Parquet-format
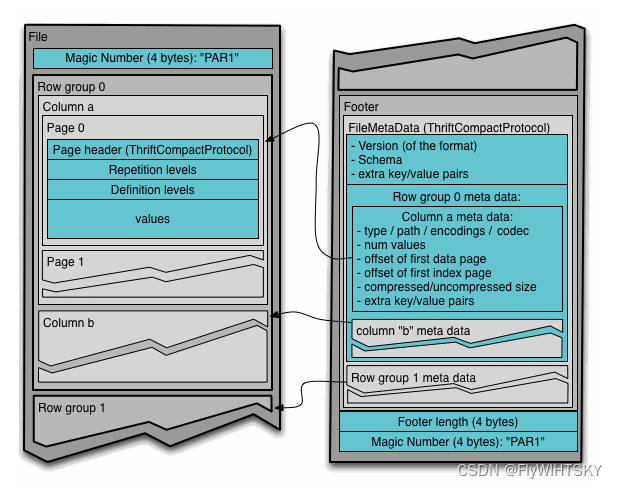
左边是文件开头及具体的数据,
右边是文件结尾的 Footer
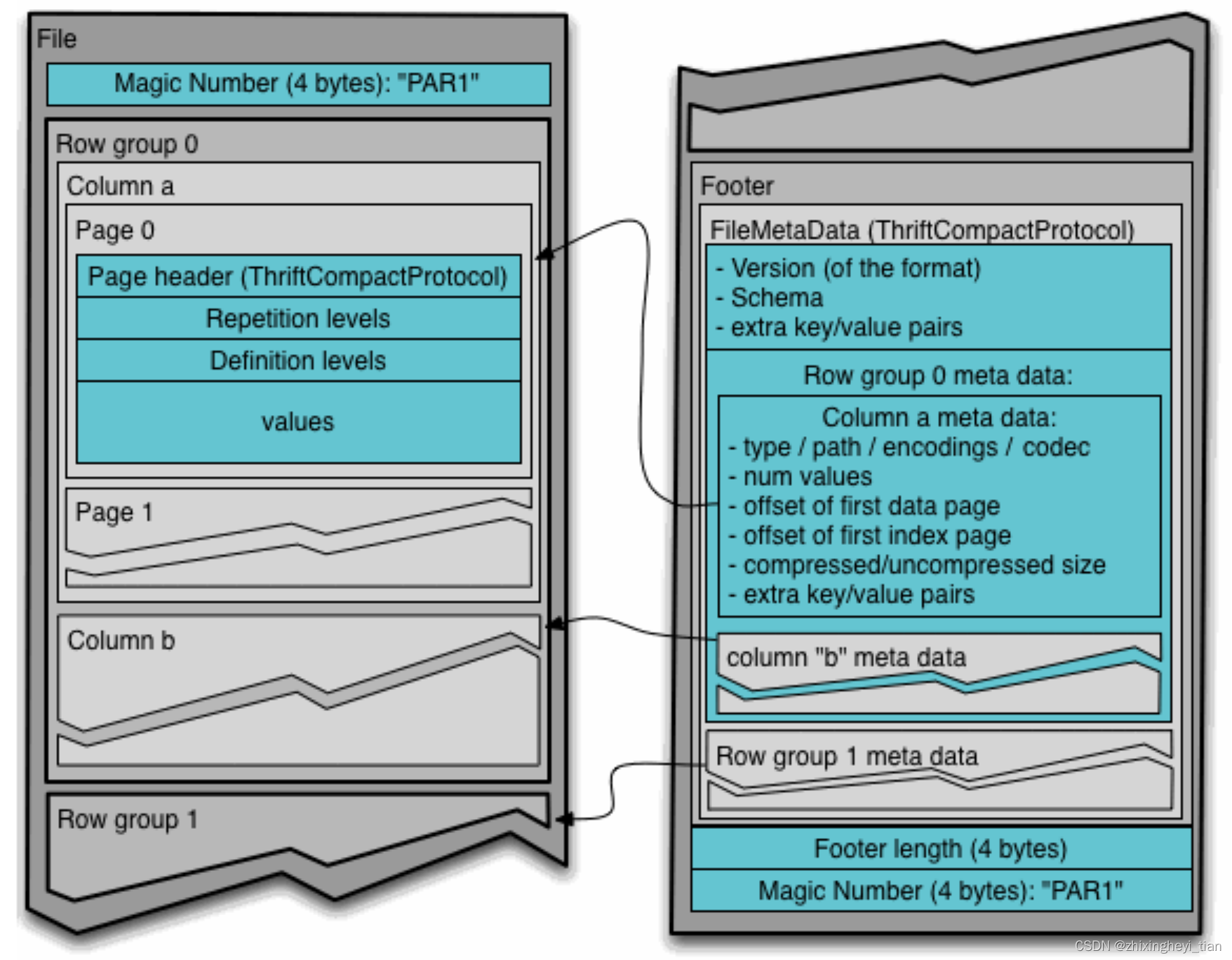
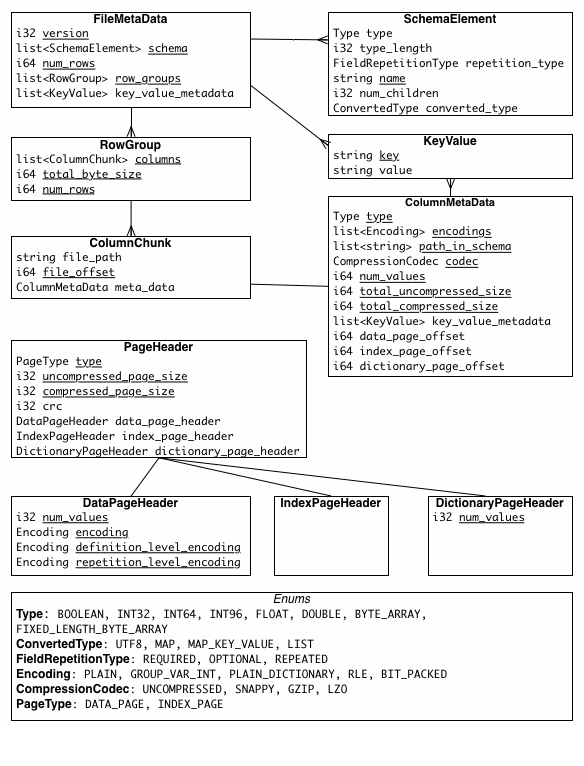
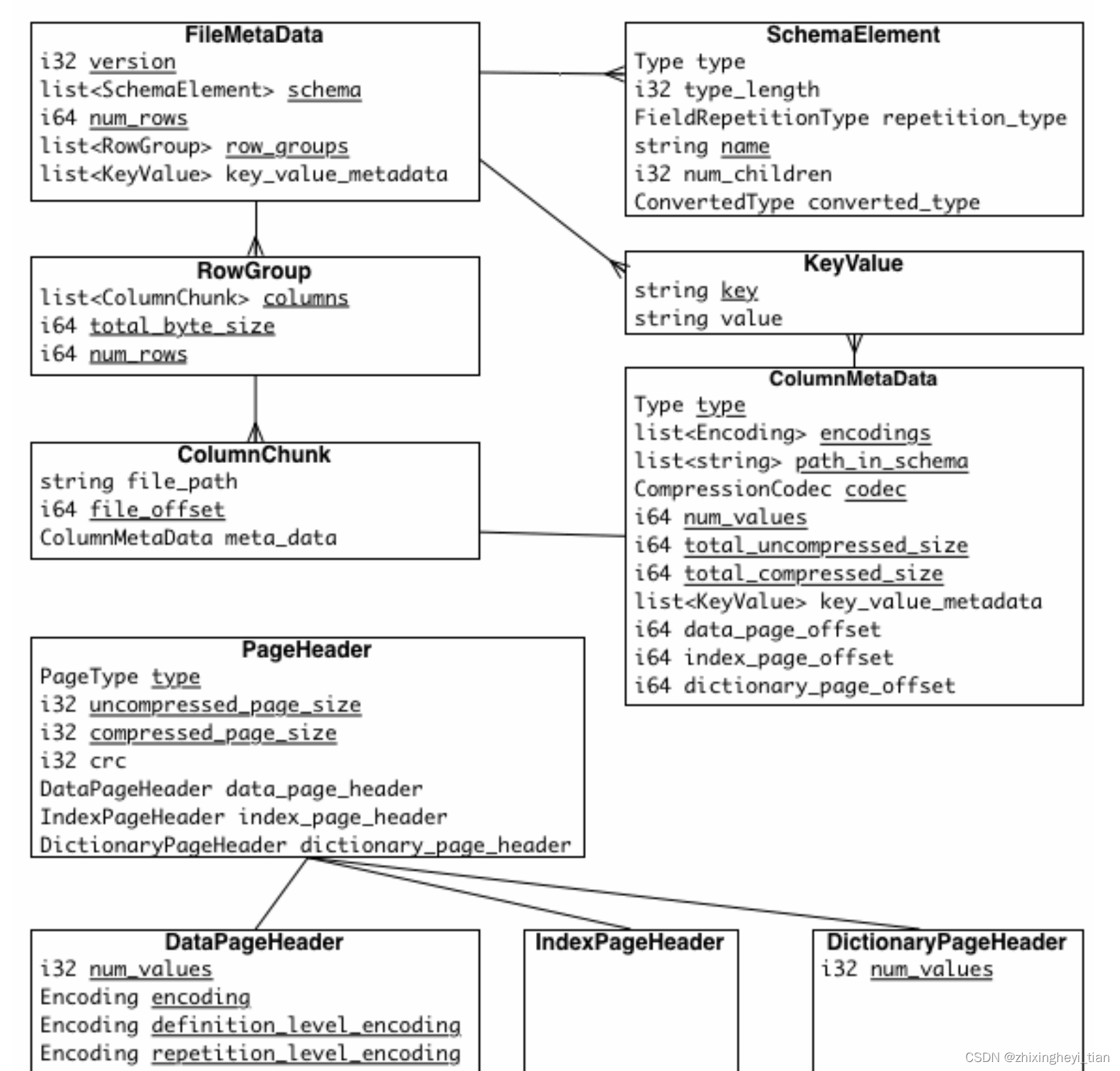
Metadata
There are three types of metadata: file metadata, column (chunk) metadata and page header metadata. All thrift structures are serialized using the TCompactProtocol.
Column chunks
- Column chunks are composed of pages written back to back.
- The pages share a common header and readers can skip over pages they are not interested in.
- The data for the page follows the header and can be compressed and/or encoded. The compression and encoding is specified in the page metadata.
dictionary page
- A column chunk might be partly or completely dictionary encoded. It means that dictionary indexes are saved in the data pages instead of the actual values. The actual values are stored in the dictionary page.
- The dictionary page must be placed at the first position of the column chunk.
- At most one dictionary page can be placed in a column chunk.
Additional Index Page
Additionally, files can contain an optional column index to allow readers to skip pages more efficiently.
Encoding
The dictionary encoding builds a dictionary of values encountered in a given column. The dictionary will be stored in a dictionary page per column chunk. The values are stored as integers using the RLE/Bit-Packing Hybrid encoding. If the dictionary grows too big, whether in size or number of distinct values, the encoding will fall back to the plain encoding. The dictionary page is written first, before the data pages of the column chunk.
Dictionary page format: the entries in the dictionary - in dictionary order - using the plain encoding.
