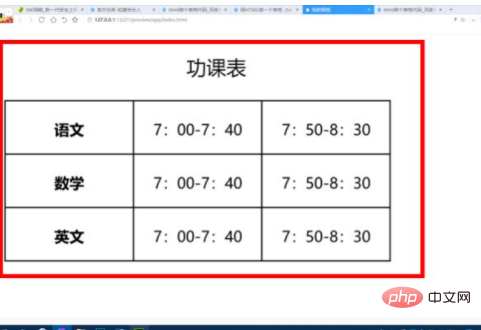
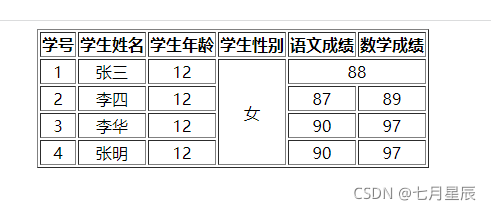
[AAAI’21]ACSNet:Action-Context Separation Network for Weakly Supervised Temporal Action Localization

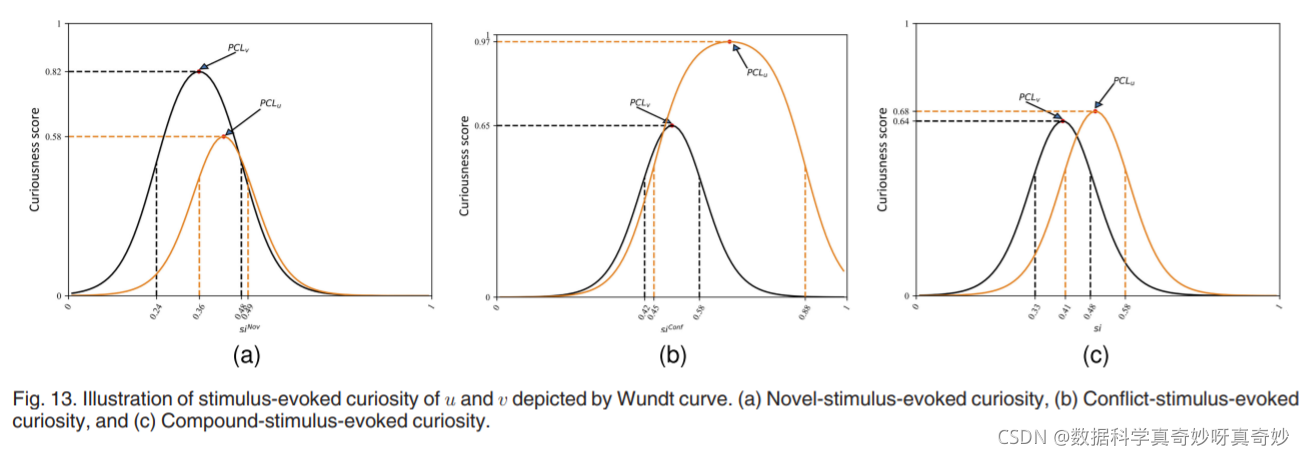
从图中可以看出,左侧绿色框表示是动作类、红色框表示是动作上下文、蓝色框表示为背景类。通过右图的特征空间可见,蓝色的背景类特征与GT相差较远,但是红色的上下文类与GT高度相似,特别是在边界区域,这就导致上下文的误检。
问题的引入:通过视频级别分类定位的前景不仅涉及实际操作实例,还涉及其周围的上下文。以前的方法利用前景注意来实现前景背景分离,而忽略了上下文和动作实例的剥离
Answer:由于上下文为动作分类提供了有力的证据,所以很容易和动作实例混淆,如果将上下文信息和动作实例进行有效的剥离,那么动作时间定位在细粒度上将更加准确。
Contribution:ACSNet不仅可以将前景与背景区分开来,还可以将前景中的动作和背景分离开来,以实现更精确的动作定位使用两个潜在组件的不同组合,分别描述前景、动作和上下文;带有上下文类别的辅助标签
以前的方法可不可以将上下文信息和动作实例剥离?
- 缺乏明确的动作语境约束:前景和背景注意力得分的一对一约束不适用于动作语境分离
- 缺乏明确的监督:动作和上下文都有助于动作分类,因此唯一可用的视频级别分类标签无法为它们提供直接监督。
为什么要引入上下文类别的辅助标签?
通过显式地解耦实际动作及其上下文,这种新的表示有助于有效地学习动作上下文分离。

前景由两个潜在的分量表示,将与实际动作对应为正分量,另一部分为负分量

之后分别将前景注意力、动作实例注意力以及上下文注意力通过两个分量进行拆分,如下图所示:

成功地将动作实例和上下文信息进行显示地解耦。之后引入最小化loss函数来监督动作实例注意力以及上下文注意力。

[CVPR’21] Action Unit Memory Network for Weakly Supervised Temporal Action Localization

TAL的重要观察结果:
(1)共享单元。要检测的操作通常包含一些主要操作单元,可以与其他操作类共享这些操作单元。例如,如图1(a)所示,跳高包含奔跑和向上跳跃,而跳远包含奔跑和向前跳跃,所以跑步是一个共享的动作单元。
(2)稀疏。一般来说,只有一些稀疏的视频片段包含有意义的目标动作。从图1(b)可以看出,一个动作只占视频的一小部分。
(3)平滑。本地化需要平滑的CAS,因为操作是连续的,如图1©所示。
记忆模板库的构建:
根据上述观察结果,作者提出了一个动作单元记忆网络来模拟弱监督时间定位的动作单元,设计了一个存储库来存储动作单元的RGB信息和FLOW信息以及相应的分类器。
多样性机制:由于栋座单元彼此不同,模板库中的每个模板应该是唯一的,所以需要鼓励模板之间的差异性
多样性损失:

同质性机制:某些模板可能与所有视频片段的相似度都很低,为了避免这种情况发生,设计了同质性机制来鼓励模板发生概率的均匀分布
同质性损失:首先通过求和运算将相似度矩阵随时间合并,然后使用softmax函数获得每个模板的发生概率

稀疏性机制:由于在未剪辑的视频中,动作片段只占整个视频的一小部分,并且大部分视频片段是背景。因此需要鼓励只有一组稀疏的视频片段才能与记忆单元中的模板具有高度的相似性
稀疏性损失:鼓励背景片段与所有模板都具有较低的相似度。

交叉注意力:
从记忆模板库中读取分类器和自注意力模板,通过聚合时间上下文信息来凝练特征,然后利用多样性、同质性和稀疏性三种辅助机制,得到段级预测并进行自适应更新

Self-Attention模块:首先通过查询Q计算视频之间的相似度评分,然后利用这些评分通过聚合上下文信息来细化视频片段特征。
 Cross-Attention模块:消息在段间进行传递,来提取全局上下文信息,获得更多的分类和定位特征
Cross-Attention模块:消息在段间进行传递,来提取全局上下文信息,获得更多的分类和定位特征

[CVPR’21]Learning Salient Boundary Feature for Anchor-free Temporal Action Localization
将I3D网络与anchor-free方法进行了结合,并经过了大量调试得出了第一个初始模型,但是这个模型只是简单地把anchor-free的思想借鉴过来,并没有对时序动作检测TAL这个任务作出什么相对应的改善。
在anchor-free方法中,已经有多数方法开始对模型进行一个refine的过程,而这个过程需要一些feature支撑来优化。
在TAL中,以往多数论文都在关注boundary边界信息,例如BSN、BMN、DBG。
因此在anchor-free的框架中,也可以针对初始的coarse boundary去挖掘这些boudnary的特征信息,并找到最显著的特征用来优化boundary以及action class的结果,根据这个思路我们提出了基于显著性优化的模块,对每个proposal的边界利用了max操作来找到最显著的边界特征。
设计到这里的时候,可以max操作来找显著特征的话,也就是让网络自己来学习这个特征,那是否能通过loss来进一步帮助网络去学习显著特征?借助分类的思想以及对比学习的思想提出了边界学习一致性损失函数。
Contributions:
- 提出了第一个有效的purely anchor-free的temporal action localization (TAL)的框架;
- 充分利用了boundary的特性,首先使用Boundary Pooling提取出显著的boundary特征,再使用Boundary Consistency Learning保证提取到的boundary特征的有效性。
两个问题:
- 为什么要使用anchor-free的技术?
- 答:之前TAL任务中使用的方案都是actionness或者anchor的方案。actionness方案例如DBG、BMN,就是在最后枚举了所有起点与终点组合的proposal再去筛选,虽然能保证high recall,但是也会产生很多冗余的结果;anchor方案例如RC3D、PBRNet,实际上是需要根据数据集去配置anchor,并且在实验中也发现这个配置稍微修改对结果有影响。因此anchor-free不仅相对来说产生更少的候选结果,也减少了一些超参的调试。另外我们的模型也是类似于RC3D或者PBRNet的框架,输入直接是一段视频序列,不需要类似DBG那样先抽特征保存后再测试,更符合落地场景。考虑到目前开源代码中缺少类似的框架,因此我们也公开代码来丰富一些TAL这个代码社区。
- 为什么后续需要refine呢?
- 答:在TAL任务里,boundary信息一直是重要的信息,因此我们根据这个任务特性提出了Boundary Pooling和Boundary Consistency Learning,这两个具体的实现我们后面展开。
网络结构图:

- 特征提取部分(Feature Extraction):这里我们直接输入一段T x 96 x 96的视频端,通过I3D网络提取特征,最后转1D的特征金字塔;
- 粗糙预测(Coarse Prediction):这边就是anchor-free的第一阶段,对于每个金字塔层,预测每个时间点上的左右边界距离,以及该proposal的分类;
- 精细预测(Refined Prediction):对于粗糙预测的结果,通过Saliency-based Refinement,根据粗糙预测中的每个proposal,寻找到最显著的边界特征,用这个feature来优化每个proposal的边界位置,并且得到精细预测的分类,最后还会输出该proposal的quality来表示该预测的质量。
激活指导学习:
激活指导学习就是利用像DBG、BMN那样制作出start与end标签,利用该标签作为GT并指导特征的学习。首先我们将FPN特征或者frame-level特征使用tanh和mean操作进行转换,转换为channel=1,值范围为[0-1]的中间特征:

再对这个中间特征使用start与end标签使用BCE进行约束。
边界对比学习
这部分则是借鉴了对比学习的思想。在训练过程中,随机将一段输入根据前景进行切割,例如将前景A切割成A1与A2,再切割一部分背景部分Bg放在A1和A2的中间,形成A1-Bg-A2。对于这样的片段,应该有这样的特征距离分布,A1的end boundary特征应该与A2的start boundary特征接近,而A1的end boudnary特征应该与Bg的start与end boundart特征距离较远,因此这里使用triplet loss来约束这个现象: