回归- Regression
——————————————————————————————————————————
- 回归- Regression
- 线性回归Linear regression
- 模型表示Model representation
- 代价函数Cost function
- 目标Goal
- 多项式回归
- 加权线性回归
- 一般线性回归
- 通用的指数概率分布
- 伯努利分布
- 高斯分布
- 微分与导数1
- 微分
- 导数
- 方向导数
- 梯度
- 梯度下降算法
- 基本思想
- 流程
- 批量梯度下降
- 随机梯度下降
- 特征归一化
- 步长的选择
- 优缺点
- 随机梯度下降的改进
- 最小二乘法
- 代价函数Cost function
- 求解
- 矩阵不可逆解决方法
- 优缺点
- 逻辑回归 -Logistic regression
- 逻辑回归模型
- 代价函数
- 二分类问题
- 对数似然损失函数
- 优点
- 多类分类问题
- 其他优化算法
- 牛顿法2
- 拟牛顿法3
- DFP算法4
- BFGS算法5
- L-BFGS 算法Limited-memory BFGS6
- Softmax回归7
- 过拟合问题8
- 类别不平衡问题9
- 线性回归Linear regression
线性回归(Linear regression)
线性回归属于监督学习,方法和监督学习是一样的,先给定一个训练集,根据训练集学习出一个线性函数,然后测试这个函数训练的好不好(即此函数是否足够拟合训练集数据),挑选出最好的函数(cost function最小)即可
思想:学习一个线性模型(通过属性的线性组合来进行预测的函数)以尽可能准确的预测实值输出标记
处理:1、值间存在序关系转化为连续值。2、属性值间不存在序关系转化为多维向量。模型表示(Model representation)
因为是线性回归,所以学习到的函数为线性函数,即直线函数
hθ(x)=θ0+θ1x1+...+θnxn
xn 为特征, n 为特征数目,hθ(x) 表示假设函数。为了方便,记 x0=1 ,于是得到:
hθ(x)=∑ni=0θixi=θTx
其中 θ 和 x 都是向量。代价函数(Cost function)
评价线性函数拟合的好不好,我们需要使用到代价函数,代价函数越小,说明线性回归地越好,即和训练集拟合地越好,当然最小就是0,即完全拟合
J(θ)=J(θ0,θ1,…,θn)=12∑mi=0(hθ(x(i))−y(i))2
y(i) 称之为 目标变量; x(i) 为第 i 个训练样本的所有输入特征,可以认为是一组特征向量;m 为训练样本的数目。目标(Goal)
minimizeθJ(θ)
均方误差最小化。
多项式回归
很多时候,线性回归不能很好的拟合给定的样本点
hθ(x)=θ0+θ1(size)+θ2(size)2+θ3(size)3
加权线性回归
在学习过程中,特征的选择对于最终学习到的模型的性能有很大影响,于是选择用哪个特征,每个特征的重要性如何就产生了加权的线性回归。
它的中心思想是在对参数进行求解的过程中,每个样本对当前参数值的影响是有不一样的权重的。
加权线性回归学习过程
Fitθtominimize12∑mi=0wi(y(i)−θTx(i))2OutputθTx与传统的线性回归的区别在于对不同的输入特征赋予了不同的非负值权重,权重越大,对于代价函数的影响越大。
权重计算公式为
w(i)=exp⎛⎝⎜⎜−(x(i)−x)22τ2⎞⎠⎟⎟
其中, x 是要预测的特征,表示离x 越近的样本权重越大,越远的影响越小。理解: x 为某个预测点,
x(i) 为样本点,样本点距离预测点越近,贡献的误差越大,权值越大;越远则贡献的误差越小,权值越小。预测点的选取:可以选取样本点。
算法思路:假设预测点取样本点中的第 i 个样本点,遍历1到
m 个样本点,算出每一个样本点与预测点的距离,就可以计算出每个样本贡献误差的权值,可以看出 w 是一个有m 个元素的向量。代入 J(θ) 中
J(θ)=12∑mi=0wi(y(i)−θTx(i))2=yTwy−θTxTwy−yTwTxθ+θTxTwxθ利用最小二乘法,可以计算出一个 θ 向量
∇θJ(θ)=−xTwy−xTwy+2xTwxθ=0
θ=(xTwx)−1xTwy
一般线性回归
线性回归是以高斯分布为误差分析模型。逻辑回归采用的是伯努利分布分析误差。而高斯分布、伯努利分布、贝塔分布、迪特里特分布,都属于指数分布。
通用的指数概率分布
p(y;η)=b(y)exp(ηTT(y)−a(η))伯努利分布
p(y;ϕ)=ϕy(1−ϕ)1−y=exp(ylog(ϕ)+(1−y)log(1−ϕ))=exp(ylog(ϕ1−ϕ)+log(1−ϕ))高斯分布
p(y;μ)=12π−−√exp(−12(y−μ)2)=12π−−√exp(−12(y)2)exp(μy−12μ2)
——————————————————————————————————————————
微分与导数[1]
微分
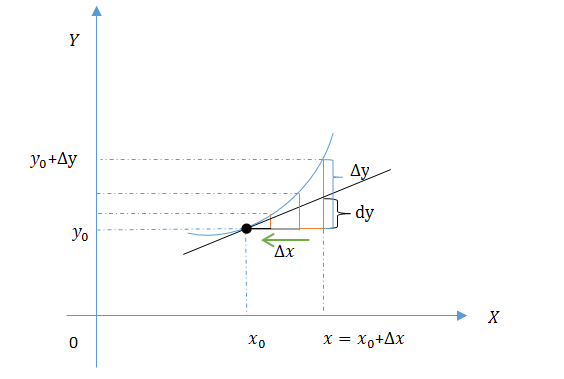
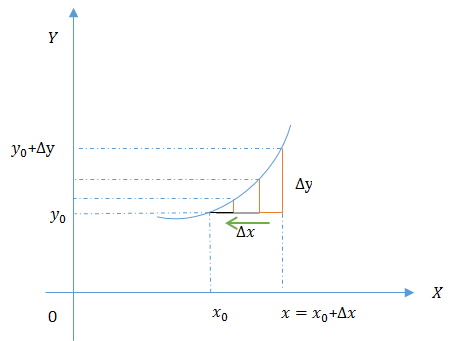
微分描述的是当函数自变量的变化量 Δx 在足够小的改变时函数值的改变情况,是对函数局部变化率的一种线性描述,在足够微小局部,可以用直线去近似代替曲线。
设函数 y=f(x) 在点 x0 的某个邻域内有定义, x0+Δx 也在此区间,当 Δx 在做足够小变化时,若函数的增量 Δy=f(x0+Δx)−f(x0) 可表示为 Δy=AΔx+ο(Δx) (其中 A 是不依赖于
Δx 的常数, ο(Δx) 是 Δx 的高阶无穷小),则称函数 y=f(x) 在 x0 点是可微的, AΔx 称作函数在点 x0 相应于自变量增量 Δx 的微分,记作
dy=AΔx由于 ο(Δx) 是 Δx 的高阶无穷小,所以函数的微分( dy=AΔx )是函数增量( Δy=AΔx+ο(Δx) )的主要部分,且是 Δx 的线性函数,所以函数的微分是函数的线性主部。当 Δx 足够小时记作微元 dx ,实际上由导数的定义可知, A=ΔyΔx|(Δx−>0)=dydx ,所以 dy=f′(x)dx 。
由上述思路可以推广至多元函数的微分。
若二元函数 z=f(x,y) 在点 (x,y) 处的全增量 Δz=f(x+Δx,y+Δy)−f(x,y) 可以表示成 Δz=AΔx+BΔy+ο(ρ) ,其中 ρ=(Δx)2+(Δy)2−−−−−−−−−−−−√ ,A和B不依赖于 Δx 和 Δy 仅与 x,y 有关,则称函数 f(x,y) 在点 (x,y) )可微,将 AΔx+BΔy 称为函数 f(x,y) 在点 x,y 的全微分,记作
dz=df=AΔx+BΔy或者函数 z=f(x,y) 在点 (x,y) 的两个偏导数为 fx(x,y) 和 fy(x,y) 时,
dz=∂z∂xdx+∂z∂ydy=∂f∂xdx+∂f∂ydy=fx(x,y)dx+fy(x,y)dy三元函数的全微分记作
du=∂u∂xdx+∂u∂ydy+∂u∂zdz
导数
导数是函数的局部性质,函数在某点的导数描述了这个函数在这个点的变化率,几何上表现为函数在该点处的切线的斜率。