Using the PLAIN_DICTIONARY enum value is deprecated in the Parquet 2.0 specification. Prefer using RLE_DICTIONARY in a data page and PLAIN in a dictionary page for Parquet 2.0+ files.
Run Length Encoding(RLE) / Bit-Packing Hybrid (RLE = 3)
rle-bit-packed-hybrid: <length> <encoded-data>
length := length of the <encoded-data> in bytes stored as 4 bytes little endian (unsigned int32)
encoded-data := <run>*
run := <bit-packed-run> | <rle-run>
bit-packed-run := <bit-packed-header> <bit-packed-values>
bit-packed-header := varint-encode(<bit-pack-scaled-run-len> << 1 | 1)
// we always bit-pack a multiple of 8 values at a time, so we only store the number of values / 8
bit-pack-scaled-run-len := (bit-packed-run-len) / 8
bit-packed-run-len := *see 3 below*
bit-packed-values := *see 1 below*
rle-run := <rle-header> <repeated-value>
rle-header := varint-encode( (rle-run-len) << 1)
rle-run-len := *see 3 below*
repeated-value := value that is repeated, using a fixed-width of round-up-to-next-byte(bit-width
Configurations
Row group size: Larger row groups allow for larger column chunks which makes it possible to do larger sequential IO. Larger groups also require more buffering in the write path (or a two pass write). We recommend large row groups (512MB - 1GB). Since an entire row group might need to be read, we want it to completely fit on one HDFS block. Therefore, HDFS block sizes should also be set to be larger. An optimized read setup would be: 1GB row groups, 1GB HDFS block size, 1 HDFS block per HDFS file.
Data page size: Data pages should be considered indivisible (不可分割的) so smaller data pages allow for more fine grained reading (e.g. single row lookup). Larger page sizes incur less space overhead (less page headers) and potentially less parsing overhead (processing headers). Note: for sequential scans, it is not expected to read a page at a time; this is not the IO chunk. We recommend 8KB for page sizes.
design
Repetition Level®, Definition Level(D)
对于嵌套数据类型,我们除了存储数据的value之外还需要两个变量Repetition Level®, Definition Level(D) 才能存储其完整的信息用于序列化和反序列化嵌套数据类型。Repetition Level和 Definition Level可以说是为了支持嵌套类型而设计的,但是它同样适用于简单数据类型。在Parquet中我们只需定义和存储schema的叶子节点所在列的Repetition Level和Definition Level。
complex type
每个schema的结构是这样的:根叫做message,message包含多个fields。每个field包含三个属性:repetition, type, name。
repetition可以是以下三种 (描述Value值):
- required(出现1次),
- optional(出现0次或者1次),
- repeated(出现0次或者多次)。
type可以是一个group或者一个primitive类型(int, float, boolean,string)。
AddressBook shema 的表示形式
message AddressBook {required string owner;repeated string ownerPhoneNumbers;repeated group contacts {required string name;optional string phoneNumber;}
}


parquet/arrow/reader.cc
GetRecordBatchReader
Status FileReaderImpl::GetRecordBatchReader(const std::vector<int>& row_groups,const std::vector<int>& column_indices,std::unique_ptr<RecordBatchReader>* out) {RETURN_NOT_OK(BoundsCheck(row_groups, column_indices));if (reader_properties_.pre_buffer()) {// PARQUET-1698/PARQUET-1820: pre-buffer row groups/column chunks if enabledBEGIN_PARQUET_CATCH_EXCEPTIONSARROW_UNUSED(reader_->PreBuffer(row_groups, column_indices,reader_properties_.io_context(),reader_properties_.cache_options()));END_PARQUET_CATCH_EXCEPTIONS}std::vector<std::shared_ptr<ColumnReaderImpl>> readers;std::shared_ptr<::arrow::Schema> batch_schema;RETURN_NOT_OK(GetFieldReaders(column_indices, row_groups, &readers, &batch_schema));if (readers.empty()) {// Just generate all batches right now; they're cheap since they have no columns.int64_t batch_size = properties().batch_size();auto max_sized_batch =::arrow::RecordBatch::Make(batch_schema, batch_size, ::arrow::ArrayVector{});::arrow::RecordBatchVector batches;for (int row_group : row_groups) {int64_t num_rows = parquet_reader()->metadata()->RowGroup(row_group)->num_rows();batches.insert(batches.end(), num_rows / batch_size, max_sized_batch);if (int64_t trailing_rows = num_rows % batch_size) {batches.push_back(max_sized_batch->Slice(0, trailing_rows));}}*out = ::arrow::internal::make_unique<RowGroupRecordBatchReader>(::arrow::MakeVectorIterator(std::move(batches)), std::move(batch_schema));return Status::OK();}int64_t num_rows = 0;for (int row_group : row_groups) {num_rows += parquet_reader()->metadata()->RowGroup(row_group)->num_rows();}using ::arrow::RecordBatchIterator;// NB: This lambda will be invoked outside the scope of this call to// `GetRecordBatchReader()`, so it must capture `readers` and `batch_schema` by value.