在做数据分析的时候,相对于传统关系型数据库,我们更倾向于计算列之间的关系。在使用传统关系型数据库时,基于此的设计,我们会扫描很多我们并不关心的列,这导致了查询效率的低下,大部分数据库 io 比较低效。因此目前出现了列式存储。Apache Parquet 是一个列式存储的文件格式。从这里入手,提升对列存的理解。当我还没看的时候,我还是很疑惑的,跟大家一样,向 hdfs 还是 lsmt 的设计,为了提升写入性能,都是使用 append 进行操作,而 append 如何将行式的数据转换成列式的数据呢?
Parquet
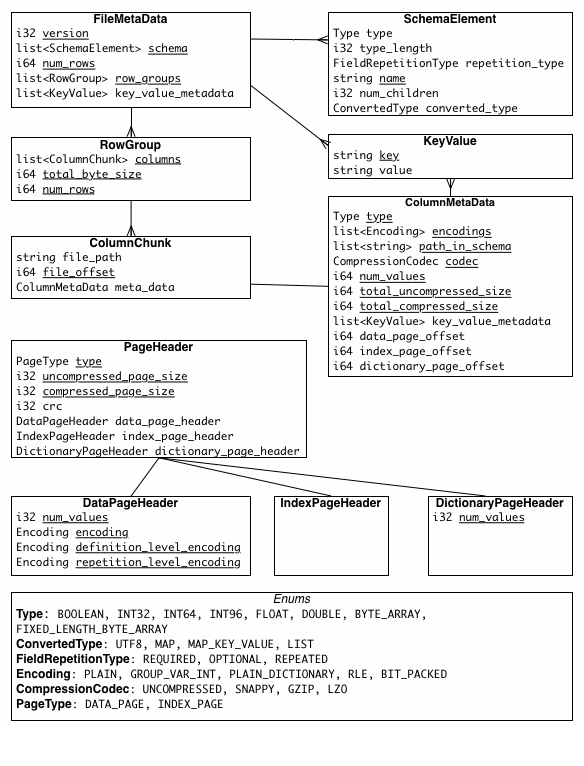
在深入 parquet 之前,我们需要先了解一下后面需要学习的术语。
术语
Block
Block(hdfs block):这是指 hdfs 的一个 block,parquet 运行在 hadoop 生态之中,文件的格式需要很好的与这些特征契合起来。
因为我之前也不知道这是什么,所以我们先来学习一下 Block 是啥。
Block 是 hdfs 中的最小的存储单元,使得其能将大文件切分为多个小文件,实现大文件的存储。并可以对多个小文件做合适的 replication,实现错误容忍(精髓)以及HA。
例如我们现在有一个文件一共是 518 MB,而设置的 hdfs block size 是 128 MB,那么它会由 5 个 block(128MB + 128MB + 128MB + 128MB + 6MB)来组成。所以我们处理数据的时候需要考虑同一行数据被写在两个不同的 block 上的情况,这里就不展开了(hdfs 细节还不是很清楚)。
File
一个 hdfs 文件,必定有 metadata。并不必须要数据。
Row Group
将我们的数据水平上的一个逻辑分区,按 mysql 来理解就是一些数据行,这些行组成一个 row group。这个 group 中包含数据集中每一列的 chunk(Column Chunk)。
Column Chunk
特定列的一大块数据。它存在于特定的一个 row group 中,并在物理上认为是连续的。
Page (column chunk 中)
column chunk 被划分为 pages。一个 page 认为是最小不可分割单元(就压缩和编码而言)。会有很多种 page type 在一个 column chunk 中交错存储。
一个文件会由一个或者多个 row group 组成,每个 row group 对其中一列只会存在一个 column chunk。column chunk 中含有多个 pages。
细节
基于以上的一些认知后,我们可以开始 Parquet 的细节描述了。
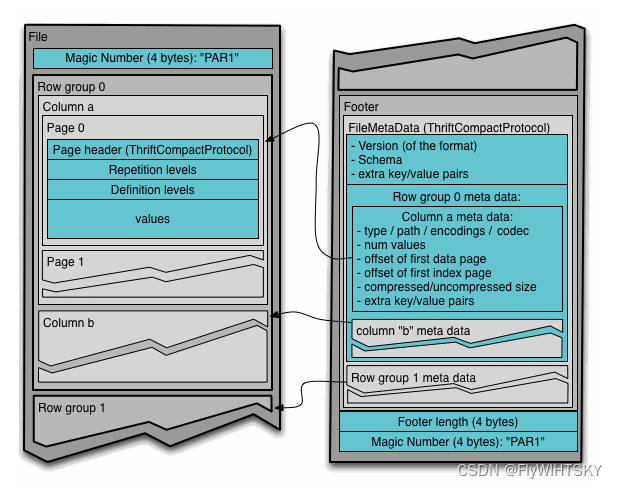
4-byte magic number "PAR1"
...
...
...
...
File Metadata
4-byte length in bytes of file metadata
4-byte magic number "PAR1"
上面这是从官网上摘抄下来的例子,一共有 M 个 row group,数据集中一共有 N 列。每个 row group 之后有一项 column 的 metadata。
在文件的末尾,有记录上 File Metadata,这个 file metada 中记录着每个 column metadata 的位置。通过这个信息,可以提取出关心的列。
这里附上两个图,都来自 Apache Parquet 官网的 document 里。就比较清晰数据结构了。

数据结构

深入
以上的讲解都是概念性的,有点难理解,我一开始也没理解,到底什么是列存。
接下来我们从实际的例子中来解密 parquet。
parquet-cpp 原先是有自己的项目,后来迁移至 arrow 中了。我们用 arrow 的代码来学习过程。
代码使用的 commit 是 c29462c9
写入
// source code: https://github.com/apache/arrow/blob/master/cpp/e