设函数 y=f(x) 在点 x0 的某个邻域内有定义,当自变量 x 在
x0 处有变化 Δx(Δx=x−x0 , x 也在该邻域内) 时,相应的函数变化 Δy=f(x)−f(x0) ;如果 Δy 与 Δx 之比 ΔyΔx 在 Δx 趋于0时极限存在,则称函数 y=f(x) 在点 x0 处可导,并称这个极限值为函数 y=f(x) 在点 x0 处的导数,记为 f'(x0) ,即
f′(x0)=limΔx→0f(x)−f(x0)x−x0如果函数 y=f(x) 在某开区间内每一点都可导,则称函数 f(x) 在该区间内可导;函数 y=f(x) 对于该区间内的每一个确定的 x 值都对应着一个确定的导数,此时就构成一个新的函数,称这个函数为原函数
y=f(x) 的导函数,简称导数,记作 y'(f'(x),dydx,df(x)dx) 。导数和微分的区别从定义上就可以很清楚了,导数是源自于函数值随自变量增量的变化率,即 ΔyΔx 的极限,而微分则源自于微量的分析,即 Δx 在足够小变化时函数值的变化 Δy 可以表示为 AΔx 和 Δx 的高阶小量 ο(Δx) 之和;导数的值是函数在该点处切线的斜率而微分的值是函数沿切线方向上函数值的增量, dy=f'(x)dx 。
方向导数
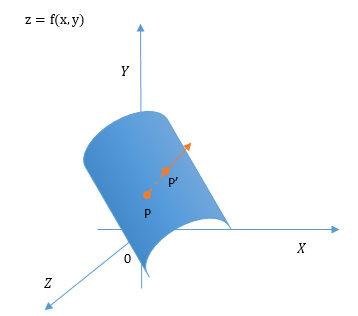
导数描述了函数在某点处的变化率,方向导数顾名思义就是研究函数在一点的某一方向上的变化率。
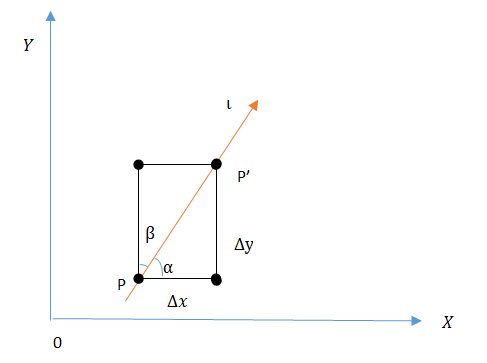
设函数 z=f(x,y) 在点 P(x,y) 的某一邻域 U(P) 内有定义,在 U(P) 内找一方向任意的点 P'(x+Δx,y+Δy) ,从点 P 引射线
l 到 P' 点,设X轴正向到射线 l 的转角为α , Y 轴正向到射线ll的转角位β ,则 cosα 、 cosβ 为 l 方向的方向余弦,即为l 的单位向量 α、β 是 l 的方向角,如下图。
若函数
z=f(x,y) 的增量 Δz=f(x+Δx,y+Δy)−f(x,y) 与 PP' 两点间距 ρ=(Δx)2+(Δy)2−−−−−−−−−−−−√ 之比在 P' 沿着 l⃗ 方向趋于 P 时(ρ−>0 )极限存在,则称这极限为函数在点 P 沿方向l⃗ 的方向导数。记为
∂f∂x|p=limρ→0+f(x+Δx,y+Δy)−f(x,y)ρ偏导数 ∂f∂x=limΔx−>0f(x+Δx,y+y)−f(x,y)Δx , ∂f∂y=limΔy−>0f(x,y+Δy)−f(x,y)Δy 分别是函数在某点沿平行于坐标轴的直线的变化率。
设函数 z=f(x,y) 在点 P(x,y) 处可微,则其增量可以表示为
f(x+Δx,y+Δy)−f(x,y)=∂f∂xΔx+∂f∂yΔy+ο(ρ)两边同除以 ρ 得到
f(x+Δx,y+Δy)−f(x,y)ρ=∂f∂x∙Δxρ+∂f∂y∙Δyρ+ο(ρ)ρ 由下图知 Δxρ=cosα , Δyρ=cosβ ,则
f(x+Δx,y+Δy)−f(x,y)ρ=∂f∂x∙cosα+∂f∂y∙cosβ+ο(ρ)ρ故方向导数
∂f∂l=limρ−>0f(x+Δx,y+Δy)−f(x,y)ρ=∂f∂xcosα+∂f∂ycosβ由上思路推广可得三元函数方向导数
即
∂f∂l=limρ−>0f(x+Δx,y+Δy,z+Δz)−f(x,y,z)ρ=∂f∂xcosα+∂f∂ycosβ+∂f∂zcosγ
∂f∂l=∂f∂xcosα+∂f∂ycosβ+∂f∂zcosγ其中 α、β、γ 为 l 的方向角,