// `this` is a non-owning pointer so we are relying on the parent FileReader outliving// this RecordBatchReader.::arrow::Iterator<RecordBatchIterator> batches = ::arrow::MakeFunctionIterator([readers, batch_schema, num_rows,this]() mutable -> ::arrow::Result<RecordBatchIterator> {::arrow::ChunkedArrayVector columns(readers.size());// don't reserve more rows than necessaryint64_t batch_size = std::min(properties().batch_size(), num_rows);num_rows -= batch_size;RETURN_NOT_OK(::arrow::internal::OptionalParallelFor(reader_properties_.use_threads(), static_cast<int>(readers.size()),[&](int i) { return readers[i]->NextBatch(batch_size, &columns[i]); }));for (const auto& column : columns) {if (column == nullptr || column->length() == 0) {return ::arrow::IterationTraits<RecordBatchIterator>::End();}}auto table = ::arrow::Table::Make(batch_schema, std::move(columns));auto table_reader = std::make_shared<::arrow::TableBatchReader>(*table);// NB: explicitly preserve table so that table_reader doesn't outlive itreturn ::arrow::MakeFunctionIterator([table, table_reader] { return table_reader->Next(); });});*out = ::arrow::internal::make_unique<RowGroupRecordBatchReader>(::arrow::MakeFlattenIterator(std::move(batches)), std::move(batch_schema));return Status::OK();
}
RecordBatchReader ReadNext
class RowGroupRecordBatchReader : public ::arrow::RecordBatchReader {public:RowGroupRecordBatchReader(::arrow::RecordBatchIterator batches,std::shared_ptr<::arrow::Schema> schema): batches_(std::move(batches)), schema_(std::move(schema)) {}~RowGroupRecordBatchReader() override {}Status ReadNext(std::shared_ptr<::arrow::RecordBatch>* out) override {return batches_.Next().Value(out);}std::shared_ptr<::arrow::Schema> schema() const override { return schema_; }private:::arrow::Iterator<std::shared_ptr<::arrow::RecordBatch>> batches_;std::shared_ptr<::arrow::Schema> schema_;
};
Leaf reader is for primitive arrays and primitive children of nested arrays
// ----------------------------------------------------------------------
// Column reader implementations// Leaf reader is for primitive arrays and primitive children of nested arrays
class LeafReader : public ColumnReaderImpl {public:LeafReader(std::shared_ptr<ReaderContext> ctx, std::shared_ptr<Field> field,std::unique_ptr<FileColumnIterator> input,::parquet::internal::LevelInfo leaf_info): ctx_(std::move(ctx)),field_(std::move(field)),input_(std::move(input)),descr_(input_->descr()) {record_reader_ = RecordReader::Make(descr_, leaf_info, ctx_->pool, field_->type()->id() == ::arrow::Type::DICTIONARY);NextRowGroup();}Status GetDefLevels(const int16_t** data, int64_t* length) final {*data = record_reader_->def_levels();*length = record_reader_->levels_position();return Status::OK();}Status GetRepLevels(const int16_t** data, int64_t* length) final {*data = record_reader_->rep_levels();*length = record_reader_->levels_position();return Status::OK();}bool IsOrHasRepeatedChild() const final { return false; }Status LoadBatch(int64_t records_to_read) final {BEGIN_PARQUET_CATCH_EXCEPTIONSout_ = nullptr;record_reader_->Reset();// Pre-allocation gives much better performance for flat columnsrecord_reader_->Reserve(records_to_read);while (records_to_read > 0) {if (!record_reader_->HasMoreData()) {break;}int64_t records_read = record_reader_->ReadRecords(records_to_read);records_to_read -= records_read;if (records_read == 0) {NextRowGroup();}}RETURN_NOT_OK(TransferColumnData(record_reader_.get(), field_->type(), descr_,ctx_->pool, &out_));return Status::OK();END_PARQUET_CATCH_EXCEPTIONS}::arrow::Status BuildArray(int64_t length_upper_bound,std::shared_ptr<::arrow::ChunkedArray>* out) final {*out = out_;return Status::OK();}const std::shared_ptr<Field> field() override { return field_; }private:std::shared_ptr<ChunkedArray> out_;void NextRowGroup() {std::unique_ptr<PageReader> page_reader = input_->NextChunk();record_reader_->SetPageReader(std::move(page_reader));}std::shared_ptr<ReaderContext> ctx_;std::shared_ptr<Field> field_;std::unique_ptr<FileColumnIterator> input_;const ColumnDescriptor* descr_;std::shared_ptr<RecordReader> record_reader_;
};
parallel
src/arrow/util/parallel.h:57
template <class FUNCTION>
Status OptionalParallelFor(bool use_threads, int num_tasks, FUNCTION&& func,Executor* executor = internal::GetCpuThreadPool()) {if (use_threads) {return ParallelFor(num_tasks, std::forward<FUNCTION>(func), executor);} else {for (int i = 0; i < num_tasks; ++i) {RETURN_NOT_OK(func(i));}return Status::OK();}
}
NextBatch
src/parquet/arrow/reader.cc:
Status FileReaderImpl::GetRecordBatchReader(const std::vector& row_groups,
const std::vector& column_indices,
std::unique_ptr* out
// NB: This lambda will be invoked outside the scope of this call to// `GetRecordBatchReader()`, so it must capture `readers` and `batch_schema` by value.// `this` is a non-owning pointer so we are relying on the parent FileReader outliving// this RecordBatchReader.::arrow::Iterator<RecordBatchIterator> batches = ::arrow::MakeFunctionIterator([readers, batch_schema, num_rows,this]() mutable -> ::arrow::Result<RecordBatchIterator> {::arrow::ChunkedArrayVector columns(readers.size());// don't reserve more rows than necessaryint64_t batch_size = std::min(properties().batch_size(), num_rows);num_rows -= batch_size;RETURN_NOT_OK(::arrow::internal::OptionalParallelFor(reader_properties_.use_threads(), static_cast<int>(readers.size()),[&](int i) { return readers[i]->NextBatch(batch_size, &columns[i]); }));for (const auto& column : columns) {if (column == nullptr || column->length() == 0) {return ::arrow::IterationTraits<RecordBatchIterator>::End();}}auto table = ::arrow::Table::Make(batch_schema, std::move(columns));auto table_reader = std::make_shared<::arrow::TableBatchReader>(*table);// NB: explicitly preserve table so that table_reader doesn't outlive itreturn ::arrow::MakeFunctionIterator([table, table_reader] { return table_reader->Next(); });});src/parquet/arrow/reader.cc:107
