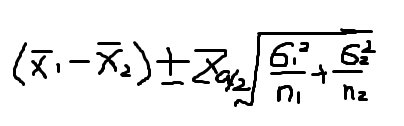总体为9200人,预设的整体置信度为95%,最大容许误差为正负5%,求样本容量
网上搜到的第一个有价值的内容如下:
题目
某公司对60000人中的吸烟比例做调查,置信度为95%的情况下,若要使误差保持在4%以内,需要的最小样本容量是
这里并没有告诉总体的方差(标准差)和样本方差(标准差),那到底应该怎样做呢?
还有第二问:
已知比例在10%-20%,要使误差保持在5%以内,求需要的最小样本容量?
优质解答
第一问:
当方差未知的情况下,通常取最大值.已知方差S的平方(这里打不出平方,就用文字表示了)=p*(1-p),当p=0.5的时候,S的平方值最大,等于0.25,即取方差为0.25.所以,样本量n=(Z的平方*S的平方)/E的平方,带入数值(置信度为95%时,Z=1.96,)得:n=(1.96*1.96*0.25)/(0.04*0.04)=600.25,即最小样本量为601.
第二问:
据题意,当比例为10%时,方差最小,方差S的平方=0.1*(1-0.1)=0.09,此时,所需样本量最小,
带入数值得:n=(1.96*1.96*0.09)/0.05*0.05)=138.3,即最小样本量为139.
同理,当取20%时,最小样本量为246,明显139
上文中使用的抽样数量计算公式如下。
,但是在实际使用中西格玛的平方往往是未知的,因此上文中用p(1-p)代替
n: 为样本量;:方差,抽样个体值和整体均值之间的偏离程度,抽样数值分布越分散方差越大,需要的采样量越多;
E: 为抽样误差(可以根据均值的百分比设定),由于是倒数平方关系,抽样误差减小为1/2,抽样量需要增加为4倍; : 为可靠性系数,即置信度,置信度为95%时,
=1.96,置信度为90%时,
=1.645,置信度越高需要的样本量越多;95%置信度比90%置信度需要的采样量多40%;
随后又搜索到一篇有价值的参考资料:
http://blog.sina.com.cn/s/blog_a032adb90101fp1p.html
但是,如果按照上述文章中的方法进行计算,都没有用到总体数量9200这个条件,感觉不对,所以继续搜索
最终发现,上述各篇文章都是应用的总体无限的的抽样公式,如果总体有限,则应按照如下方法计算:
作者:知乎用户
链接:https://www.zhihu.com/question/23017185/answer/23871782
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
具体到某个研究要多少样本,就要根据误差和置信度去计算了。具体计算公式是:n=1.96^2*P(1-P)/E^2. 其中E是误差,P是估计的总体比例,1.96是置信度为95%的标准值
---------补充----------
感谢
@Detian Deng
补充!最近在做一些人口属性方面的统计工作,主要涉及到的是性别比例,对统计学上的相关知识也是现学现用,所以也想探讨一些问题:
1. 在大样本抽样中,样本比例p的抽样分布可以按照正态分布逼近。在我的之前的回答中,n=1.96^2*P(1-P)/E^2 其实只是有放回抽样情况下对样本量的计算,因为此时样本比例p服从期望E(p)=P,方差V(p)=P(1-P)/n 的正态分布,根据区间估计,有E=1.96*V(p)^2,以此可以求得n。而在无放回抽样中,样本比例p的方差是V(p)=(N-n/N-1)P(1-P)/n,同样的求解方式,样本量n=1.96^2*P(1-P)/(E^2+1.96^2*P(1-P)/N),但此时,样本量n的大小就与总体量N有关了。是这样吧?
2. 无论是区间估计,还是求样本量,中间都用到了总体比例P。但是明明求这个总体比例P是我们抽样的目的,所以在我们求n和置信区间时,涉及到P我们往往都用一个以往统计的总体比例值作为参考。因此,从这些公式中可以发现,我们对总体比例的估计,是根据1)以往统计的总体比例;2)抽样样本的比例。是这样吧?
以上内容来自于知乎的如下问题:
https://www.zhihu.com/question/23017185
按照上述方式计算的结果是368.76,;按照无限总体计算的结果是384.16.
另外,还发现了一个计算抽样数量的网址,可以在线计算:
https://www.surveysystem.com/sscalc.htm
其中的confidence interval填写容许误差的一半(不要百分号),例如,本题中容许误差为正负5%,所以,confidence interval填5。这个网站计算出的结果是369,与我们的计算结果一致