(cosα、cosβ、cosγ) 是 l 的方向向量。

梯度
由上方向导数的定义可知,函数
z=f(x,y) 在某点因为选择的方向不同所以其在该点的方向导数是不相同的,现在思考一个问题:函数沿什么方向的方向导数为最大?我们已经知道函数的方向导数
∂f∂l=∂fxcosα+∂f∂ycosβ设向量 G→=(∂f∂x,∂f∂y) , l0→=(cosα,cosβ) (|l0→|=1) ,则
∂f∂l=∂f∂xcosα+∂f∂ycosβ=G→∙l0→由向量相乘的知识可知,当向量 G→ 和 l0→ 方向一致时,方向导数 ∂f∂l 最大,其最大值为 max∂f∂l=|G→| 。所以函数的方向导数在 G→ 的方向上变化率最大, G→ 的模为最大变化率之值。在几何上向量 G→ 表现为函数等值线上点P处的法向量。
设函数 z=f(x,y) 在点 P(x,y) 处可偏导,称向量 G→ 为函数 z=f(x,y) 在点 P(x,y) 处的梯度(gradient)即
gradf(x,y)=(∂f∂x,∂f∂y)=∂f∂xi→+∂f∂yj→=∇f
梯度下降算法
基本思想
利用负梯度方向来决定每次迭代的新的搜索方向,使得每次迭代能使待优化的目标函数逐步减小。
是利用一阶的梯度信息找到函数局部最优解的一种方法,也是机器学习里面最简单最常用的一种优化方法。流程
1、先确定向下一步的步伐大小,称为Learning rate;
2、任意给定一个 θ 初始值
3、确定一个向下的方向,并向下走预先规定的步伐,并更新; θj4、当下降的高度小于某个定义的值,则停止下降。
特点:1、初始点不同,获得的最小值也不同,因此梯度下降求得的只是局部最小值;2、越接近最小值时,下降速度越慢。
批量梯度下降
先考虑只有一个训练样本的情况
J(θ)=12∑mi=0(hθ(x(i))−y(i))2=12(Xθ−y)T(Xθ−y)∂∂θjJ(θ)=∂∂θj12(hθ(x)−y)2=2∗12(hθ(x)−y)∗∂∂θj(hθ(x)−y)=(hθ(x)−y)∗∂∂θj(∑ni=0θixi−y)=(hθ(x)−y)xj得到跟新规则
θj:=θj−∂∑i=1m(hθ(x(i))−y(i))xj(i)对于如下更新参数的算法: 直接把单个样本代价函数的梯度换为多个样本代价函数的梯度
Repeat{θj:=θj−∂∑i=1m(hθ(x(i))−y(i))xj(i)(simultaneouslyupdateθjforj=0,...,n)}
由于在每一次迭代都考察训练集的所有样本,而称为批量梯度下降 batch gradient descent。随机梯度下降
如果参数更新计算算法如下
loop{fori=1tom,{θj:=θj−∂(hθ(x(i))−y(i))xj(i)(forj=0,...,n)}}这里我们按照单个训练样本更新 θj 的值,称为随机梯度下降 stochastic gradient descent ,属于在线学习算法。 同样也要遍历整个训练集,但和batch gradient descent不同的是,我们每次只使用单个训练样本来更新 α ,依次遍历训练集,而不是一次更新中考虑所有的样本。
特征归一化
核心思想:确保特征在相似的尺度里
目标:使每一个特征值都近似的落在 −1≤xi≤1 的范围内。
作用:加快梯度下降的执行速度
简单的归一化
除以每组特征的最大值均值归一化
用 xi–μi 替换 xi 使特征的均值近似为 0(但是不对 x0=1 处理),均值归一化的公式是
xi←xi–μiSi其中 Si 可以是特征的取值范围(最大值-最小值),也可以是标准差(standard deviation).
