目录
ShuffleNet V1
论文
介绍
Channel Shuffle
ShuffleNet v1 单元
ShuffleNet v2
论文
介绍
高效模型的设计准则
ShuffleNet V2结构
ShuffleNet v2和DenseNet
总结
ShuffleNet V1
论文
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile
https://arxiv.org/abs/1707.01083 2017年
介绍
建立更深更大卷积神经网络是当前主要趋势,但是智能手机等终端设备运算能力有限
Xceotion和ResNeXt等网络由于大量使用1*1卷积而变慢
提出使用pointwise group convolutions 来降低1*1卷积的计算复杂度
提出channel shuffle操作来应对组卷积的副作用
性能优于MobileNet
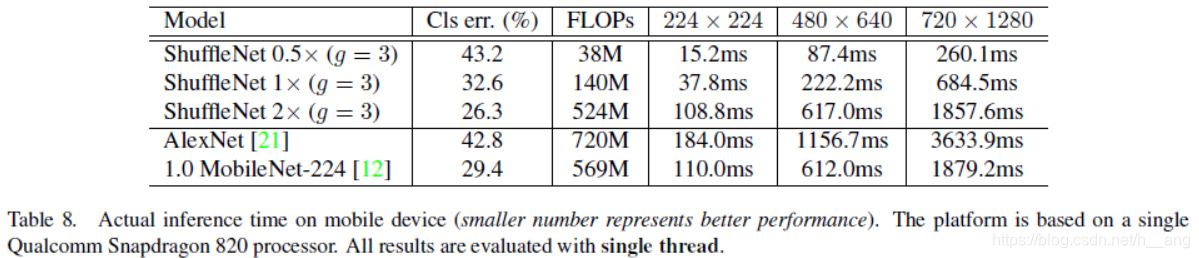
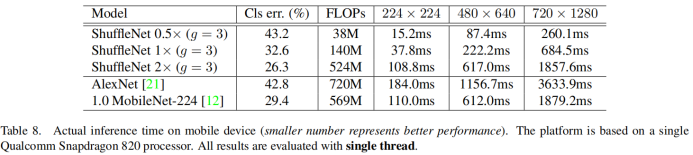
在arm架构中执行代码,最终在准确度上和AlexNet差不多的情况下,速度快13倍。
ResNeXt讲解:ResNeXt详解 - 知乎
分组卷积作为传统卷积和深度可分离卷积的一种折中方案在AlexNet中就已经有了,当时主要是让模型在双GPU上的训练解决训练效率问题,ResNeXt也借鉴了这种group操作改进了原本的ResNet。
这时大量的对于整个Feature Map的Pointwise卷积成为了ResNeXt的性能瓶颈。一种更高效的策略是在组内进行Pointwise卷积,但是这种组内Pointwise卷积的形式不利于通道之间的信息流通,为了解决这个问题,ShuffleNet v1中提出了通道洗牌(channel shuffle)操作。
