Neural Multi-scale Image Compression
2018年5月
图像压缩技术
东京大学
- 针对先前工作仅使用最深层特征表示来编码的问题,提出多尺度有损自编码器实现更好的率失真平衡;针对顺序无损编码造成时间消耗大的问题,提出并行多尺度无损编码器实现快速编解码。
- 其中分布优化analyzer和synthesizer的参数与熵编码的参数,而不是联合优化,来降低计算复杂度,但分开优化阻碍了多分辨率特征的优势利用,因为不同分辨率的熵不同,难以利用这个属性。
- 利用软量化来代替硬量化实现可微。
- 考虑到距离越大,像素相关性越小,对量化后的特征进行分组,并行编码。
- 率失真损失函数优化是下一步的研究方向 。
- 转换PNG图像到CUDA阵列可以减少计算时间,这将作为未来的研究方向。
- 本文无损编码和独立无损编码比较,MS-SSIM占优,但时间花费长。
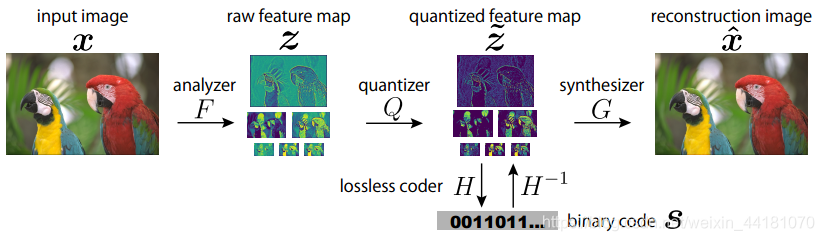
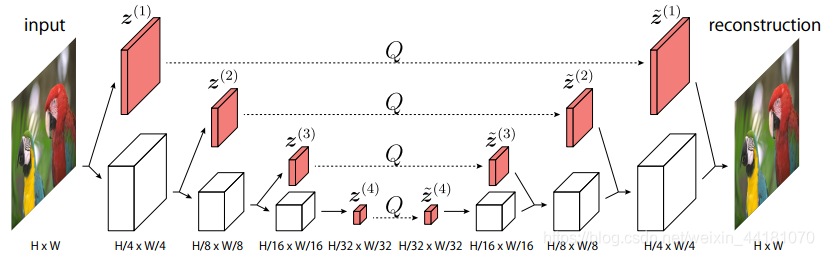
**思考:**更具独立性的分组编码的距离是否够远?再增大距离是否能改善性能?
Real-Time Adaptive Image Compression
2017年5月
图像压缩技术
wave one公司,作者Lubomir之前是Facebook做CV的负责人
我们的架构是一个具有金字塔分析的自动编码器,一个自适应编码模块,以及预期编码长度的正则化。增加多尺度对抗训练来补充模型。性能超过了当前所有的CNN-based模型,并且可以实时运行。方法轻量级且可有效部署。
背景:
JPEG这些算法不可以根据输入变化自己的变换,无法对编解码器进行优化。
整体框架:

特征提取:由一个金字塔分解和尺度间对其程序构成
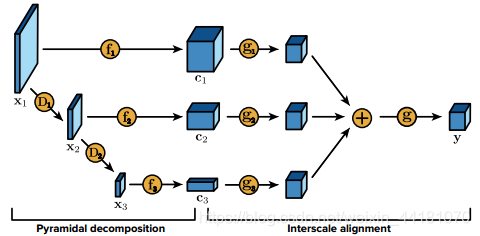
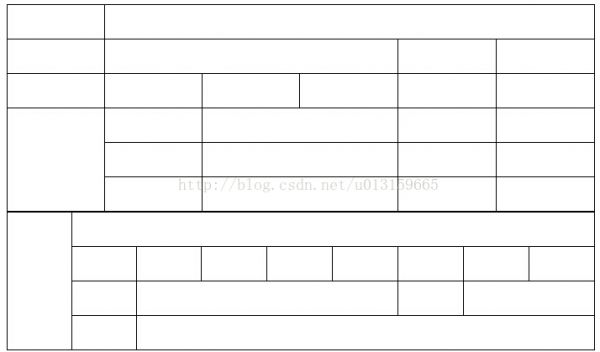
coding:通过位平面分解和自适应算术编码进一步压缩量化张量,量化和编码都是为了把熵降下来。位平面:

这个变换将每个值y^chw映射成B位的二进制展开,C中每个层都映射为B个二进制位平面,最终的输出为: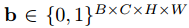
这个变换是无损的。
自适应码长正则化:将预期的编码长度调制到指定的目标比特率。
自适应算术编码:简单来说就是拿一个classifier,根据这些bit的邻居来预测这个bit本身应该是什么值。decoding是同一个classifier,不过整个过程是反过来的。我们训练一个分类器根据每个比特的上下文特征来预测其值,然后利用这些概率通过算术编码来压缩位平面分解的输出。
重建loss:像素上进行惩罚。
判别器loss:从分布上进行惩罚。
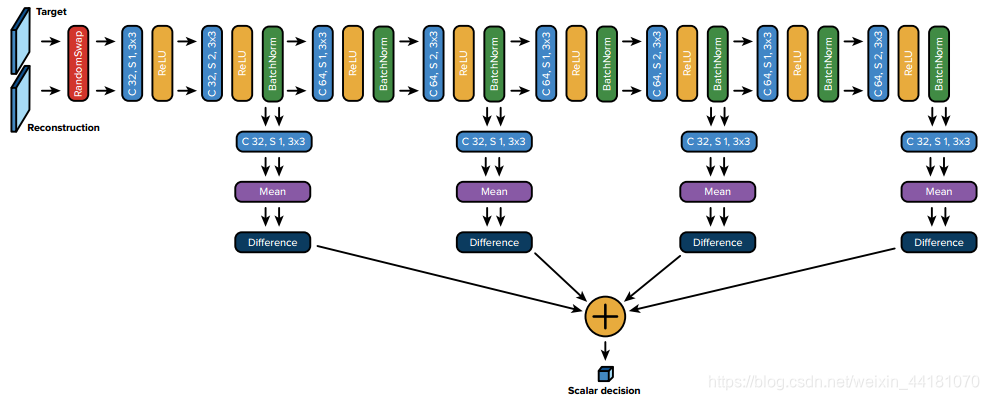
把GAN用于压缩,在许多既有重构又有判别损失的GAN方法中,目标和重构都是独立处理的:每一种方法都被单独分配一个标签,表明它是真还是假。在我们的公式中,我们把目标和它的重建作为一个单独的例子:我们通过问这两幅图像中哪一幅是真实的来比较这两幅图像。
判别器:随机交换目标和重建图像,判别器的目标是推断出这两个输入中的哪个是真实的目标,哪个是它的重构。累积不同深度的多尺度的标量输出。
DeepSIC: Deep Semantic Image Compression
2018年1月
浙江大学
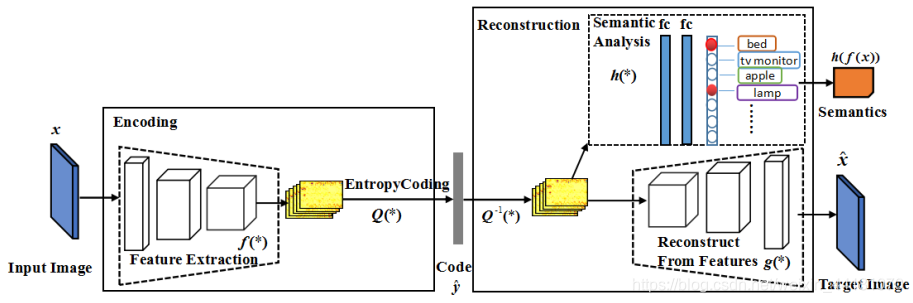
在图像压缩编码中加入语义信息可以显著减少用户端应用的基础语义分析的重复计算,比如目标识别,同时,允许压缩的码流携带语义信息。本文提出深度语义图像压缩框架(DeepSIC,Deep semantic image compression),提出两个新的体系结构致力于重建压缩图像的同时,生成对应的语义表示。 第一种体系结构(pre-semantic DeepSIC)在编码过程中执行语义分析,从压缩代码中保留一部分位来存储语义表示。第二种体系结构(post-semantic DeepSIC)在解码步骤中使用嵌入在压缩代码中的特征图进行语义分析。在这两种体系结构中,特征映射由压缩模块和语义分析模块共享。
本文贡献:
提出DeepSIC,这是首次将语义信息引入图像压缩的工作。提出pre-semantic DeepSIC和post-semantic DeepSIC两个框架。
语义图像压缩框架:
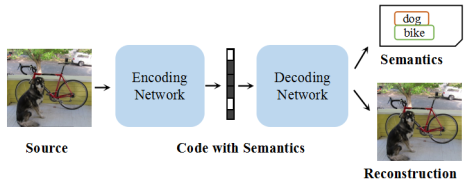
pre-semantic DeepSIC:
 post-semantic DeepSIC:
post-semantic DeepSIC:
备注:实验结果超过传统JPEG、JPEG2000,但未超过深度学习的压缩算法,因为这篇文章的特色在于语义分析。
Variational Autoencoder for Low Bit-rate Image Compression
2018年
Tucodec公司
Lei Zhou
提出端对端的低码率压缩框架。基于变分自编码器,包括非线性编码、均匀量化器、非线性解码和一个后处理模型。利用超先验自编码器对压缩表示的先验概率进行拉普拉斯分布建模,并与变分自编码器联合训练。此外,提出后处理模型来移除压缩的人工痕迹和模糊。最后,利用率控制算法来自适应分配码率。
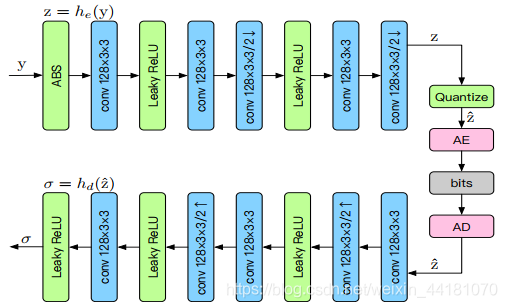