步长的选择
如果 α 太小,会收敛很慢
如果 α 太大,就不能保证每一次迭代 J(θ) 都减小,就不能保证 J(θ) 收敛
选择 α 经验的方法: 约3倍于前一个数。开始迭代,学习率大,慢慢的接近最优值时,学习率变小。优缺点
需要选择合适的 learning rate α ;
需要很多轮迭代;
但是即使 n 很大的时候效果也很好;
需要特征归一化随机梯度下降的改进
在每次迭代时,调整更新步长
α 的值, 随着迭代的进行, α 越来越小,这会缓解系数的高频波动每次迭代,改变样本的优化顺序。随机选择样本来更新回归系数。可以减少周期性波动,因为样本顺序改变,使迭代不再形成周期性
——————————————————————————————————————————
最小二乘法
梯度下降算法给出了一种计算 θ 的方法,但需要迭代,比较费时。最小二乘法是一种直接利用矩阵运算可以得到 θ 值的算法
代价函数(Cost function)
将输入特征 x 和对应的结果
y 表示成矩阵形式有:
X=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢(x(1))T(x(2))T⋮(x(m))T⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥,y=⎡⎣⎢⎢⎢⎢⎢y(1)y(2)⋮y(m)⎤⎦⎥⎥⎥⎥⎥对于预测模型有
hθ(x)=∑ni=0θixi=θTx即
hθ(x(i))=(x(i))Tθ于是
Xθ−y=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢(x(1))Tθ(x(2))Tθ⋮(x(m))Tθ⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥−⎡⎣⎢⎢⎢⎢⎢y(1)y(2)⋮y(m)⎤⎦⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢hθ(x(1))−y(1)hθ(x(2))−y(2)⋮hθ(x(m))−y(m)⎤⎦⎥⎥⎥⎥⎥可以得到
J(θ)=12∑mi=0(hθ(x(i))−y(i))2=12(Xθ−y)T(Xθ−y)求解
矩阵运算来得到梯度
∇θJ(θ)=∇θ12(Xθ−y)T(Xθ−y)=12∇θ(θTXTXθ−θTXTy−yTXθ+yTy)=12∇θtr(θTXTXθ−θTXTy−yTXθ+yTy)=12∇θ(trθTXTXθ−2tryTXθ)=12(XTXθ+XTXθ−2XTy)=XTXθ−XTy求 J(θ) 最小值方法是令
ddθjJ(θ)=0然后得到 θ 的值
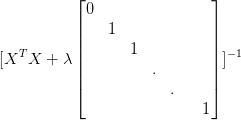
θ=(XTX)−1XTy矩阵不可逆解决方法
在 (XTX) 不可逆的情况下,我们就不能求得最小二乘解。也就是说, X 与
y 之间不存在最优的线性模型。岭回归(Ridge Regression)
虽没有最优解,但可以有很多的近似解。岭回归就是一种求解近似解的方法。岭回归是在平方误差的基础上增加正则项来建立模型,从而使得矩阵非奇异。
J(θ)=12((∑mi=0(y(i)−θTx(i))2)+λθ2)=XTXθ−XTy+λθ
然后得到 θ 的值
θ=(XTX+λI)−1XTy
为了选取最优的 λ 值,可以采取交叉验证法。优缺点
不需要选择 α ;
不需要迭代,一次搞定;
但是需要计算 (XTX)−1 ,其时间复杂度是 O(n3)
如果n很大,就非常慢
不需要特征归一化
——————————————————————————————————————————
逻辑回归 -Logistic regression
逻辑回归常用于垃圾邮件分类,天气预测、疾病判断和广告投放
对于二分类问题来说,线性回归模型的假设函数输出值 hθ(x) 可以大于1也可以小于0。这个时候我们引出逻辑回归,逻辑回归的假设函数输出介于0与1之间,既
0≤hθ(x)≤1逻辑回归模型
假设函数
hθ(x)=g(θTx)
g 称为Sigmoid function 或者Logistic function, 具体表达式为:y=g(z)=11+e−z
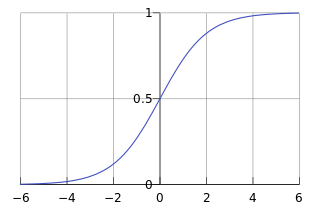
综合上述两式,我们得到逻辑回归模型的数学表达式
hθ(x)=11+e−θTx
其中 θ 是参数直观解释:对Sigmoid function 转化可以得到
lny1−y=θTx
就是用线性回归模型的预测结果逼近真实标记的对数几率。 hθ(x) = 对于给定的输入 x,y=1 时估计的概率
即:hθ(x)=P(y=1|x;θ)代价函数
J(θ)=12∑i=1m(hθ(x(i))–y(i))2
这里取 hθ(x)=11+e−θTx ,会存在一个问题,也就是逻辑回归的代价函数是“非凸”的。所以需要其他形式的代价函数来保证逻辑回归的成本函数是凸函数。二分类问题
对于因变量 y=0 或 1 这样的二分类问题
假设P(y=1|x;θ)=hθ(x)
则
P(y=0|x;θ)=1–P(y=1|x;θ)=1−hθ(x)
进一步表示为
P(y|x;θ)=(hθ(x))y(1−hθ(x))(1−y)对数似然损失函数
似然估计
L(θ)=p(y|x;θ)=∏i=1mp(y(i)|x(i);θ)=∏i=1m(hθ(x(i)))y(i)(1−hθ(x(i)))(1−y(i))取对数得到代价函数
L(θ)=log(∏i=1m(hθ(x(i)))y(i)(1−hθ(x(i)))(1−y(i)))=∑i=1myilog(hθ(x(i)))+∑i=1m(1−y(i))log(1−hθ(x(i)))令该导数为0,会发现它无法解析求解,所以只能借助迭代算法
∂∂θjL(θ)=⎛⎝⎜y1g(θTx)−(1−y)11−g(θTx)⎞⎠⎟∂∂θjg(θTx)=⎛⎝⎜y1g(θTx)−(1−y)11−g(θTx)⎞⎠⎟g(θTx)(1−g(θTx))∂∂θjθTx=(y(1−g(θTx))−(1−y)g(θTx))xj=(y−hθ(x))xj得到类似的更新公式
θj:=θj−α∑i=0m(hθ(x(i))−y(i))x(i)j优点
1、直接对分类可能性建模,无需事先假设数据分布,这样就避免了假设分布不准确问题
2、对率函数是任意阶可导凸函数,有很好的数学性质
——————————————————————————————————————————
多类分类问题
策略:
一对一:一对其余:
对于多类分类问题,可以将其看做成二类分类问题:保留其中的一类,剩下的作为另一类。
对于每一个类 i 训练一个逻辑回归模型的分类器,并且预测 y=i 时的概率;
对于一个新的输入变量 x <script type="math/tex" id="MathJax-Element-247">x</script>, 分别对每一个类进行预测,取概率最大的那个类作为分类结果。多对多:
——————————————————————————————————————————
其他优化算法
牛顿法[2]
拟牛顿法[3]
DFP算法[4]
BFGS算法[5]
L-BFGS 算法(Limited-memory BFGS)[6]
Softmax回归[7]
过拟合问题[8]
类别不平衡问题[9]
——————————————————————————————————————————