在ShuffleNet v2的文章中作者指出现在普遍采用的FLOPs评估模型性能是非常不合理的,因为一批样本的训练时间除了看FLOPs,还有很多过程需要消耗时间,例如文件IO,内存读取,GPU执行效率等等。作者从内存消耗成本,GPU并行性两个方向分析了模型可能带来的非FLOPs的行动损耗,进而设计了更加高效的ShuffleNet v2。ShuffleNet v2的架构和DenseNet[4]有异曲同工之妙,而且其速度和精度都要优于DenseNet。
Channel Shuffle
回顾深度可分离卷积:
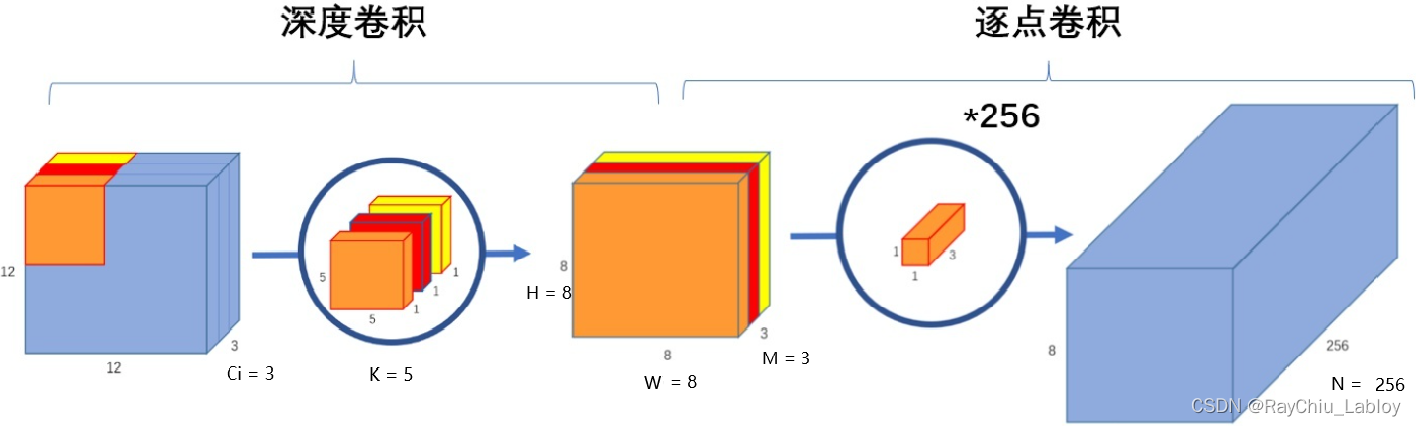
FLOPs = Ci * K * K * H * W + M * N * H * W
= M * K * K * H * W + M * N * H * W
由上式转换深度卷积和Pointwise卷积不同之处就是前者K*K=15(大多数场景反而是3*3),后者是N,一般N的值远大于15,因此深度可分离卷积压力都在1*1卷积上,那么如果逐点卷积采用分组策略分为g组,那么
FLOPs = M * K * K * H * W + (M * N * H * W)/ g 这样就解决了性能瓶颈问题了,但是正如上文说到的,分组后组内Pointwise卷积会导致通道之间的信息流通被阻断。
因此ShuffleNet的通道洗牌思想就横空出世了
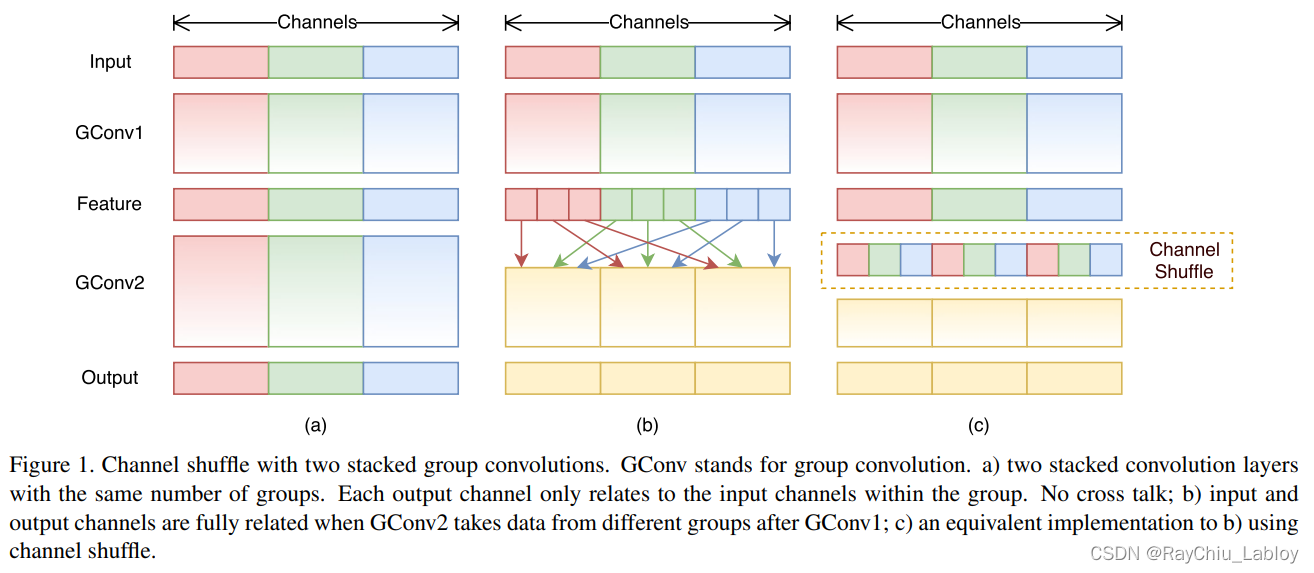
通道洗牌+pointwise group convolutions的流程:
在上图中的Feature这一步,先把Feature Map(形状为h*w*c)的c个通道分成g组,然后重组顺序后,再按照组内Pointwise卷积进行操作。
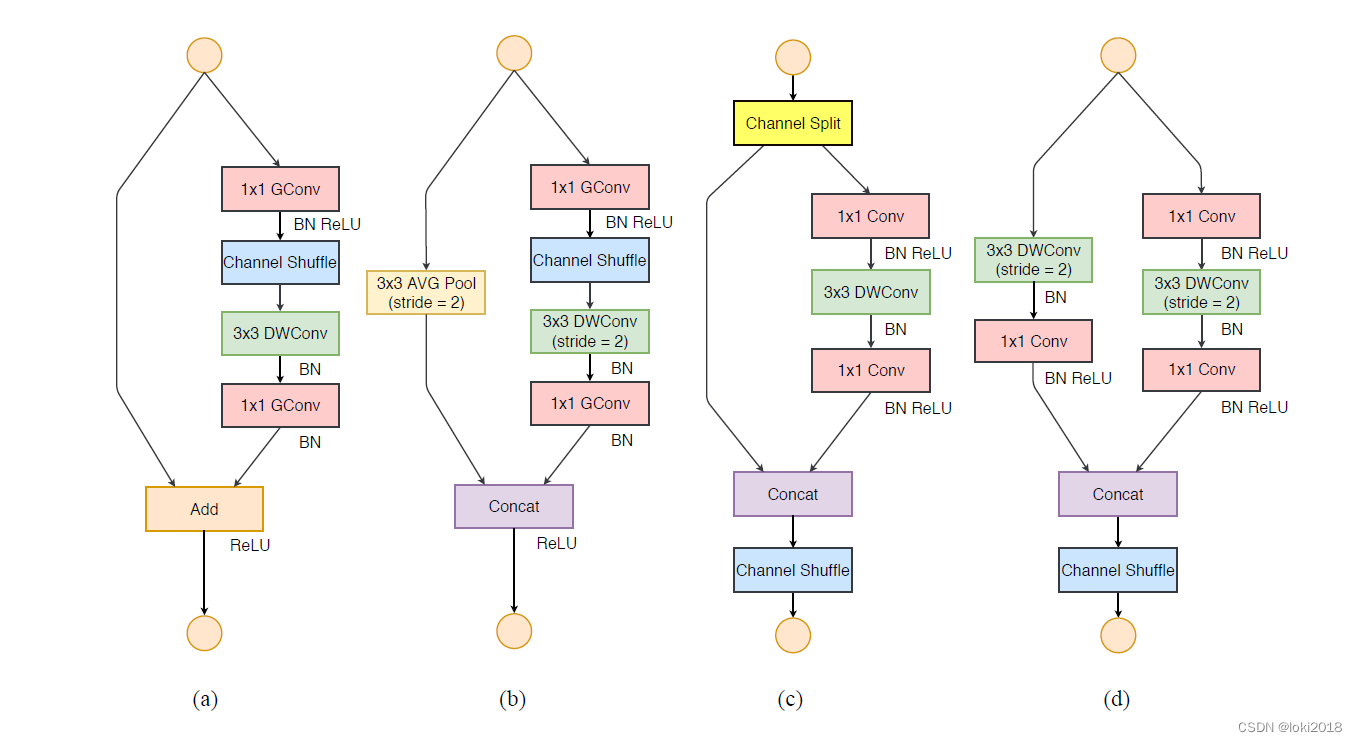
ShuffleNet v1 单元
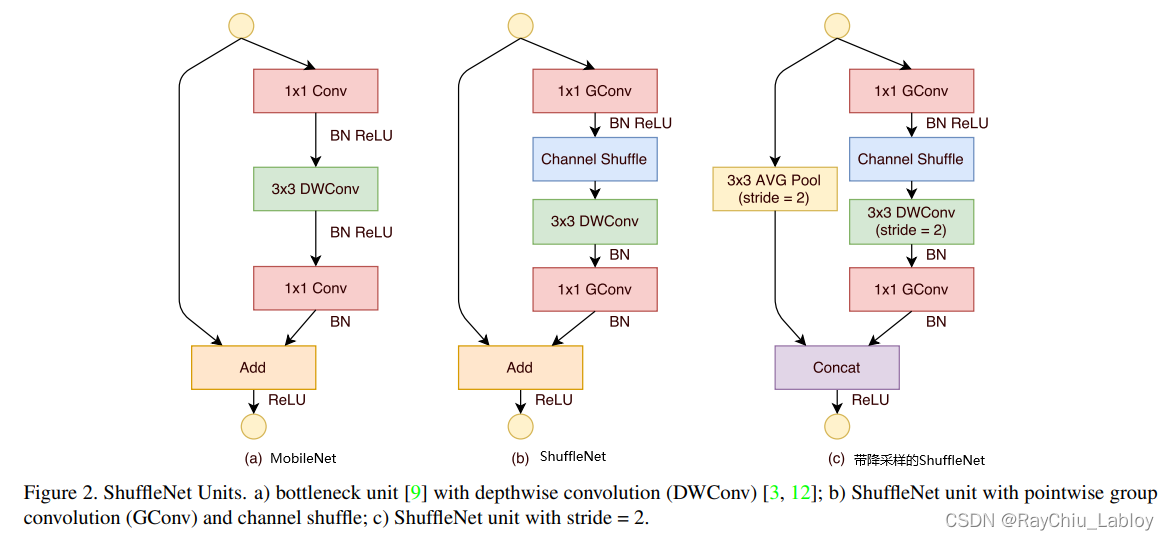
