我们在看他们的区别时我们先看看他们的分别指的是什么:
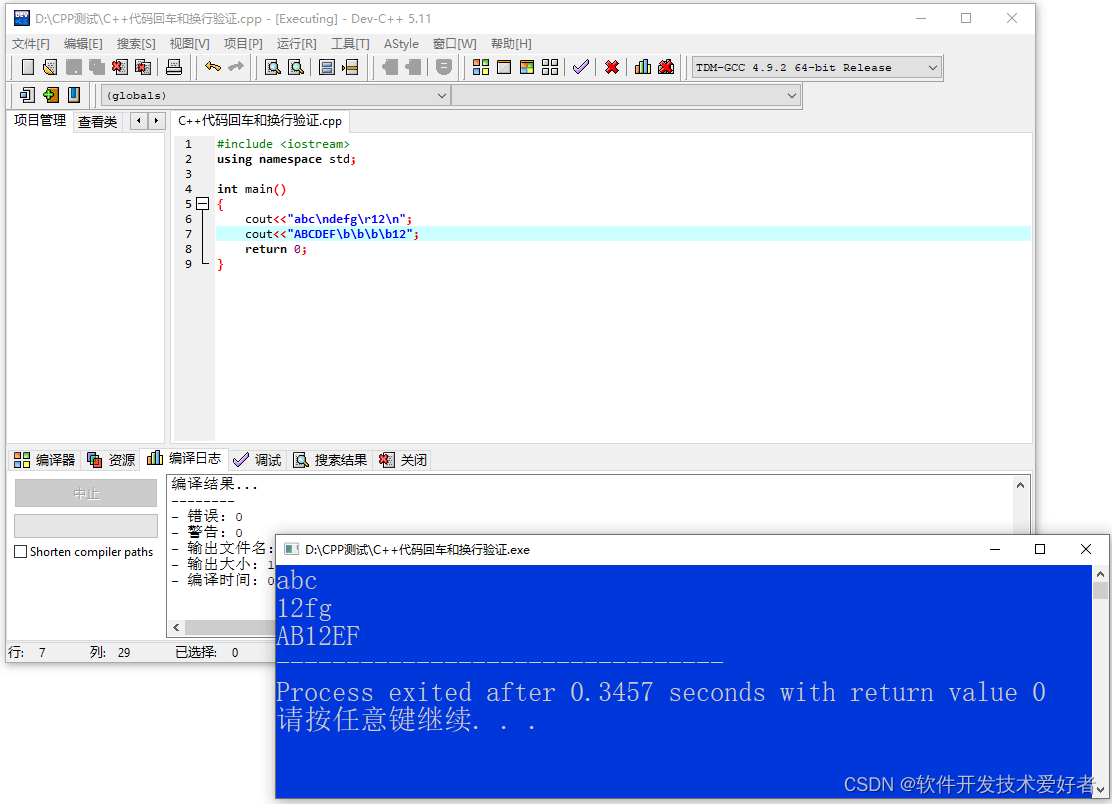
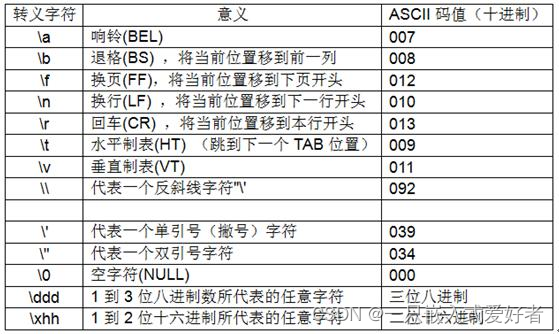
回车<\r>(carriage return):告诉打印机把打印头定位到左边界,就是指的,那个打印头重新放在这一行的开始。
换行<\n>(line feed):告诉打印机把打印头放在所要打印的下一行的行头。
他们的来历我们瞧瞧
在计算机早期还没有出现的时间,在电传打印机出现的时代,每秒钟可以打印10个字符,我们可以想想当时战争年代的电报,它打印时是不是纸一直是不是往上走,这就是因为我们一行打印完,打印头不动,纸往上走,根据牛顿那第三定律吧,打印头就往下走了,就实现了换行的作用了。我们在收到信息时,我们如果收到换行的字符时,我们不打印换行,我们则是将打印头移动换行。

unix系统和winows还有MAC下的区别:
UNIX系统里,每行结尾只有“换行”。\n
windows系统里,每行结尾是“回车”与“换行”结合。\r\n
Mac系统系统里,每行的结尾是“回车”。
出现的后果我们在我indow下的写的文章在linux里打开,每行结尾出现^M。这就是我们那个\r,我们将它删除即可。
Linux文件在windows打开,我们挥发现一大堆乱了。变成了一行。
下面给大家介绍处理办法
windows换行是\r\n,十六进制数值是:0D0A。
LINUX换行是\n,十六进制数值是:0A
所以在linux保存的文件在windows上用记事本看的话会出现黑点,我们可以在LINUX下用命令把linux的文件格式转换成win格式的。
unix2dos 是把linux文件格式转换成windows文件格式
dos2unix 是把windows格式转换成linux文件格式。




![[PTA]习题8-2 在数组中查找指定元素](https://img-blog.csdnimg.cn/1d555e2dc5c94764aff23658e02e9568.png)
![[PTA]实验8-1-5 在数组中查找指定元素](https://img-blog.csdnimg.cn/62eaa40e868542e19bb5291c784c3392.png)