与[3,4]不同,我们设计了一种金字塔和更有效的卷积结构的自编码器。利用参数化的零均值拉普拉斯分布精确地模拟了压缩表示的先验概率,其参数由超先验自编码器学习。
压缩表示y是通过金字塔编码器融合多尺度的特征构成的。
量化表示y帽的分布是通过零均值拉普拉斯分布来模拟的。
变分自编码器框架:GDN/IGDN实现了一种局部分裂标准化转换。
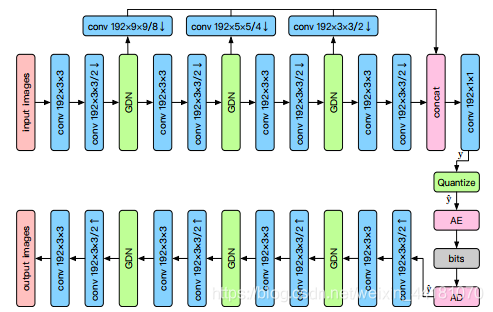
为了减少参数,用2个33的卷积代替1个55的卷积,这个替代能够实现共享参数,减少计算量,提升峰值信噪比。
用round的方法实现量化反向传播。
超参数自编码器:y是压缩表示,超参数编码器总结了z的标准差分布,z被量化后作为side information被压缩和传输。解码器估计参数σ,σ被用于构建拉普拉斯分布进行率估计。
拉普拉斯比高斯分布更接近自然图像的实际分布。
压缩率是由两部分组成:压缩表示和压缩side information的rate。
利用残差块进行后处理,包括去人工痕迹和图像增强。(这方法在超分辨率、去噪方面用的比较多)
**不足:**计算复杂度高。
**未来工作:**在未来的工作中,我们希望通过优化网络结构和开发卷积神经网络优化硬件芯片上的应用来探索一种更有效的压缩式自动编码器。
Autoencoder Based Image Compression: Can the Learning be Quantization Independent?
2018年4月
法国国家计算机科学和控制研究所
Thierry Dumas
有代码
本文探索自编码器图像压缩变换学习的问题。通常,图像压缩的速率失真性能是通过改变量化步长来调整的。在自动编码器的情况下,这在原则上需要在给定的量化步长下学习每个率失真点的一个转换形式。在这里,我们证明了通过一个独特的学习变换可以获得相似的性能。然后通过在测试时改变量化步长来达到不同的率失真点。这种方法节省了大量的训练时间。
在测试时通过自编码器和各种量化步长大小使用一个学习到的独特变换,以及当学习在一个给定的量化步长大小每个率失真点变换,是可实现压缩的。此外,学习后的变换比其他基于变换的图像压缩算法有更好的性能。
Toward Joint Image Generation and Compression using Generative Adversarial Networks
2019年1月
加州大学圣地亚哥分校
Byeongkeun Kang
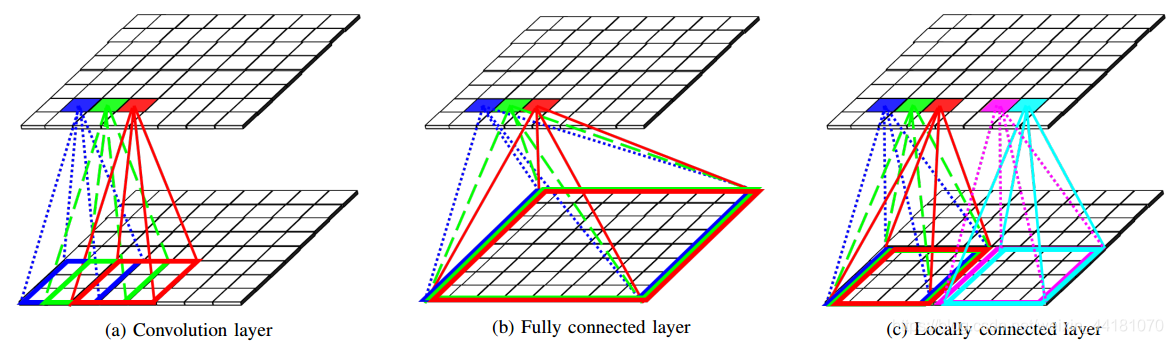
由于实际中传输的是压缩图像而不是原图,本文提出了一个生成对抗网络框架,它生成JPEG压缩图像,而不是生成原始RGB图像并在后处理中单独压缩。该生成器由局部连接层、色度下采样层、量化层、残差块和卷积层组成。提出的局部连接层来实现基于块的操作。我们还讨论了该体系结构的训练策略,包括损失函数及其生成器和判别器之间的转换。
