在MDP系列博客中,我们以一个Agent在4*3网格中寻找终点最优的路径策略为例,论述了MDP问题的原理和求解。有了MDP讲解作为基础之后,我们就可以正式的切入到“强化学习”的学习中来了。强化学习的目的是通过观测到的reward来为当前环境学习一个(近似)最优的策略。在MDP系列问题中,我们有一个完整的环境模型并且reward函数也是已知的。
在本文中我们将假设一个fully observable的环境(即当前状态可以通过每一步的感知获取)。另一方面,我们假设Agent 不知道环境是如何运行或者agent的动作是如何执行的,即我们允许出现概率动作结果。因此,agent面临的是一个未知的马尔科夫决策过程问题。首先,我们介绍三种agent的运行模式:
- Utility-based agent:学习状态的一个效用函数,并使用该函数来选择使得效用期望值最大化的动作。
- Q-LEARNING:学习一个动作-效用函数,或者称之为Q-function,即在给定state的情况下分析给定动作的效用期望。
- Reflex agent:直接学习一个从state到actions的映射。
其中,utility-based agent必须有一个明确的环境模型,明确知道采用一个action将导致什么样的states。Q-learning agent可以通过比较当前可用选择对应的效用期望,它并不需要知道他们的结果,因此明确的环境模型并非是必须的。另一方面,由于他们并不知道动作所导致的结果,Q-learning不能够对未来进行展望, 因此它的学习能力也会受到限制,后面将对此进一步介绍。
我们将介绍两种学习的策略,分别是passive learning 和active learning。其中passive learning中agent的策略是固定的,其目标是学习状态的效用(或状态-动作对)(记住这个目标哦,很重要),这也同时包括学习一个环境模型。Active learning中,agent同样需要学习该怎么做,其关键的问题是探索(exploration):即一个agent必须尽可能对环境进行探索以便学习得到如何应对。本文的重点是介绍passive learning!
1 Passive learning
在passive learning中agent的策略π是固定的:即在状态s上,将总是执行动作π (s),其目标仅仅只是学习策略π有多好,即学习效用函数![]() 。我们同样以MDP中4*3网格作为环境,使用一个fully observable 环境示例来对passive learning agent 进行讲解(如下图所示)。
。我们同样以MDP中4*3网格作为环境,使用一个fully observable 环境示例来对passive learning agent 进行讲解(如下图所示)。
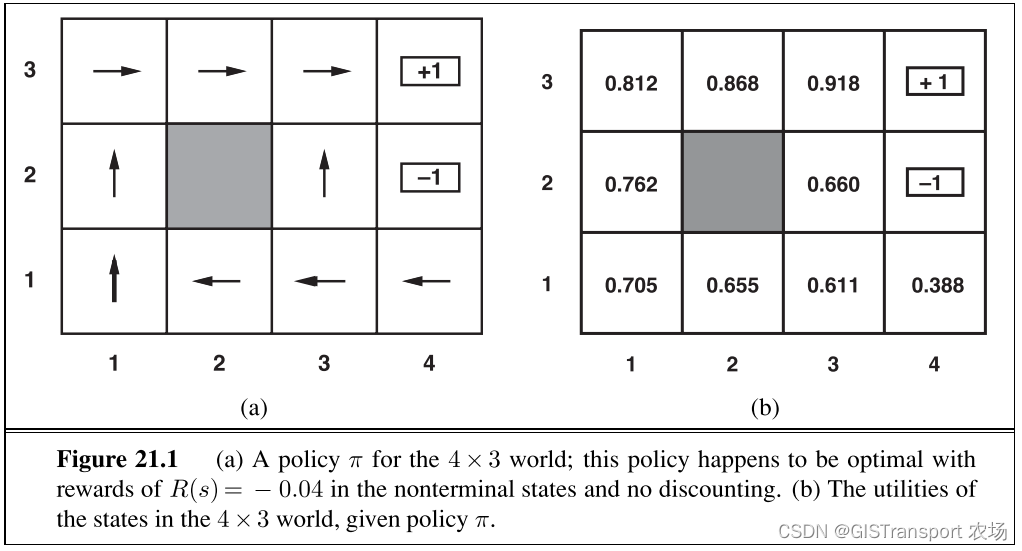
Passive learning 和policy evaluation 任务有类似之处,关键的区别在于passive learning agent 并不知道transition model P( s' | s, a)(即在动作s下执行动作a之后得到状态 s' 的概率)。同时,passive learning 也不知道每一个状态对应的reward。
在passive learning中,agent使用策略π进行一系列的尝试(trails),在每一个状态中agent从起点开始经历一系列的转换知道终止点(4,3)或者(4,2)才停止。它的感知输入包括当前的状态和对应reward,下面展示一些典型的尝试结果:
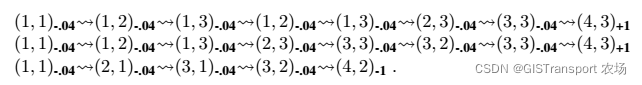
注意,上式中每一个状态带有一个下标来表示该状态感知得到的reward,其目标是rewards的信息来学习非终止状态的效用期望![]() 。其对应公式描述如下:
。其对应公式描述如下:

其中![]() 指的是在执行策略
指的是在执行策略![]() 后,时刻t上对应的状态(随机变量),
后,时刻t上对应的状态(随机变量),![]() = s,γ 为discount 因素,当前我们将其设置为γ = 1
= s,γ 为discount 因素,当前我们将其设置为γ = 1
1.1 Directed utility estimation
在1950年代,adaptive control theory领域,Widrow and Hoff 提供了一种称之为Directed utility estimation(直接效用估计),即一个状态的效用等于自该状态开始后到结束所有reward的期望值(被称之为reward-to-go)。在直接效用估计中,每一次尝试(trail)则为其经过的状态提供了效用的一个样本。
例如,在上述三次尝试中,第一次尝试提供的关于状态(1,1)效用的样本值为0.72, (1,2)的效用样本值为0.76 和0.84,同理,(1,3)的效用值样本为0.80 和0.88,以此类推。在每一次trail 结束之后对状态的utility进行更新,更新的方式是通过取平均值。在有限次的trail 之后,state utility 最终将实现收敛。
直接效用估计法实际上是将reinforcement learning简化为 inductive learning 问题。该方法实际上是一个监督问题,即以state 为输入,以观测到reward-to-go为输出。该方法存在的一个问题是没有考虑states的效用之间并非是相互独立的,因为一个state的utility等于它自身的reward 外加他之后的states的expected utility。即对于一个固定策略而言,效用遵循的Bellman公式如下:
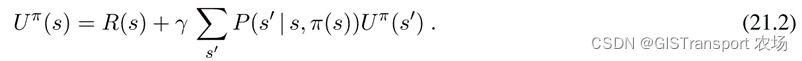
