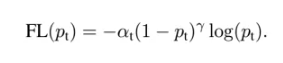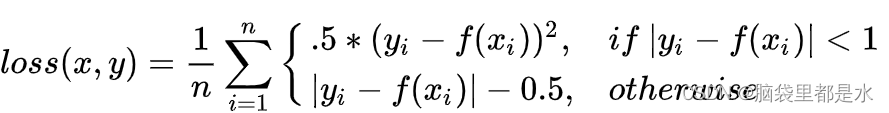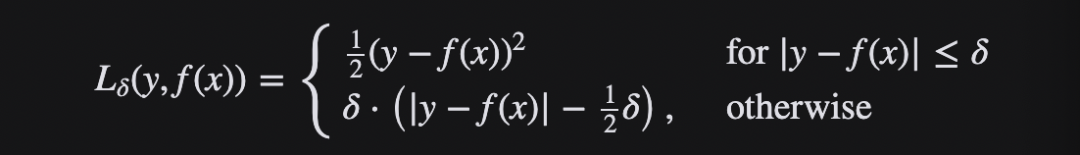Dice Loss 最先是在VNet 这篇文章中被提出,后来被广泛的应用在了医学影像分割之中。
Dice系数作为损失函数的原因和混淆矩阵有着很大的关系,下图给出的是一个混淆矩阵:
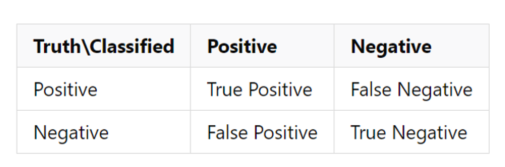
其中的一些关键指标如下:
精确率(precision)表示的是预测为正且真实为正的占预测为正的比例
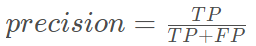
召回率(recall)表示的是预测为正且真实为正的占样本为正的比例
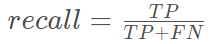
在医学图象分割的时候我们希望这两个值越大越好,但是精确率和召回率是相互制约的,精确率越高则召回率相对较低,精确率越低则召回率相对较高。
由此引入F1-score:
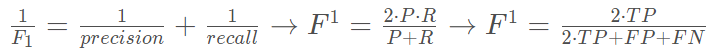
显然,F1-score的值是越大越好的,并且符合损失函数的定义,我们可以把它作为损失函数来使用。但是我们经常使用的损失函数是越小越好的,我们往往使用1-F1-score来作为损失函数。
Dice系数, 根据 Lee Raymond Dice[1] 命名,是一种集合相似度度量函数,通常用于计算两个样本的相似度(值范围为 [0, 1]):
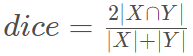
∣X∩Y∣表示X和Y之间的交集,∣ X ∣ 和∣ Y ∣ 分别表示X和Y的元素个数,其中,分子中的系数 2,是因为分母存在重复计算 X 和 Y 之间的共同元素的原因.
在语义分割问题中,X表示GT分割图像, Y表示Pred 分割图像.
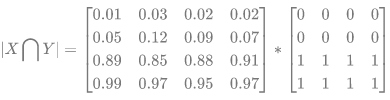
预测的分割图的 dice 系数计算,首先将∣ X ∩ Y ∣近似为预测图与 GT 分割图之间的点乘,并将点乘的元素结果相加:
(1) - Pred 预测分割图与 GT 分割图的点乘:
(2) - 逐元素相乘的结果元素的相加和:
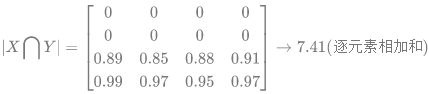
对于二分类问题,GT 分割图是只有 0, 1 两个值的,因此∣ X ∩ Y ∣可以有效的将在 Pred 分割图中未在 GT 分割图中激活的所有像素清零. 对于激活的像素,主要是惩罚低置信度的预测,较高值会得到更好的 Dice 系数.