b和c介绍了ShuffleNet v1全部的实现细节:
ShuffleNet v1的上下两个1*1的卷积会采用分组1*1卷积,分组 g 一般不会很大,论文中的几个值分别是1,2,3,4,8。当g=1时退化为Xception,g需要被通道整除。
在第一个 1*1 卷积之后添加一个Channel Shuffle操作。
如图c中需要降采样的情况,左侧shortcut部分使用的是步长为2的 3*3 平均池化,右侧使用的是步长为2的 3*3 的Depthwise卷积。
去掉了 3*3 卷积之后的ReLU激活,目的是为了减少ReLU激活造成的信息损耗,原因和MobileNet v2一样。
如果进行了降采样,为了保证参数数量不骤减,往往需要加倍通道数量。所以在图c中使用的是拼接(Concat)操作用于加倍通道数,而图b中则是一个单位加。
ShuffleNet v2
论文
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
https://arxiv.org/abs/1807.11164 2018年
介绍
之前我们统一使用FLOPs作为评估一个模型的性能指标,但是在ShuffleNet v2的论文中作者指出这个指标是间接的,因为一个模型实际的运行时间除了要把计算操作算进去之外,还有例如内存读写,GPU并行性,文件IO等也应该考虑进去。最直接的方案还应该回归到最原始的策略,即直接在同一个硬件上观察每个模型的运行时间。如图4所示,在整个模型的计算周期中,FLOPs耗时仅占50%左右,如果我们能优化另外50%,我们就能够在不损失计算量的前提下进一步提高模型的效率。
在ShuffleNet v2中,作者从内存访问代价(Memory Access Cost,MAC)和GPU并行性的方向分析了网络应该怎么设计才能进一步减少运行时间,直接的提高模型的效率。
高效模型的设计准则
当输入通道数和输出通道数相同时,MAC最小