class ColumnReaderImpl : public ColumnReader {public:virtual Status GetDefLevels(const int16_t** data, int64_t* length) = 0;virtual Status GetRepLevels(const int16_t** data, int64_t* length) = 0;virtual const std::shared_ptr<Field> field() = 0;::arrow::Status NextBatch(int64_t batch_size,std::shared_ptr<::arrow::ChunkedArray>* out) final {RETURN_NOT_OK(LoadBatch(batch_size));RETURN_NOT_OK(BuildArray(batch_size, out));for (int x = 0; x < (*out)->num_chunks(); x++) {RETURN_NOT_OK((*out)->chunk(x)->Validate());}return Status::OK();}virtual ::arrow::Status LoadBatch(int64_t num_records) = 0;virtual ::arrow::Status BuildArray(int64_t length_upper_bound,std::shared_ptr<::arrow::ChunkedArray>* out) = 0;virtual bool IsOrHasRepeatedChild() const = 0;
};
LoadBatch
src/parquet/arrow/reader.cc:452
Status LoadBatch(int64_t records_to_read) final {BEGIN_PARQUET_CATCH_EXCEPTIONSout_ = nullptr;record_reader_->Reset();// Pre-allocation gives much better performance for flat columnsrecord_reader_->Reserve(records_to_read);while (records_to_read > 0) {if (!record_reader_->HasMoreData()) {break;}int64_t records_read = record_reader_->ReadRecords(records_to_read);records_to_read -= records_read;if (records_read == 0) {NextRowGroup();}}RETURN_NOT_OK(TransferColumnData(record_reader_.get(), field_->type(), descr_,ctx_->pool, &out_));return Status::OK();END_PARQUET_CATCH_EXCEPTIONS}
ReadRecords
src/parquet/column_reader.cc
int64_t ReadRecords(int64_t num_records) override {// Delimit records, then read values at the endint64_t records_read = 0;if (levels_position_ < levels_written_) {records_read += ReadRecordData(num_records);}int64_t level_batch_size = std::max(kMinLevelBatchSize, num_records);// If we are in the middle of a record, we continue until reaching the// desired number of records or the end of the current record if we've found// enough recordswhile (!at_record_start_ || records_read < num_records) {// Is there more data to read in this row group?if (!this->HasNextInternal()) {if (!at_record_start_) {// We ended the row group while inside a record that we haven't seen// the end of yet. So increment the record count for the last record in// the row group++records_read;at_record_start_ = true;}break;}/// We perform multiple batch reads until we either exhaust the row group/// or observe the desired number of recordsint64_t batch_size = std::min(level_batch_size, available_values_current_page());// No more data in columnif (batch_size == 0) {break;}if (this->max_def_level_ > 0) {ReserveLevels(batch_size);int16_t* def_levels = this->def_levels() + levels_written_;int16_t* rep_levels = this->rep_levels() + levels_written_;// Not present for non-repeated fieldsint64_t levels_read = 0;if (this->max_rep_level_ > 0) {levels_read = this->ReadDefinitionLevels(batch_size, def_levels);if (this->ReadRepetitionLevels(batch_size, rep_levels) != levels_read) {throw ParquetException("Number of decoded rep / def levels did not match");}} else if (this->max_def_level_ > 0) {levels_read = this->ReadDefinitionLevels(batch_size, def_levels);}// Exhausted column chunkif (levels_read == 0) {break;}levels_written_ += levels_read;records_read += ReadRecordData(num_records - records_read);} else {// No repetition or definition levelsbatch_size = std::min(num_records - records_read, batch_size);records_read += ReadRecordData(batch_size);}}return records_read;}
ReadRecordData
// Return number of logical records readint64_t ReadRecordData(int64_t num_records) {// Conservative upper boundconst int64_t possible_num_values =std::max(num_records, levels_written_ - levels_position_);ReserveValues(possible_num_values);......if (leaf_info_.HasNullableValues()) {ValidityBitmapInputOutput validity_io;validity_io.values_read_upper_bound = levels_position_ - start_levels_position;validity_io.valid_bits = valid_bits_->mutable_data();validity_io.valid_bits_offset = values_written_;DefLevelsToBitmap(def_levels() + start_levels_position,levels_position_ - start_levels_position, leaf_info_,&validity_io);values_to_read = validity_io.values_read - validity_io.null_count;null_count = validity_io.null_count;DCHECK_GE(values_to_read, 0);ReadValuesSpaced(validity_io.values_read, null_count);} else {DCHECK_GE(values_to_read, 0);ReadValuesDense(values_to_read);}......