在忽略状态之间关系的情况下,直接效用估计会导致错失学习的机会。比如说在上述三次尝试中的第二次中,首次通过了状态(3,2),且其后的状态为(3,3),根据bellman 公式我们在第一个trail中已经知道了(3,3)的utility很高,而(3,3)又和(3,2)直接相连,因此也可以推断出(3,2)的效用应该也会比较高。但是如果只是单独使用directed utility estimation,那么在第二次trail结束之前,我们并不知道(3,2)的效用是多少。因此我们可以将直接效用估计理解为在一个比需要更大的假设空间中来找到效用,在很多情况下他的局部解会和Bellman等式相冲突,即不满足在固定policy条件下的Bellman等式的关系(公式如下如21.2)。
1.2 Adaptive dynamic programming
Adaptive dynamic programming (or ADP) agent 利用states 效用之间的限制关系学习的状态转移模型,并通过动态规划的方式来求解对应MDP问题。对于一个passive learning问题,这意味通过将学习得到的![]() 和观测得到的R (s),代入到公式21.2中来计算得到states的效用。正如我们在马尔科夫决策过程原理和求解讲解的,对于固定的policy,states的utilities 可以进行线性求解,也可以使用modified policy iteration 进行求解。
和观测得到的R (s),代入到公式21.2中来计算得到states的效用。正如我们在马尔科夫决策过程原理和求解讲解的,对于固定的policy,states的utilities 可以进行线性求解,也可以使用modified policy iteration 进行求解。
这里的关键问题之一是对的![]() 进行学习,由于我们的环境是fullly observable 的,因此可以直接采用基于统计的方法来对其进行估计。具体实现上,我们可以通过统计得到在s状态下执行a动作得到
进行学习,由于我们的环境是fullly observable 的,因此可以直接采用基于统计的方法来对其进行估计。具体实现上,我们可以通过统计得到在s状态下执行a动作得到![]() 的概率是多少。对应算法原理如下图所示:
的概率是多少。对应算法原理如下图所示:

其对的性能测评如下图所示:
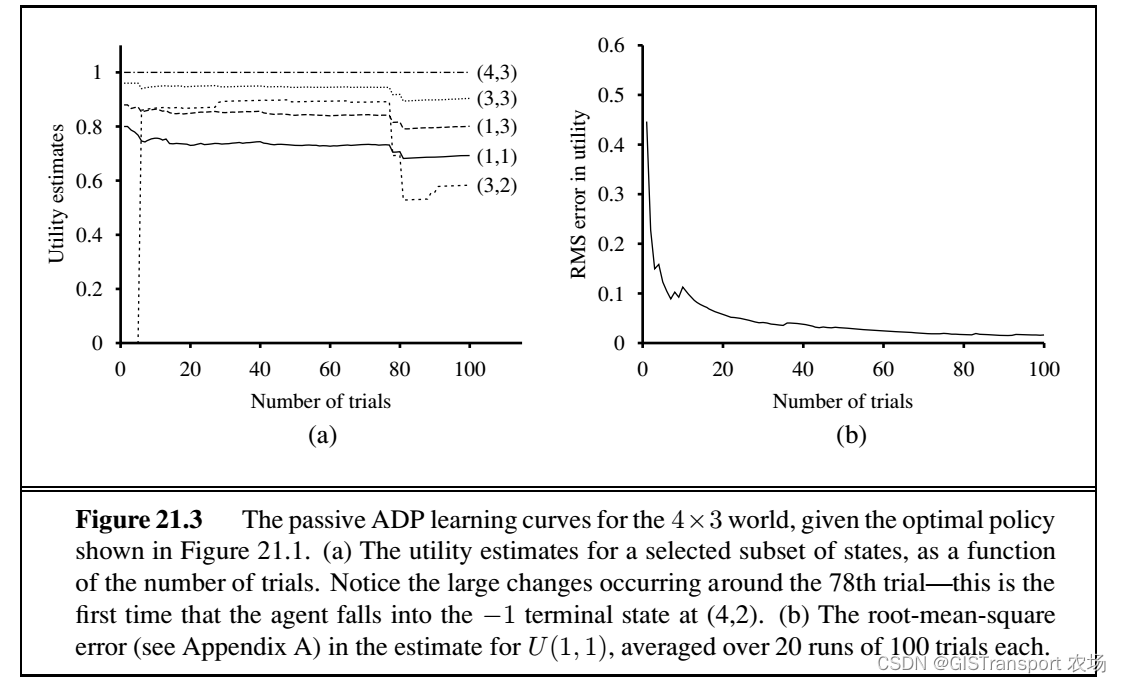
实际上算法的收敛速度主要取决于转移概率的学习速度,在一个4*3的环境下,这个可能比较简单。但是在一个巨大的状态空间环境下,转移概率的学习可能需要很长时间。这种单纯基于估计的模型,实际是一种最大似然估计。由于其计算是基于最大估计所以有可能会导致错误。解决的办法有两种,分别是贝叶斯强化学习(Bayesian reinforcement learning)和 鲁棒控制理论(robust control theory)。
1.3 Temporal-difference (TD) learning
这一节我们介绍另一种passive learning问题的求解方式。采用的是通过观测的转移来调整观测状态的utilities,以便使得状态符合Bellman等式。照旧,我们以下面三次trail作为示例。