MAC与分组数量 g 成正比
网络的分支数量降低并行能力
Element-wise操作是非常耗时的
总结一下,在设计高性能网络时,我们要尽可能做到:
- 使用输入通道和输出通道相同的卷积操作;
- 谨慎使用分组卷积;
- 减少网络分支数;
- 减少element-wise操作。
例如在ShuffleNet v1中使用的分组卷积是违背2的,而每个ShuffleNet v1单元使用了bottleneck结构是违背1的。MobileNet v2中的大量分支是违背3的,在Depthwise处使用ReLU6激活是违背4的。
ShuffleNet V2结构
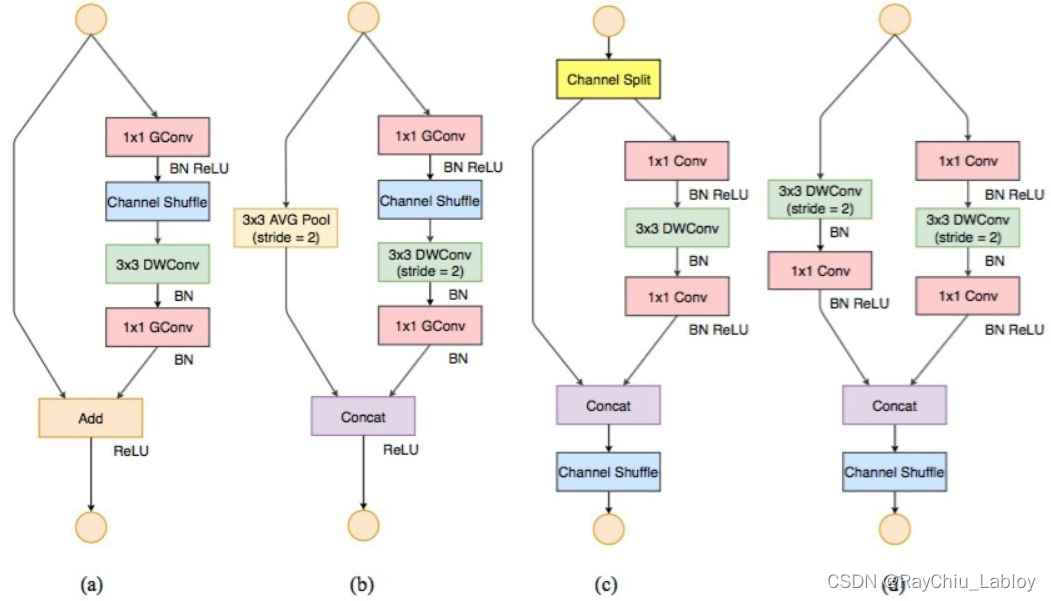
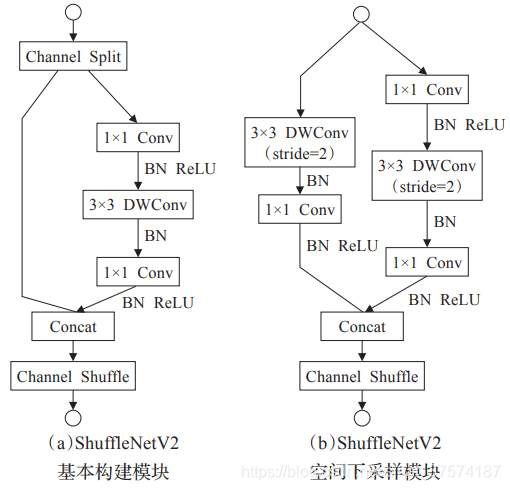
仔细观察(c),(d)对网络的改进我们发现了以下几点:
在(c)中ShuffleNet v2使用了一个通道分割(Channel Split)操作。这个操作非常简单,即将 c 个输入Feature分成 c - ![]() 和
和 ![]() 两组,一般情况下
两组,一般情况下 ![]() 。这种设计是为了尽量控制分支数,为了满足G3。
。这种设计是为了尽量控制分支数,为了满足G3。
在分割之后的两个分支,左侧是一个直接映射,右侧是一个输入通道数和输出通道数均相同的深度可分离卷积,为了满足G1。
在右侧的卷积中,1*1 卷积并没有使用分组卷积,为了满足G2。
最后在合并的时候均是使用拼接操作,为了满足G4。
在堆叠ShuffleNet v2的时候,通道拼接,通道洗牌和通道分割可以合并成1个element-wise操作,也是为了满足G4。
最后当需要降采样的时候我们通过不进行通道分割的方式达到通道数量的加倍,如图6.(d),非常简单。
ShuffleNet v2和DenseNet