}
ByteArrayChunkedRecordReader
class ByteArrayChunkedRecordReader : public TypedRecordReader<ByteArrayType>,virtual public BinaryRecordReader {public:ByteArrayChunkedRecordReader(const ColumnDescriptor* descr, LevelInfo leaf_info,::arrow::MemoryPool* pool): TypedRecordReader<ByteArrayType>(descr, leaf_info, pool) {DCHECK_EQ(descr_->physical_type(), Type::BYTE_ARRAY);accumulator_.builder.reset(new ::arrow::BinaryBuilder(pool));}::arrow::ArrayVector GetBuilderChunks() override {::arrow::ArrayVector result = accumulator_.chunks;if (result.size() == 0 || accumulator_.builder->length() > 0) {std::shared_ptr<::arrow::Array> last_chunk;PARQUET_THROW_NOT_OK(accumulator_.builder->Finish(&last_chunk));result.push_back(std::move(last_chunk));}accumulator_.chunks = {};return result;}void ReadValuesDense(int64_t values_to_read) override {int64_t num_decoded = this->current_decoder_->DecodeArrowNonNull(static_cast<int>(values_to_read), &accumulator_);DCHECK_EQ(num_decoded, values_to_read);ResetValues();}void ReadValuesSpaced(int64_t values_to_read, int64_t null_count) override {int64_t num_decoded = this->current_decoder_->DecodeArrow(static_cast<int>(values_to_read), static_cast<int>(null_count),valid_bits_->mutable_data(), values_written_, &accumulator_);DCHECK_EQ(num_decoded, values_to_read - null_count);ResetValues();}private:// Helper data structure for accumulating builder chunkstypename EncodingTraits<ByteArrayType>::Accumulator accumulator_;
};
DecodeArrow
src/parquet/encoding.cc
DictByteArrayDecoderImpl::DecodeArrow
int DecodeArrow(int num_values, int null_count, const uint8_t* valid_bits,int64_t valid_bits_offset,typename EncodingTraits<ByteArrayType>::Accumulator* out) override {int result = 0;if (null_count == 0) {PARQUET_THROW_NOT_OK(DecodeArrowDenseNonNull(num_values, out, &result));} else {PARQUET_THROW_NOT_OK(DecodeArrowDense(num_values, null_count, valid_bits,valid_bits_offset, out, &result));}return result;}
DictByteArrayDecoderImpl
class DictByteArrayDecoderImpl : public DictDecoderImpl<ByteArrayType>,virtual public ByteArrayDecoder {public:using BASE = DictDecoderImpl<ByteArrayType>;using BASE::DictDecoderImpl;int DecodeArrow(int num_values, int null_count, const uint8_t* valid_bits,int64_t valid_bits_offset,typename EncodingTraits<ByteArrayType>::Accumulator* out) override {int result = 0;if (null_count == 0) {PARQUET_THROW_NOT_OK(DecodeArrowDenseNonNull(num_values, out, &result));} else {PARQUET_THROW_NOT_OK(DecodeArrowDense(num_values, null_count, valid_bits,valid_bits_offset, out, &result));}return result;}
Status DecodeArrowDenseNonNull(int num_values,typename EncodingTraits<ByteArrayType>::Accumulator* out,int* out_num_values) {constexpr int32_t kBufferSize = 2048;int32_t indices[kBufferSize];int values_decoded = 0;ArrowBinaryHelper helper(out);auto dict_values = reinterpret_cast<const ByteArray*>(dictionary_->data());while (values_decoded < num_values) {int32_t batch_size = std::min<int32_t>(kBufferSize, num_values - values_decoded);int num_indices = idx_decoder_.GetBatch(indices, batch_size);if (num_indices == 0) ParquetException::EofException();for (int i = 0; i < num_indices; ++i) {auto idx = indices[i];RETURN_NOT_OK(IndexInBounds(idx));const auto& val = dict_values[idx];if (ARROW_PREDICT_FALSE(!helper.CanFit(val.len))) {RETURN_NOT_OK(helper.PushChunk());}RETURN_NOT_OK(helper.Append(val.ptr, static_cast<int32_t>(val.len)));}values_decoded += num_indices;}*out_num_values = values_decoded;return Status::OK();}
decode
src/parquet/encoding.cc
std::unique_ptr<Decoder> MakeDecoder(Type::type type_num, Encoding::type encoding,const ColumnDescriptor* descr) {if (encoding == Encoding::PLAIN) {switch (type_num) {case Type::BOOLEAN:return std::unique_ptr<Decoder>(new PlainBooleanDecoder(descr));case Type::INT32:return std::unique_ptr<Decoder>(new PlainDecoder<Int32Type>(descr));case Type::INT64:return std::unique_ptr<Decoder>(new PlainDecoder<Int64Type>(descr));case Type::INT96:return std::unique_ptr<Decoder>(new PlainDecoder<Int96Type>(descr));case Type::FLOAT:return std::unique_ptr<Decoder>(new PlainDecoder<FloatType>(descr));case Type::DOUBLE:return std::unique_ptr<Decoder>(new PlainDecoder<DoubleType>(descr));case Type::BYTE_ARRAY:return std::unique_ptr<Decoder>(new PlainByteArrayDecoder(descr));case Type::FIXED_LEN_BYTE_ARRAY:return std::unique_ptr<Decoder>(new PlainFLBADecoder(descr));default:break;}} else if (encoding == Encoding::BYTE_STREAM_SPLIT) {switch (type_num) {case Type::FLOAT:return std::unique_ptr<Decoder>(new ByteStreamSplitDecoder<FloatType>(descr));case Type::DOUBLE:return std::unique_ptr<Decoder>(new ByteStreamSplitDecoder<DoubleType>(descr));default:throw ParquetException("BYTE_STREAM_SPLIT only supports FLOAT and DOUBLE");break;}} else {ParquetException::NYI("Selected encoding is not supported");}DCHECK(false) << "Should not be able to reach this code";return nullptr;
}
std::unique_ptr<Decoder> MakeDictDecoder(Type::type type_num,const ColumnDescriptor* descr,MemoryPool* pool) {switch (type_num) {case Type::BOOLEAN:ParquetException::NYI("Dictionary encoding not implemented for boolean type");case Type::INT32:return std::unique_ptr<Decoder>(new DictDecoderImpl<Int32Type>(descr, pool));case Type::INT64:return std::unique_ptr<Decoder>(new DictDecoderImpl<Int64Type>(descr, pool));case Type::INT96:return std::unique_ptr<Decoder>(new DictDecoderImpl<Int96Type>(descr, pool));case Type::FLOAT:return std::unique_ptr<Decoder>(new DictDecoderImpl<FloatType>(descr, pool));case Type::DOUBLE:return std::unique_ptr<Decoder>(new DictDecoderImpl<DoubleType>(descr, pool));case Type::BYTE_ARRAY:return std::unique_ptr<Decoder>(new DictByteArrayDecoderImpl(descr, pool));case Type::FIXED_LEN_BYTE_ARRAY:return std::unique_ptr<Decoder>(new DictDecoderImpl<FLBAType>(descr, pool));default:break;}DCHECK(false) << "Should not be able to reach this code";return nullptr;
