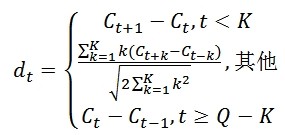我的新书《Android App开发入门与实战》已于2020年8月由人民邮电出版社出版,欢迎购买。点击进入详情
文章目录
- 1. JSONPlaceholder
- 2. Fake Store API
- 3. Unsplash API
- 4. Quotes API
- 5. RandomUser
- 6. Coingecko

API 集成服务有助于提高开发人员的开发性能并节省大量时间。
1. JSONPlaceholder
JSONPlaceholder是一个流行的前端开发API。JSON 代表 JavaScript 对象表示法,称为开发人员的图像占位符。最初,开发人员使用JSONPlace holder进行原型设计和测试。
此外,JSONPlaceholder提供了一个假的REST API。这是一项在线服务,可以随时随地访问。填补测试过程中的空白这个也很受欢迎。
JSONPlaceholder 的特性:
-
开发人员不需要任何注册
-
无需配置
-
有助于自动创建基本 API
-
与数据共享多个连接
-
整合跨域,如 CORS 和 JSONP
-
高度支持一些请求,包括POST,PATCH,PUT等等
-
与不同的Javascript框架和库兼容,包括Angular.js,Backbone等等。
-
为多个资源(如帖子、评论、相册、照片、待办事项和用户)提供restful API
2. Fake Store API
提供以下资源:
- 产品
- 车
- 用户
- 登录令牌
3. Unsplash API
Unsplash API 是一个现代 JSON API。它是最强大的照片引擎,提供600k +免费,高质量,高清,免许可的照片。开发人员可以零成本使用所有可用的映像。
-
图片可用于个人和商业用途
-
Unsplash API是免费使用的,易于设置
-
Unsplash API的主要优点是它快速灵活
-
不需要任何高级计划(许可证和订阅)
-
照片根据Unsplash许可证获得许可
关于Unsplash的官方网站,
-
4200 多万张照片下载/月
-
每月投放 80 多亿张照片
-
下载 16 张照片/秒
-
97k+ 摄影师,被 5000 多万创意人员使用
开发人员可以通过关键字、随机图像和多个数据集轻松搜索照片。
4. Quotes API
Quotes API 提供所有类型的报价,包括:
-
今日报价
-
按类别报价
-
随机选择的报价
-
作者语录
-
按受欢迎程度报价
5. RandomUser
随机用户 API 对初学者有益,它提供了随机生成的用户,可用作测试目的的占位符。
-
使该工具类似于Lorem Ipsum
-
人员可用,而不是文本
-
随机用户 API 可以返回多个结果,
-
指定生成的用户详细信息,例如姓名、电子邮件、用户名、地址、职务、性别、国家/地区等
6. Coingecko
它被称为最全面的加密货币API,Coingecko是满足所有加密需求的一站式平台。还有更多的API可用,但Coingecko被认为是所有API中最好的。
要使用Coingecko API,开发人员不需要任何API密钥,它是免费使用的,并且是副项目的最佳平台。
Coingecko API提供:
-
硬币价格
-
所有硬币列表
-
价格历史
-
市场图表
-
价格狂潮
-
合同
-
交易平台
-
交流