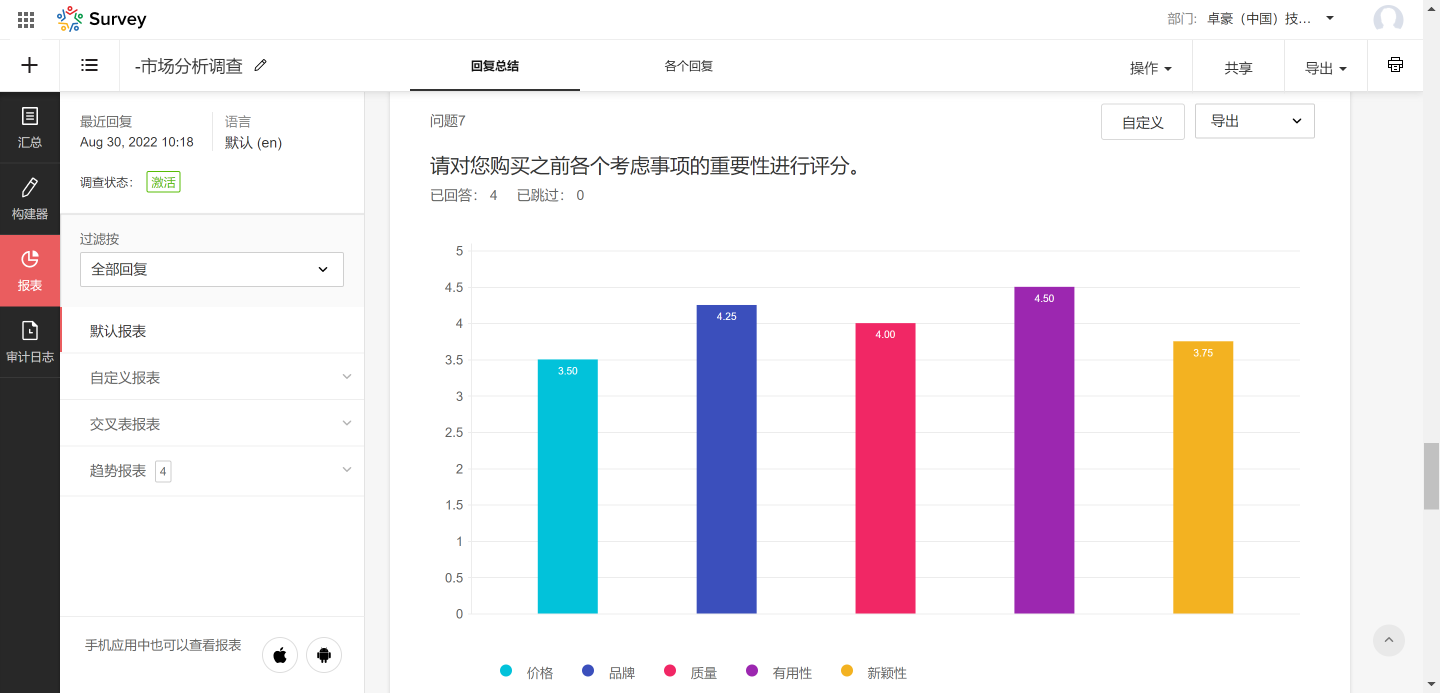
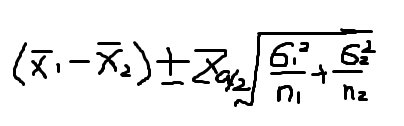[已编辑:]我有一个文件data2007a.csv,我将第一个连续的几行复制并粘贴(使用MacBook中的TextEdit)到新文件datatest1.csv进行测试:
Nomenclature,ReporterISO3,ProductCode,ReporterName,PartnerISO3,PartnerName,Year,TradeFlowName,TradeFlowCode,TradeValue in 1000 USD
S3,ABW,0,Aruba,ANT,Netherlands Antilles,2007,Export,6,448.91
S3,ABW,0,Aruba,ATG,Antigua and Barbuda,2007,Export,6,0.312
S3,ABW,0,Aruba,CHN,China,2007,Export,6,24.715
S3,ABW,0,Aruba,COL,Colombia,2007,Export,6,95.885
S3,ABW,0,Aruba,DOM,Dominican Republic,2007,Export,6,11.432
我想使用textscan将其读入MATLAB,仅使用第2,3,5列(从第二行开始)并编写以下代码
clc,clear all
fid = fopen('datatest1.csv');
data = textscan(fid,'%*s %s %d %*s %s %*[^\n]',...
'Delimiter',',',...
'HeaderLines',1);
fclose(fid);
但我最后只得到第2,3和5列的第二行:
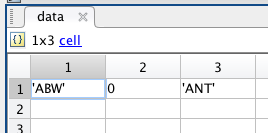
然后我将第一行保留在data2007a.csv中,并选择其他几个保存为datatest2.csv:
Nomenclature,ReporterISO3,ProductCode,ReporterName,PartnerISO3,PartnerName,Year,TradeFlowName,TradeFlowCode,TradeValue in 1000 USD
S3,ABW,1,Aruba,USA,United States,2007,Export,6,1.392
S3,ABW,1,Aruba,VEN,Venezuela,2007,Export,6,5633.157
S3,ABW,2,Aruba,ANT,Netherlands Antilles,2007,Export,6,310.734
S3,ABW,2,Aruba,USA,United States,2007,Export,6,342.42
S3,ABW,2,Aruba,VEN,Venezuela,2007,Export,6,63.722
S3,AGO,0,Angola,DEU,Germany,2007,Export,6,105.334
S3,AGO,0,Angola,ESP,Spain,2007,Export,6,8533.125
我写道:
clc,clear all
fid = fopen('datatest2.csv');
data = textscan(fid,'%*s %s %d %*s %s %*[^\n]',...
'Delimiter',',',...
'HeaderLines',1);
fclose(fid);
data{1}
它完全符合我的要求:
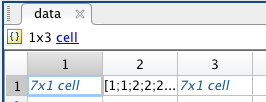

当我对原始数据文件data2007a.csv使用相同的代码时,它与第一种情况一样。
出了什么问题,我该如何解决?
[添加:]如果复制我的实验1,可以发现两种情况都有效且问题不存在!我真的不知道发生了什么。
1对于“复制”,我的意思是复制并粘贴上面给出的数据并将其另存为两个新文件,例如datatest4a.csv和datatest4b.csv。我使用visdiff('datatest1.csv', 'datatest4a.csv')来比较两个文件并返回:
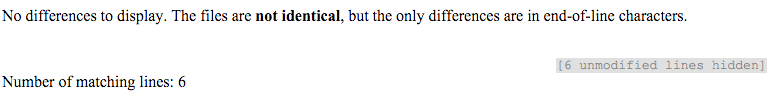
![[Matlab]使用textscan读取.csv文件时候只读取到了第一行](https://img-blog.csdnimg.cn/57e756d6c233489c98cf4878338d9535.png)