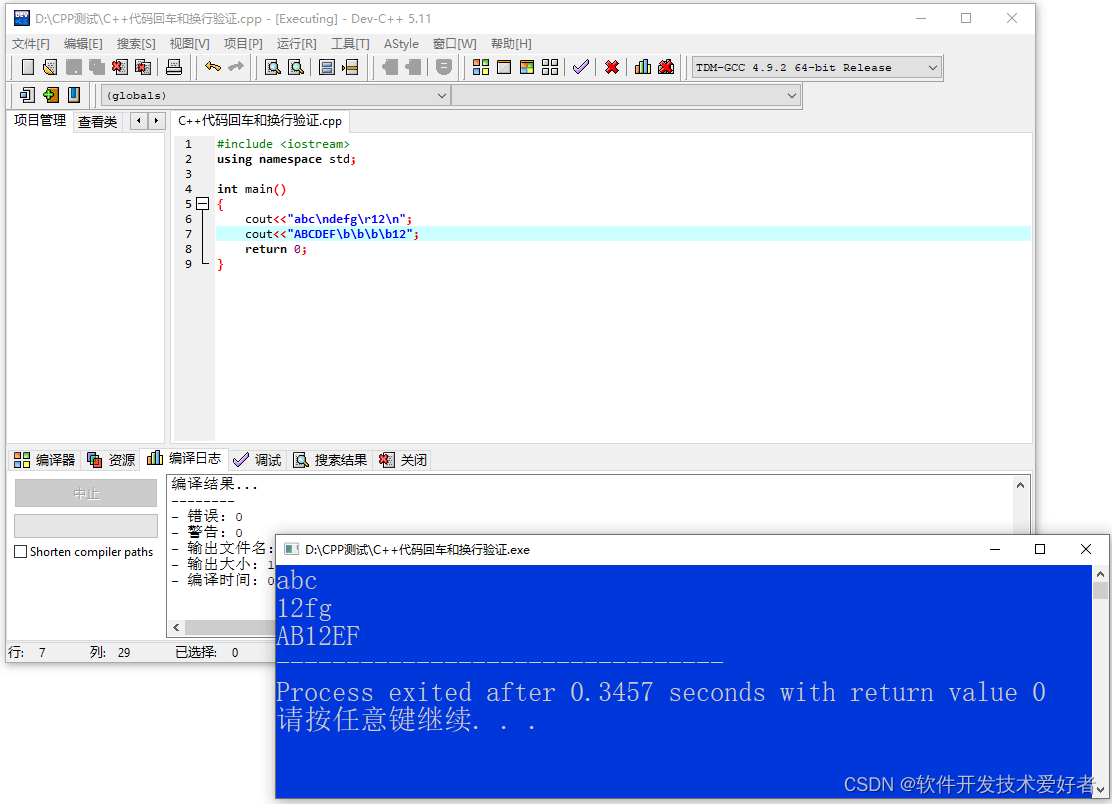
在输入文本时,回车键一敲,就开始了新的一行,这个习惯性用法难免误导 C/C++ 的初学者们对 回车符(CR, Carriage Return)'\r' 和 换行符(LF, Linefeed)'\n' 的理解,这里这个问题我们暂且放下,后文再谈。先让我们来看看关于“回车”的有趣历史来源。
关于“回车键”的来历,要追朔到机械英文打字机的时代。在这种打字机上有个叫“字车”的部件,大概就是下面那个部分,会左右不停地跑的那东西。

当输满一行后,使用者就要把“字车”推到起始位置,这时打字机就会有两个动作,一是“字车”归位,二是滚筒上卷一行(相当于“字车”下移一行),这样就可以开始输入下一行了,这里推动“字车”的动作就称为“回车”。
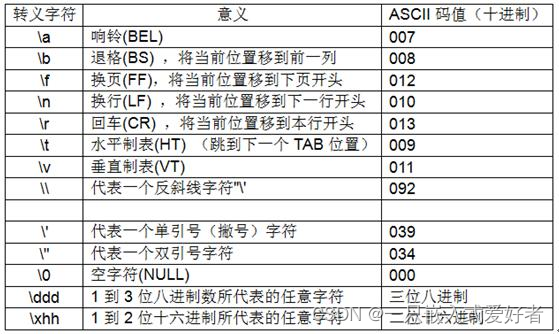
上述打字机的“字符”归位的动作就相当于我们的 回车 '\r',只回到行首而仍在当前行,而滚筒上卷的动作就相当于 换行 '\n',移动到下一行。回车符 '\r' 对应 ASCII 码的16进制是 0x0d,10进制是 13,换行符 '\n' 对应16进制是 0x0a, 10进制是 10。
而不同的系统对回车的处理是不同的:在我们常用的 Windows 系统中用 "\r\n"两个字符来表示,如图,在第一行与第二行之间有两个字符位,分别是 0D 0A,即 ASCII 码对应的 '\r'和'\n'。这样的表示方法就和打字机的行为很相似了。


那么,同样的方法,在 Linux 上会是什么情况呢?请继续看。


在 Linux 上通过 vim 我们看到,在 a, ab, abc 之间只有一个字符位了,对应的是 0a,即 ASCII 码中的 '\n',这就说明在 Linux 上只用了一个换行字符来表示。







![[PTA]习题8-2 在数组中查找指定元素](https://img-blog.csdnimg.cn/1d555e2dc5c94764aff23658e02e9568.png)
![[PTA]实验8-1-5 在数组中查找指定元素](https://img-blog.csdnimg.cn/62eaa40e868542e19bb5291c784c3392.png)