如果生成原图像,再进行压缩,这样训练的网络参数不是最优。
生成器有3个通道,1个用来处理亮度,2个用来处理色度。
本文贡献:
1:提出了一个生成对抗网络框架,它生成JPEG压缩图像。
2:提出的局部连接层来实现基于块的操作。
展望:
通过研究学习生成压缩数据的优化算法,我们认为该方法可以得到进一步的改进。我们考虑了该方法作为baseline的情况。
Generative Adversarial Networks for Extreme Learned Image Compression
2018年
苏黎世联邦理工学院
Eirikur Agustsson
摘要:
提出了一种基于生成对抗网络(GANs)的极限学习图像压缩框架,该框架能以比以往方法低得多的比特率获得视觉上满意的图像。这是可能的通过我们的学习压缩的GAN公式与生成器/解码器的结合,该生成器/解码器运行在全分辨率图像和与多尺度判别器组合训练。此外,我们的方法可以从原始图像中提取的语义标签地图,充分合成解码图像中不重要的区域,如街道和树木,因此只需要保存的区域和语义标签地图的存储。用户研究证实了,对于低比特率,我们的方法明显优于最先进的方法,与次优的BPG方法相比,节省高达67%。
本文主要内容:
本文提出并研究了一种基于生成式对抗网络(GAN)的极限图像压缩框架,目标比特率低于0.1 bpp。我们提出了一种基于GAN原理的图像深度压缩算法,允许不同程度的内容生成。与之前深度图像压缩在图像块中运用对抗损失进行人工痕迹抑制[6、14]、纹理细节生成[15]和缩略图的表示学习[16]等工作不同,我们的生成器/解码器作用于全分辨率图像,并与多尺度判别器一起训练[13]。
我们研究了两种操作模式(对应于无条件GANs和条件GANs[11,17]),即
①全局生成压缩(GC),在保存整体图像内容的同时生成不同尺度的结构,如树的叶子或建筑物表面的窗户。
②选择性生成压缩(SC),图像的一部分区域完全由语义标签地图生成,同时保留用户定义的具有高度细节的区域。
所提出的压缩网络的结构:
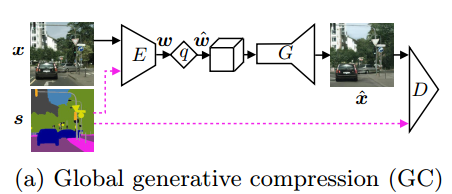
s是可选择的语义标签地图。未用s,是无条件的GANs,用了s,是有条件的GANs。
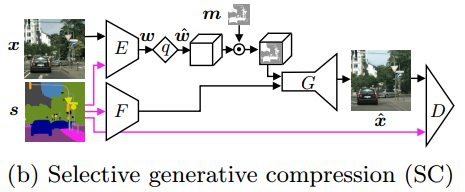
F是特征提取器,子采样热图m与z^逐点相乘用于空间率分配。
结论:
我们提出了一个学习压缩的GAN公式,在低比特率的情况下,无论在mIoU(mean intersection over union)方面还是在人类的视觉上,它都显著优于之前的工作。此外,我们的网络可以无缝地将保存的图像内容与生成的图像内容结合起来,在合成具有规则结构的内容时生成逼真的图像。