一.引用
parquet 文件常见于 Spark、Hive、Streamin、MapReduce 等大数据场景,通过列式存储和元数据存储的方式实现了高效的数据存储与检索,下面主要讲 parquet 文件在 spark 场景下的存储,读取与使用中可能遇到的坑。

二.Parquet 加载方式
1.SparkSession.read.parquet
SparkSession 位于 org.apache.spark.sql.SparkSession 类下,除了支持读取 parquet 的列式文件外,SparkSession 也支持读取 ORC 列式存储文件,可以参考: Spark 读取 ORC FIle
val conf = new SparkConf().setAppName("ParquetInfo").setMaster("local")val spark = SparkSession.builder.config(conf).getOrCreate()spark.read.parquet(path).foreach(row => {val head = row.getString(0)println(head)})读取后会获取一个 Sql.DataFrame,支持常见的 sql 语法操作,如果不想使用 sql 才做也可以通过 .rdd 的方法得到 RDD[Row],随后遍历每个 partition 下的 Iterator[Row] 即可。
Tips:
后续可以执行 sql 操作,当然也支持初始化 SqlContext 调用 sql 方法,不过用 SparkSession 也可以搞定。
val parquetFileDF = spark.read.parquet("path")parquetFileDF.createOrReplaceTempView("tableName")val resultDf = spark.sql("SELECT * FROM tableName")val sqlContext = new SQLContext(sc)sqkContext.sql("xxx")2.SparkContext.HadoopFile
使用 hadoopFile 读取时需要指定对应的 K-V 以及 InputFormat 的格式,Parquet 文件对应的 K-V 为 Void-ArrayWritable,其 InputFormat 为: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat,获取 ArrayWritable 后通过索引可以获得 Writable。
val sc = spark.sparkContextsc.setLogLevel("error")val parquetInfo = sc.hadoopFile(path, classOf[MapredParquetInputFormat], classOf[Void], classOf[ArrayWritable])parquetInfo.take(5).foreach(info => {val writable = info._2.get()val head = writable(0)println(writable.length + "\t" + head)})Tips:
需要在 SparkConf 中加入序列化的配置,否则 hadoopFile 方法会报错:

.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")writable 需要通过反序列化的方式才能再获取具体内容,所以这里推荐使用 SparkSession 的官方 api 读取,不过可以 RcFile SparkSession 暂不支持直接读取,所以可以用 sc.hadoopRdd 的方法读取同样列式存储的 RcFile 格式文件,可以参考: Spark 读取 RcFile
三.Parquet 存储方式
1.静态转换
Parquet -> Parquet,读取 parquet 生成 Sql.DataFrame 再转存,类似 RDD 的 transform:
spark.read.parquet(path).write.mode(SaveMode.Overwrite).option("timestampFormat", "yyyy/MM/dd HH:mm:ss ZZ").format("parquet").save("/split")2.RDD[T*] 转换
常规数据 RDD 可以通过加入 import sqlContext.implicits._ 隐式转换的方式由 RDD 转换为 sql.Dataframe,随后完成 parquet 的存储,下面掩饰一个 PairRDD 转换为 df 并存储的方法:
import sqlContext.implicits._val commonStringRdd = sc.emptyRDD[(String, String)].toDF()commonStringRdd.write.mode(SaveMode.Overwrite).format("parquet").save("")Tips:
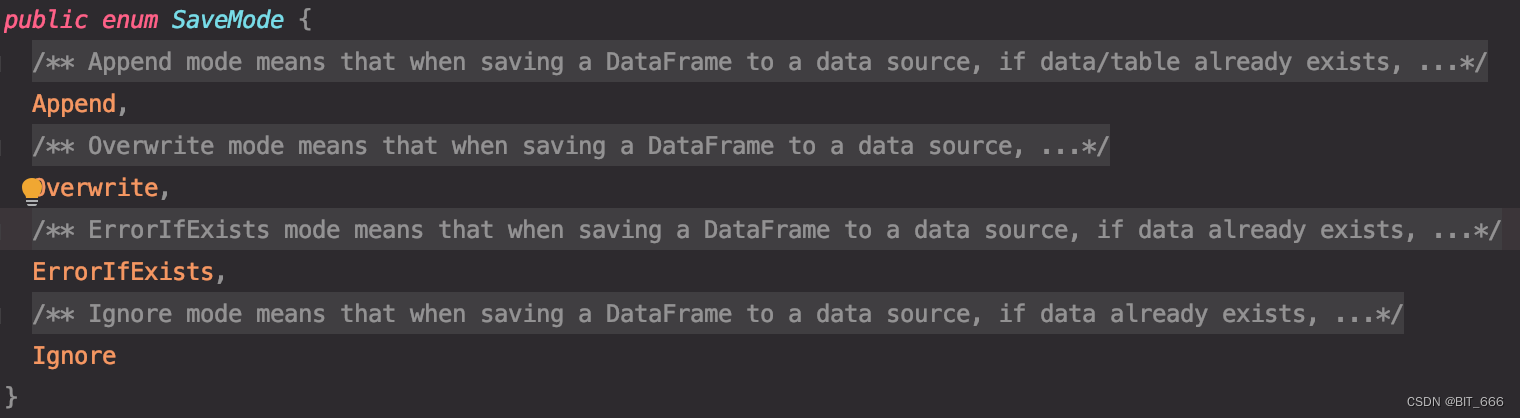
SaveModel 分为 Append 追加、Overwrite 覆盖、ErrorIfExists 报错、Ignore 忽略四种模式,前两个比较好理解,后面两个前者代表如果地址已存在则报错,后者如果地址已存在则忽略且不影响原始数据。SaveModel 通过枚举 Enum 的方式实现:
详细的 RDD 转换 Sql.DataFrame 可以参考:Spark - RDD / ROW / sql.DataFrame 互转 。
3.RDD[Row] 转换
如果有生成的 RDD[Row] 就可以直接调用 sqlContext 将该 RDD 转换为 DataFrame。这里 TABLE_SCHEMA 可以看作是每一列数据的描述,类似 Hive 的 column 的信息,主要是字段名和类型,也可以添加额外的信息,sqlContext 将对应的列属性与 Row 一一匹配,如果 Schema 长度没有达到 Row 的总列数,则后续字段都只能读为 Null。
val sqlContext = new SQLContext(sc)final val TABLE_SCHEME = StructType(Array(StructField("A", StringType),StructField("B", StringType),StructField("C", StringType),StructField("D", StringType),StructField("E", StringType),StructField("F", StringType),StructField("G", StringType),StructField("H", StringType)))val commonRowRdd = sc.emptyRDD[Row]sqlContext.createDataFrame(commonRowRdd, TABLE_SCHEME).write.mode(SaveMode.Overwrite).format("parquet").save("/split")Tips:
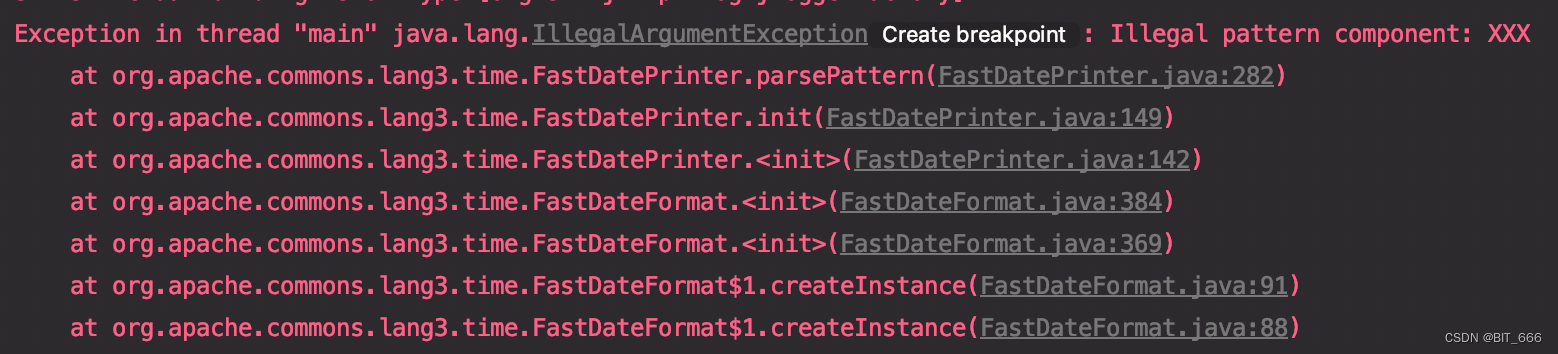
使用上述语法读取时可能会报错: Illegal pattern component: XXX ,这是因为内部 DataFormat 解析的问题,在代码中加入 .option("timestampFormat", "yyyy/MM/dd HH:mm:ss ZZ") 即可。
spark.read.option("timestampFormat", "yyyy/MM/dd HH:mm:ss ZZ").parquet(path)四.Parquet 浅析
Parquet 由于其开源,支持多平台多系统以及高效的存储和编码方案,使得其非常适合大数据场景下的任务开发,下面简单看下他的两个特性,列式存储和元数据存储:
1.列式存储 - 更小的 IO
CSV 是最常见的行式存储,对于一些需要单独特征或列的场景,如果是 CSV 文件需要遍历整行并分割,最终获取目标元素,而 Parquet 方式通过列式存储,对于单独的特征可以直接访问,从而提高了执行的效率,减少了数据 IO。
CSV: A,B,C,D,E -> Split(",")[col]
Parquet: A B C D E -> getString(col)2.元数据存储 - 更高的压缩比
Parquet 采用多种编码 encoding 方式,保证数据的高效存储和低空间
A.Run Length encoding
游程编码,当一行的多列数据有很多重复数据时,可以通过 "X重复了N次" 的记录方法,缩小记录的成本,虽然 N 可能很大,但存储成本很小:
[1,2,1,1,1,1,2] -> 1-1,2-1,1-4,2-1
B.Dictionary encoding
字典编码,顾名思义就是通过映射,保存重复过多的数据,例如 "0" -> "LongString":
[LongString, LongString, LongString] -> [0, 0, 0]
C.Delta encoding
增量编码,适用于 unix 时间戳,时间戳记录为 1970年1月1日以来的秒数,存储时间戳时可以直接减去初始时间戳,减少存储量,比如 1577808000 作为基准,则可以减少很多存储空间:
[1577808000, 1577808004, 1577808008] -> [0, 4, 8]
3.存储-压缩对比