}
Int64 read
read page
std::shared_ptr<Page> SerializedPageReader::NextPage() {// Loop here because there may be unhandled page types that we skip until// finding a page that we do know what to do withwhile (seen_num_rows_ < total_num_rows_) {uint32_t header_size = 0;uint32_t allowed_page_size = kDefaultPageHeaderSize;// Page headers can be very large because of page statistics// We try to deserialize a larger buffer progressively// until a maximum allowed header limitwhile (true) {PARQUET_ASSIGN_OR_THROW(auto view, stream_->Peek(allowed_page_size));if (view.size() == 0) {return std::shared_ptr<Page>(nullptr);}// This gets used, then set by DeserializeThriftMsgheader_size = static_cast<uint32_t>(view.size());try {if (crypto_ctx_.meta_decryptor != nullptr) {UpdateDecryption(crypto_ctx_.meta_decryptor, encryption::kDictionaryPageHeader,data_page_header_aad_);}DeserializeThriftMsg(reinterpret_cast<const uint8_t*>(view.data()), &header_size,¤t_page_header_, crypto_ctx_.meta_decryptor);break;} catch (std::exception& e) {// Failed to deserialize. Double the allowed page header size and try againstd::stringstream ss;ss << e.what();allowed_page_size *= 2;if (allowed_page_size > max_page_header_size_) {ss << "Deserializing page header failed.\n";throw ParquetException(ss.str());}}}// Advance the stream offsetPARQUET_THROW_NOT_OK(stream_->Advance(header_size));int compressed_len = current_page_header_.compressed_page_size;int uncompressed_len = current_page_header_.uncompressed_page_size;if (compressed_len < 0 || uncompressed_len < 0) {throw ParquetException("Invalid page header");}if (crypto_ctx_.data_decryptor != nullptr) {UpdateDecryption(crypto_ctx_.data_decryptor, encryption::kDictionaryPage,data_page_aad_);}// Read the compressed data page.PARQUET_ASSIGN_OR_THROW(auto page_buffer, stream_->Read(compressed_len));if (page_buffer->size() != compressed_len) {std::stringstream ss;ss << "Page was smaller (" << page_buffer->size() << ") than expected ("<< compressed_len << ")";ParquetException::EofException(ss.str());}// Decrypt it if we need toif (crypto_ctx_.data_decryptor != nullptr) {PARQUET_THROW_NOT_OK(decryption_buffer_->Resize(compressed_len - crypto_ctx_.data_decryptor->CiphertextSizeDelta(), false));compressed_len = crypto_ctx_.data_decryptor->Decrypt(page_buffer->data(), compressed_len, decryption_buffer_->mutable_data());page_buffer = decryption_buffer_;}const PageType::type page_type = LoadEnumSafe(¤t_page_header_.type);if (page_type == PageType::DICTIONARY_PAGE) {crypto_ctx_.start_decrypt_with_dictionary_page = false;const format::DictionaryPageHeader& dict_header =current_page_header_.dictionary_page_header;bool is_sorted = dict_header.__isset.is_sorted ? dict_header.is_sorted : false;if (dict_header.num_values < 0) {throw ParquetException("Invalid page header (negative number of values)");}// Uncompress if neededpage_buffer =DecompressIfNeeded(std::move(page_buffer), compressed_len, uncompressed_len);return std::make_shared<DictionaryPage>(page_buffer, dict_header.num_values,LoadEnumSafe(&dict_header.encoding),is_sorted);} else if (page_type == PageType::DATA_PAGE) {++page_ordinal_;const format::DataPageHeader& header = current_page_header_.data_page_header;if (header.num_values < 0) {throw ParquetException("Invalid page header (negative number of values)");}EncodedStatistics page_statistics = ExtractStatsFromHeader(header);seen_num_rows_ += header.num_values;// Uncompress if neededpage_buffer =DecompressIfNeeded(std::move(page_buffer), compressed_len, uncompressed_len);return std::make_shared<DataPageV1>(page_buffer, header.num_values,LoadEnumSafe(&header.encoding),LoadEnumSafe(&header.definition_level_encoding),LoadEnumSafe(&header.repetition_level_encoding),uncompressed_len, page_statistics);} else if (page_type == PageType::DATA_PAGE_V2) {++page_ordinal_;const format::DataPageHeaderV2& header = current_page_header_.data_page_header_v2;if (header.num_values < 0) {throw ParquetException("Invalid page header (negative number of values)");}if (header.definition_levels_byte_length < 0 ||header.repetition_levels_byte_length < 0) {throw ParquetException("Invalid page header (negative levels byte length)");}bool is_compressed = header.__isset.is_compressed ? header.is_compressed : false;EncodedStatistics page_statistics = ExtractStatsFromHeader(header);seen_num_rows_ += header.num_values;// Uncompress if neededint levels_byte_len;if (AddWithOverflow(header.definition_levels_byte_length,header.repetition_levels_byte_length, &levels_byte_len)) {throw ParquetException("Levels size too large (corrupt file?)");}// DecompressIfNeeded doesn't take `is_compressed` into account as// it's page type-agnostic.if (is_compressed) {page_buffer = DecompressIfNeeded(std::move(page_buffer), compressed_len,uncompressed_len, levels_byte_len);}return std::make_shared<DataPageV2>(page_buffer, header.num_values, header.num_nulls, header.num_rows,LoadEnumSafe(&header.encoding), header.definition_levels_byte_length,header.repetition_levels_byte_length, uncompressed_len, is_compressed,page_statistics);} else {// We don't know what this page type is. We're allowed to skip non-data// pages.continue;}}return std::shared_ptr<Page>(nullptr);