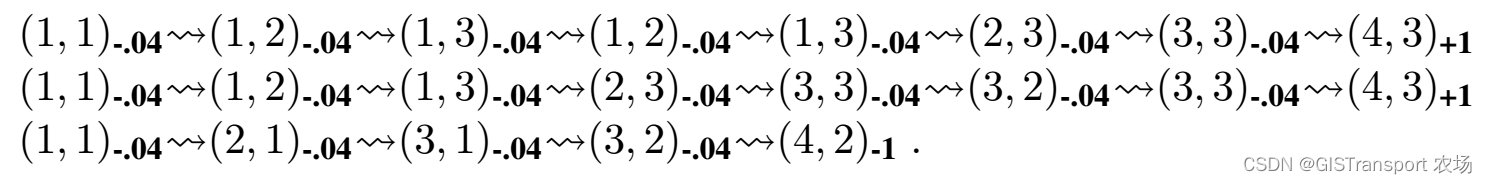
假设在第一轮trail结束之后,我们有![]() ,
, ![]() ,在第二轮中(1,3)到(2,3)之间存在转换。假设总是发生这个转换,那么我们有:
,在第二轮中(1,3)到(2,3)之间存在转换。假设总是发生这个转换,那么我们有:
![]()
由此可知![]() ,也就是说当前
,也就是说当前![]() 可能偏小需要对其进行调整。更加通用的讲,当发生一个从状态s到 s' 的一个转换,我们对
可能偏小需要对其进行调整。更加通用的讲,当发生一个从状态s到 s' 的一个转换,我们对![]() 做如下更新:
做如下更新:
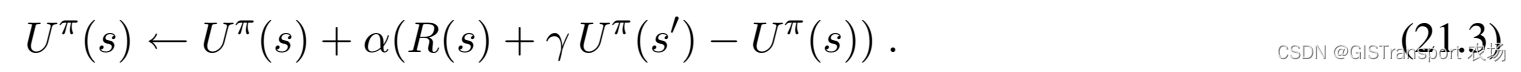
其中的![]() 称之为学习率,由于计算中存在两个相邻状态效用的差值,因此被称之为temporal-difference。和公式21.2相比,这里我们仅仅只考虑了实际观测到的下一个状态 s' ,并没有考虑其对应的转换概率。这里可能大家会疑惑如果 s' 对应的是一个小概率事件,那么对
称之为学习率,由于计算中存在两个相邻状态效用的差值,因此被称之为temporal-difference。和公式21.2相比,这里我们仅仅只考虑了实际观测到的下一个状态 s' ,并没有考虑其对应的转换概率。这里可能大家会疑惑如果 s' 对应的是一个小概率事件,那么对![]() 的调整可能不对。实际上由于小概率事件发生的概率也会比较小。因此
的调整可能不对。实际上由于小概率事件发生的概率也会比较小。因此![]() 的平均值(average value)最终将会收敛。另外,如果随着状态s被访问次数增加,我们将α值大小,那么值
的平均值(average value)最终将会收敛。另外,如果随着状态s被访问次数增加,我们将α值大小,那么值![]() 本身(即非平均值)最终将实现收敛。
本身(即非平均值)最终将实现收敛。
该算法对应的伪代码和算法性能如下面两个图所示:

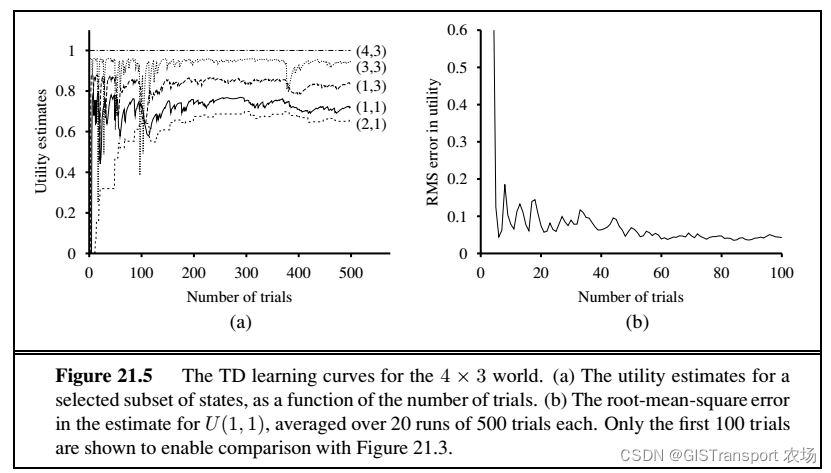
相对于Adaptive dynamic programing (ADP),TD收敛的速度更慢,但是计算量更小,方法更加的简单(不需要估计transition probobility)。实际上TD和ADP算法两者的联系非常的紧密,TD基于每一次观测来进行调整,而ADP则是基于所以可能的状态及其对应概率来进行调整。两者都对Bellman等式进行了考虑。从某个角度来讲,我们可以认为ADP是一种更加粗糙形式的TP。当然也可以使用一些启发式算法来提高ADP的计算效率,如prioritized sweeping heuristic 算法(此处不再累述)。
后记:
关于代码的实现,这里不再单独给出,原因是在passive learning 当中,current state s' 和reward 是通过感知(percept)的输入得到,所以在程序设计当中需要根据实际应用情况来更新percept,等回头有更加确切的例子我再更新。