val st = System.currentTimeMillis()val pairInfo = (0 to 1000000).zipWithIndex.toArrayval format = "csv" // csv、json、parquetsc.parallelize(pairInfo).toDF("A", "B").write.mode(SaveMode.Overwrite).option("timestampFormat", "yyyy/MM/dd HH:mm:ss ZZ").save(s"./output/$format")val saveType = "gzip" // text、gzipsc.parallelize(pairInfo).saveAsTextFile(s"./output/$saveType", classOf[GzipCodec])val cost = System.currentTimeMillis() - stprintln(s"耗时: $cost")使用上述两种方法分别将 0 到 1000000 的数组存到对应文件,看一下存储的大小:
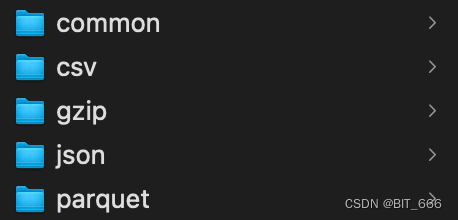
| 类型 | Text | Gzip | Parquet | CSV | JSON |
| 大小(MB) | 15.8 | 4.6 | 8 | 13.8 | 23.8 |
相比于表格数据 CSV 和 JSON 存储,parquet 提供了更高的压缩比,Amazon S3 集群曾经对比过 CSV 与 parquet 的效率对比,使用 Parquet 可以缩减 87% 的大小,查询的速度快 34 倍 同时可以节省 99.7 的成本,所以在大数据量加经常需要个别列操作的场景下,Parquet 非常适合。
4.读取-效率对比
再分别读取上述文件:
val csv = spark.read.csv(path + "/output/csv").rdd.count()val parquet = spark.read.parquet(path + "/output/parquet").rdd.count()val json = spark.read.json(path + "/output/json").count()val common = sc.textFile(path + "/output/common").count()val gz = sc.textFile(path + "/output/gzip").count()| 类型 | Text | Gzip | Parquet | CSV | JSON |
| 耗时(ms) | 1417 | 1448 | 4952 | 6870 | 6766 |
相比 CSV,JSON 是有优势的,但是相对于行数存储的 Text 和 Gzip,执行 count 类的行统计操作显然不是列式存储文件的强项,所以相差很多,如果是大数据下针对某个或几个字段统计,Parquet 会提供相比于行式存储文件更高的性能。
5.selectExpr

读取 Parquet 文件除了获取原始的字段内容外,也可以通过 selectExpr 操作获取更多额外的信息,方法位于 org.apache.spark.sql.functions 中,内部包含 collect_list 类似的聚合操作,也包含 count 类似的统计操作,还有 max、min、isnull 等等。
spark.read.parquet(path).selectExpr("count('_c1')").rdd.foreach(row => {println(row.getLong(0))})上述操作通过 selectExpr 获取了 count(_c1) 特征的数量,count Result:5383。
其中 _c1 为 Parquet 获取的 sql.DataFrame 的默认 schema,可以通过下述方法获取默认的 schema 信息:
val schema = spark.read.parquet(path).schemaprintln(schema)
这里截取了一部分,特征名从 _c0 开始依次累加,默认为 _c0,_c1 ,如果自己定义了 schema 的 StructField ,使用 spark.read.schema().parqeut() 读出来的 sql.Dataframe 的 selectExpr 函数内操作使用的列名就要换成自己定义的名称,例如 _c1 我定义为 age,则上述写法要改为 count('age'),再使用 _c1 会报错。更详细的 schema 操作可以参考:Parquet 指定 schema
五.总结
Spark - Parquet 大致常用的内容就这些,SparkSession 集成了读取 parquet、orc 的 API 非常的便捷,有需要建议直接通过 API 读取而不是 HadoopRdd / HadoopFile 。最后想说 parquet 的命名确实很好玩,parquet 翻译为地板,而不定长的列名存储,如果通过平面展示也颇有地板的感觉。