}
cpp/src/arrow/io/concurrency.h
Result<std::shared_ptr<Buffer>> Read(int64_t nbytes) final {auto guard = lock_.exclusive_guard();return derived()->DoRead(nbytes);}
decode
cpp/src/parquet/column_reader.cc
TypedRecordReader
virtual void ReadValuesSpaced(int64_t values_with_nulls, int64_t null_count) {uint8_t* valid_bits = valid_bits_->mutable_data();const int64_t valid_bits_offset = values_written_;int64_t num_decoded = this->current_decoder_->DecodeSpaced(ValuesHead<T>(), static_cast<int>(values_with_nulls),static_cast<int>(null_count), valid_bits, valid_bits_offset);DCHECK_EQ(num_decoded, values_with_nulls);}
protected:template <typename T>T* ValuesHead() {return reinterpret_cast<T*>(values_->mutable_data()) + values_written_;}
cpp/src/parquet/encoding.h
/// \brief Decode the values in this data page but leave spaces for null entries.////// \param[in] buffer destination for decoded values/// \param[in] num_values size of the def_levels and buffer arrays including the number/// of null slots/// \param[in] null_count number of null slots/// \param[in] valid_bits bitmap data indicating position of valid slots/// \param[in] valid_bits_offset offset into valid_bits/// \return The number of values decoded, including nulls.virtual int DecodeSpaced(T* buffer, int num_values, int null_count,const uint8_t* valid_bits, int64_t valid_bits_offset) {if (null_count > 0) {int values_to_read = num_values - null_count;int values_read = Decode(buffer, values_to_read);if (values_read != values_to_read) {throw ParquetException("Number of values / definition_levels read did not match");}return ::arrow::util::internal::SpacedExpand<T>(buffer, num_values, null_count,valid_bits, valid_bits_offset);} else {return Decode(buffer, num_values);}}
template <typename DType>
int PlainDecoder<DType>::Decode(T* buffer, int max_values) {max_values = std::min(max_values, num_values_);int bytes_consumed = DecodePlain<T>(data_, len_, max_values, type_length_, buffer);data_ += bytes_consumed;len_ -= bytes_consumed;num_values_ -= max_values;return max_values;
}
cpp/src/parquet/encoding.cc
template <typename DType>
int PlainDecoder<DType>::Decode(T* buffer, int max_values) {max_values = std::min(max_values, num_values_);int bytes_consumed = DecodePlain<T>(data_, len_, max_values, type_length_, buffer);data_ += bytes_consumed;len_ -= bytes_consumed;num_values_ -= max_values;return max_values;
}
// Decode routine templated on C++ type rather than type enum
template <typename T>
inline int DecodePlain(const uint8_t* data, int64_t data_size, int num_values,int type_length, T* out) {int64_t bytes_to_decode = num_values * static_cast<int64_t>(sizeof(T));if (bytes_to_decode > data_size || bytes_to_decode > INT_MAX) {ParquetException::EofException();}// If bytes_to_decode == 0, data could be nullif (bytes_to_decode > 0) {memcpy(out, data, bytes_to_decode);}return static_cast<int>(bytes_to_decode);
}
dict decoder
cpp/src/parquet/column_reader.cc
Only one dictionary page in columnChunk
void ConfigureDictionary(const DictionaryPage* page) {int encoding = static_cast<int>(page->encoding());if (page->encoding() == Encoding::PLAIN_DICTIONARY ||page->encoding() == Encoding::PLAIN) {encoding = static_cast<int>(Encoding::RLE_DICTIONARY);}auto it = decoders_.find(encoding);if (it != decoders_.end()) {throw ParquetException("Column cannot have more than one dictionary.");}if (page->encoding() == Encoding::PLAIN_DICTIONARY ||page->encoding() == Encoding::PLAIN) {auto dictionary = MakeTypedDecoder<DType>(Encoding::PLAIN, descr_);dictionary->SetData(page->num_values(), page->data(), page->size());// The dictionary is fully decoded during DictionaryDecoder::Init, so the// DictionaryPage buffer is no longer required after this step//// TODO(wesm): investigate whether this all-or-nothing decoding of the// dictionary makes sense and whether performance can be improvedstd::unique_ptr<DictDecoder<DType>> decoder = MakeDictDecoder<DType>(descr_, pool_);decoder->SetDict(dictionary.get());decoders_[encoding] =std::unique_ptr<DecoderType>(dynamic_cast<DecoderType*>(decoder.release()));} else {ParquetException::NYI("only plain dictionary encoding has been implemented");}new_dictionary_ = true;current_decoder_ = decoders_[encoding].get();DCHECK(current_decoder_);}
Page code
cpp/src/generated/parquet_types.h
PageHeader
class PageHeader : public virtual ::apache::thrift::TBase {public:PageType::type type;int32_t uncompressed_page_size;int32_t compressed_page_size;int32_t crc;DataPageHeader data_page_header;IndexPageHeader index_page_header;DictionaryPageHeader dictionary_page_header;DataPageHeaderV2 data_page_header_v2;_PageHeader__isset __isset;};
DictionaryPageHeader
class DictionaryPageHeader : public virtual ::apache::thrift::TBase {public:int32_t num_values;Encoding::type encoding;bool is_sorted;_DictionaryPageHeader__isset __isset;
};
DataPageHeader
class DataPageHeader : public virtual ::apache::thrift::TBase {public:virtual ~DataPageHeader() noexcept;int32_t num_values;Encoding::type encoding;Encoding::type definition_level_encoding;Encoding::type repetition_level_encoding;Statistics statistics;_DataPageHeader__isset __isset;}