ShuffleNet v2能够得到非常高的精度是因为它和DenseNet有着思想上非常一致的结构:强壮的特征重用(Feature Reuse)。在DenseNet中,作者大量使用的拼接操作直接将上一层的Feature Map原汁原味的传到下一个乃至下几个模块。从6.(c)中我们也可以看处,左侧的直接映射和DenseNet的特征重用是非常相似的。
不同于DenseNet的整个Feature Map的直接映射,ShuffleNet v2只映射了一半。恰恰是这一点不同,是ShuffleNet v2有了和DenseNet的升级版CondenseNet[8]相同的思想。在CondenseNet中,作者通过可视化DenseNet的特征重用和Feature Map的距离关系发现距离越近的Feature Map之间的特征重用越重要。ShuffleNet v2中第 i 个和第 i + j 个Feature Map的重用特征的数量是 ![]() 。也就是距离越远,重用的特征越少。
。也就是距离越远,重用的特征越少。
总结
截止本文截止,ShuffleNet算是将轻量级网络推上了新的巅峰,两个版本都有其独到的地方。
ShuffleNet v1中提出的通道洗牌(Channel Shuffle)操作非常具有创新点,其对于解决分组卷积中通道通信困难上非常简单高效。
ShuffleNet v2分析了模型性能更直接的指标:运行时间。根据对运行时间的拆分,通过数学证明或是实验证明或是理论分析等方法提出了设计高效模型的四条准则,并根据这四条准则设计了ShuffleNet v2。ShuffleNet v2中的通道分割也是创新点满满。通过仔细分析通道分割,我们发现了它和DenseNet有异曲同工之妙,在这里轻量模型和高精度模型交汇在了一起。
ShuffleNet v2的证明和实验以及最后网络结构非常精彩,整篇论文读完给人一种畅快淋漓的感觉,建议读者们读完本文后拿出论文通读一遍,你一定会收获很多。
参考:ShuffNet v1 和 ShuffleNet v2 - 知乎