如何计算样本量
商业分析的面试,很少会让面试者直接默写公式并进行计算。为啥?一,面试官八成自己也不记得公式。二,真实工作都是用网上的计算器,一键呵成,无需手算。

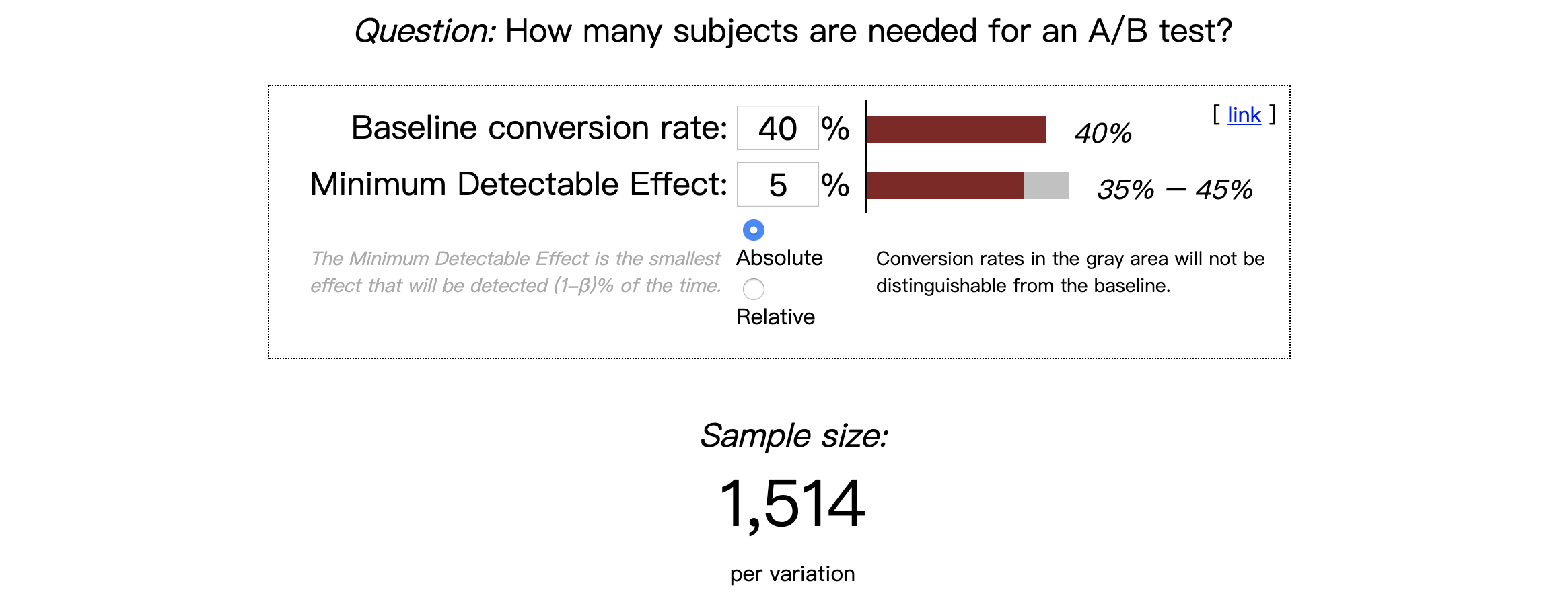
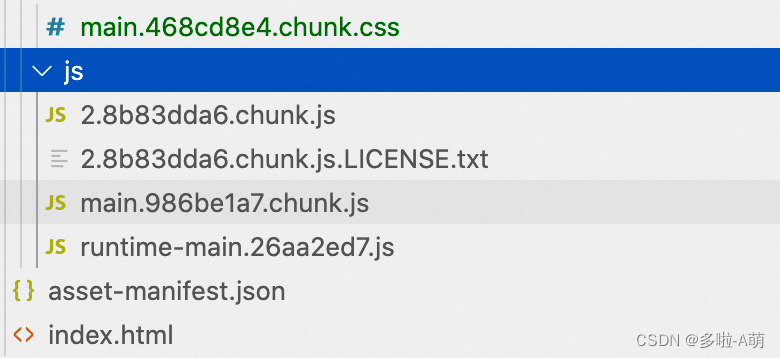
网上随手找的的sample size计算器
那么,我们现在来看看这个计算器的正确使用方法。
这个计算器需要4个输入。有了这四个输入,就一定能够算出所需样本量。这四个输入分别是:
- Statistical power
- Significance level
- Baseline rate
- Minimum detectable effect
我们看看每个输入是什么意思。
Statistical Power和Significance Level
要搞清这两个概念,我们应该先简短回顾一下A/B实验的基本知识。
首先,A/B测试包含两个假设:
- 原假设(Null hypothesis, 也叫H0):我们希望通过实验结果推翻的假设。在我们的例子里面,原假设可以表述为“红色按钮和绿色按钮的点击率一样”。
- 备择假设(Alternative hypothesis, 也叫H1):我们希望通过实验结果验证的假设。在我们的例子里面,可以表述为“红色按钮和绿色按钮的点击率不同”。
A/B测试的本质,就是通过实验数据做出判断:H0到底正不正确?
如果我们找到每一个用户做产品调查,我们可以统计出一个真实的、无偏差的关于绿色按钮是否有效的结论。我们把这个结论叫做ground truth。
把通过实验数据得出的结论和ground truth进行比较,一共会出现4种情况:
情况1:点击率无区别(H0正确),你却说有区别。