关于∣ X ∣和∣ Y ∣ 的量化计算,可采用直接简单的元素相加;也有采用取元素平方求和的做法:


带来的好处:
(1)避免当|X|和|Y|都为0时,分子被0除的问题
(2)减少过拟合
注意:
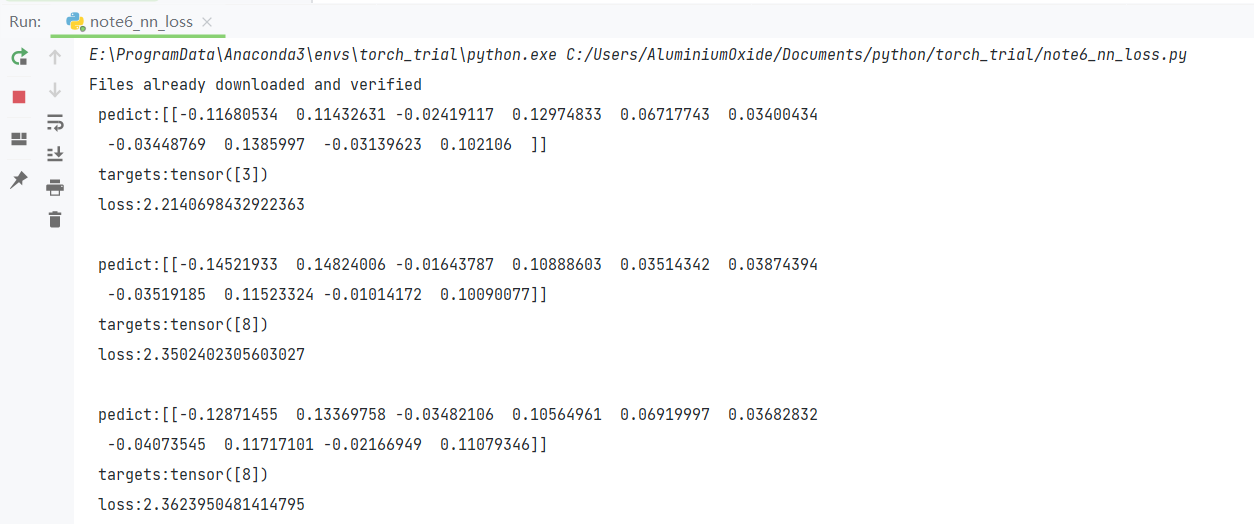
dice loss 对正负样本严重不平衡的场景有着不错的性能,训练过程中更侧重对前景区域的挖掘。但训练loss容易不稳定,尤其是小目标的情况下。另外极端情况会导致梯度饱和现象。因此有一些改进操作,主要是结合ce loss等改进,比如: dice+ce loss,dice + focal loss等
因为dice loss是一个区域相关的loss。区域相关的意思就是,当前像素的loss不光和当前像素的预测值相关,和其他点的值也相关。dice loss的求交的形式可以理解为mask掩码操作,因此不管图片有多大,固定大小的正样本的区域计算的loss是一样的,对网络起到的监督贡献不会随着图片的大小而变化。dice loss训练更倾向于挖掘前景区域,正负样本不平衡的情况就是前景占比较小。而ce loss 会公平处理正负样本,当出现正样本占比较小时,就会被更多的负样本淹没。
在使用dice loss时,一般正样本为小目标时会产生严重的震荡。因为在只有前景和背景的情况下,小目标一旦有部分像素预测错误,那么就会导致loss值大幅度的变动,从而导致梯度变化剧烈。可以假设极端情况,只有一个像素为正样本,如果该像素预测正确了,不管其他像素预测如何,loss 就接近0,预测错误了,loss 接近1。而对于ce loss,loss的值是总体求平均的,更多会依赖负样本的地方。
from keras import backend as K
smooth = 1. # 用于防止分母为0.
def dice_coef(y_true, y_pred):y_true_f = K.flatten(y_true) # 将 y_true 拉伸为一维.y_pred_f = K.flatten(y_pred)intersection = K.sum(y_true_f * y_pred_f)return (2. * intersection + smooth) / (K.sum(y_true_f * y_true_f) + K.sum(y_pred_f * y_pred_f) + smooth)def dice_coef_loss(y_true, y_pred):return 1. - dice_coef(y_true, y_pred)
转载于:https://blog.csdn.net/weixin_38324954/article/details/116229663?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165214381316782350920284%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=165214381316782350920284&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_click~default-1-116229663-null-null.142v9control,157v4control&utm_term=dice+loss&spm=1018.2226.3001.4187