由于判断错了,我们把这类错误叫做第一类错误(Type I error),我们把第一类错误出现的概率用α表示。这个α,就是Significance Level。
在商业背景下,第一类错误意味着新的产品对业务其实没有提升,我们却错误的认为有提升。这样的决定,不仅浪费了公司的资源,而且部分人得到了不应得的奖励。
在非商业背景下,第一类错误往往更加可怕。比如好人被判刑进监狱,健康人被误诊送去化疗。
所以,在做A/B测试的时候,我们希望第一类错误越低越好。实际操作中,我们把α人为定一个上限,一般是5%。也就是说,在做实验的时候,我们都会保证第一类错误出现的概率永远不超过5%。
情况2:点击率无区别(H0正确),你说没区别。

判断正确!但好像没啥可说的...
情况3:点击率有区别(H1正确),你说有区别。

判断正确。我们把做出这类正确判断的概率叫做Statistical Power。
要记得,我们的做实验的根本目的是为了检测出红色按钮和绿色按钮的点击率差别。如果power低,证明即使新产品真的有效果,实验也不能检测出来。换句话说,我们的实验无卵用。
极端情况,假设power=50%。这意味着如果绿按钮真的提升了点击率,实验只能有50%概率检测出来。领导们知道了是要拍桌子的...
情况4:点击率有区别(H1正确),你说没区别。
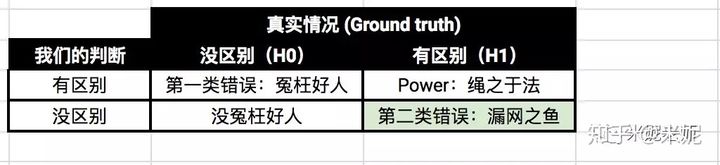
我们的判断又错了。这类错误叫做第二类错误(Type II error),用β表示。根据条件概率的定义,可以计算出β = 1 - power。
总结一下,对于我们的实验:
- 第一类错误α不超过5%。也就是说,Significance Level = 5%。
- 第二类错误β不超过20%。也就是说,Statistical Power = 1 -β = 80%。
对两类错误上限的选取(α是5%,β是20%),我们可以了解到A/B实验的重要理念:宁肯砍掉4个好的产品,也不应该让1个不好的产品上线。
Baseline Rate
这个看的是在实验开始之前,对照组本身的表现情况。在我们的实验里,baseline就是红色按钮的历史点击率。从直观上我们可以这么理解baseline:
- 当baseline很大(接近1)或者很小(接近0)的时候,实验更容易检测出差别(power变大),如果保持power不变,那么所需要的样本数量变小。举个例子,假设红色按钮的点击率是0%。那么,哪怕绿色按钮只有一个用户点击,相对于对照组来说也是挺大的提升。所以即便是微小的变化,实验也会更容易地检测出来。
- 同理,当baseline居中(在0.5附近徘徊)的时候,实验的power会变小。
在工作中,这个参数完全是历史数据决定的。在我们的实验中,我们假定,实验开始之前的历史点击率是15%。所以Baseline Rate=15%。
Minimum Detectable Effect
顾名思义,这个参数衡量了我们对实验的判断精确度的最低要求。
- 参数越大(比如10%),说明我们期望实验能够检测出10%的差别即可。检测这么大的差别当然比较容易(power变大),所以保持power不变的情况下,所需要的样本量会变小。
- 参数越小(比如1%),说明我们希望实验可以有能力检测出1%的细微差别。检测细微的差别当然更加困难(power变小),所以如果要保持power不变的话,需要的样本量会增加。
在工作中,这个参数的选定往往需要和业务方一起拍板。在我们的实验中,我们选定Minimum Detectable Effect=5%。这意味着,如果绿色按钮真的提高了点击率5个百分点以上,我们希望实验能够有足够把握检测出这个差别。如果低于5个百分点,我们会觉得这个差别对产品的改进意义不大(可能是因为点击率不是核心指标),能不能检测出来也就无所谓了。
给计算器填数
好了,我们现在把4个数字分别填入计算器。

结果表明,跑我们这个实验,实验组对照组各需要大约36k用户,也就是总共72k。
一般的互联网产品比如Facebook,这个样本量就是个零头(FB日活15亿,72K个用户可以忽略不计 )。所以,这就是为什么互联网公司可以几百个实验同时跑,同时保证了每个实验都有足够的样本量。
总结
通过使用样本量计算器,我们知道了决定样本量的4个参数、以及这4个参数对样本量的影响方式。只要能够理解并在面试中讲清这个道理,我们是不需要死记公式的。