行存VS列存
广义的数据分析系统大致分为可以分为计算层、数据格式层和存储层。
计算层主要负责数据查询的介入和各种逻辑计算,如:MR、Spark、Flink。
存储层承载数据持久化存储,以文件语义或类似文件语义(对象存储)对接计算层。
数据格式层:定义了存储层文件的组织格式,计算层通过格式层来读写文件。严格来说并不算一个独立的层级,而是计算层上的一个Lib

行存将相同行数据连续存储,因此具有更高的整行数据读取效率,增删某行数据只需顺序IO读写即可,对于频繁的数据行增删操作更加友好。因此被广泛用在Mysql,Oracle等OLTP数据库中。
列存相较于行存的优势在与更好的压缩编码效率,以及读取整列更高效率,因此被广泛应用于数据湖、Clickhouse等OLAP数据库中。
Parquet原理解析
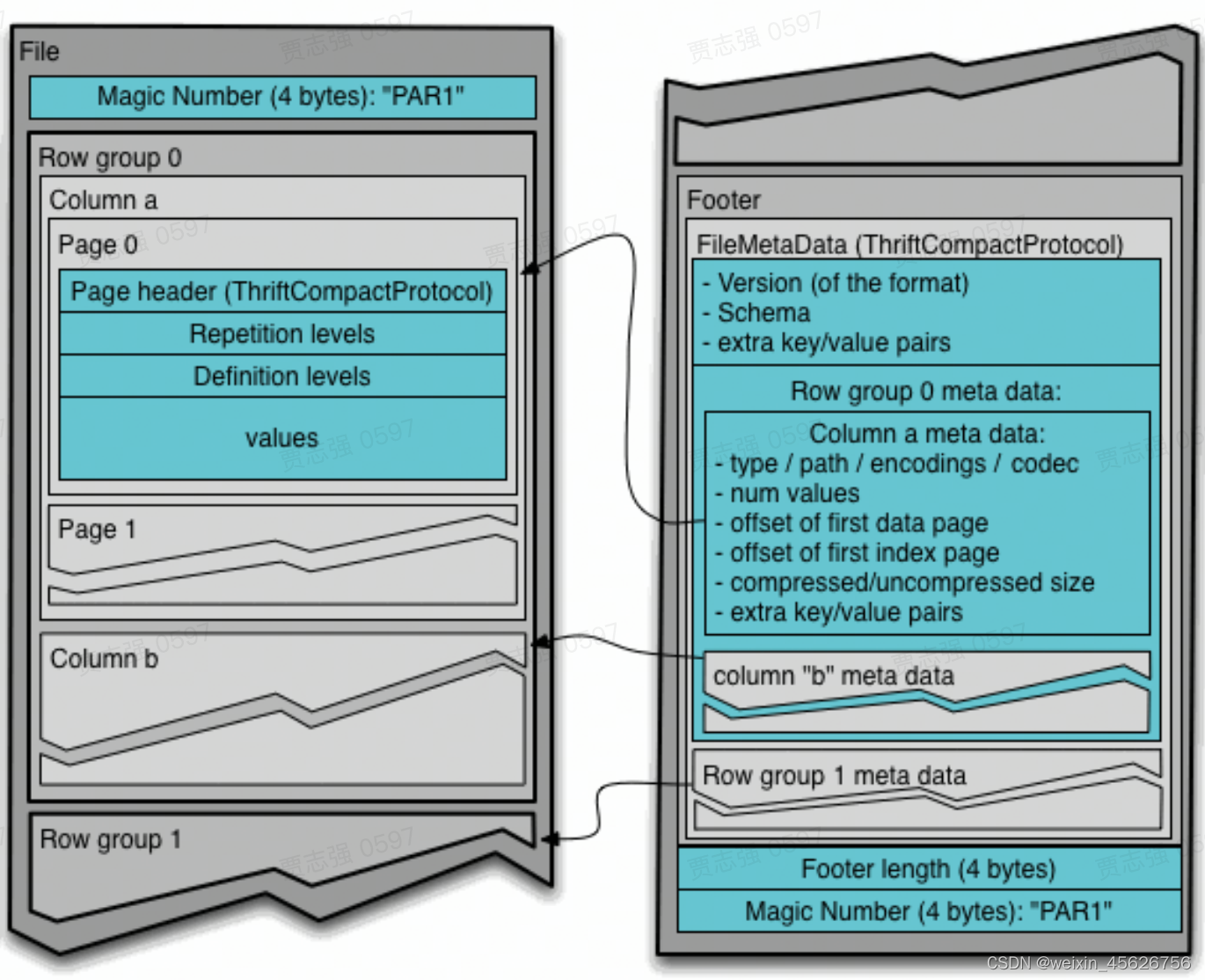
Parquet文件组织形式
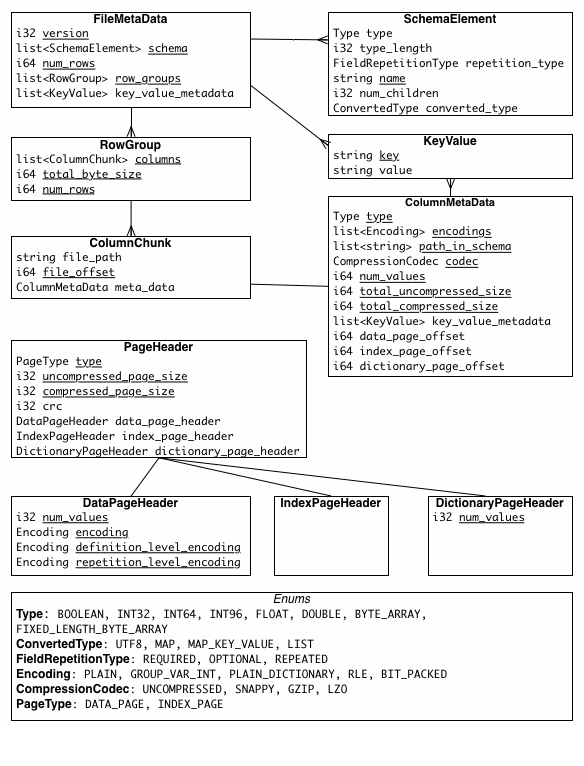
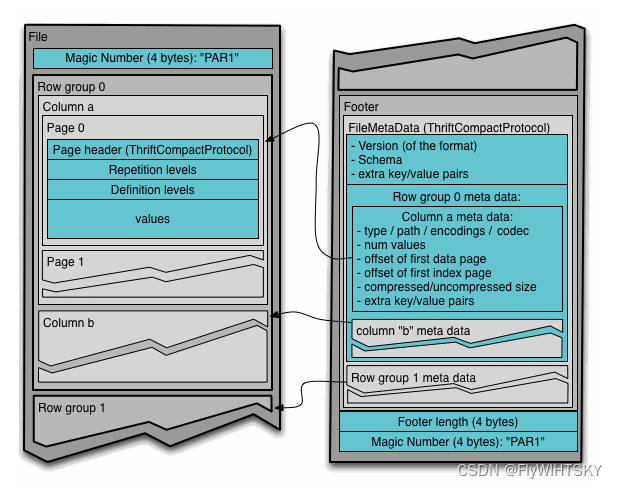
Parquet是列存储格式,Parquet文件内部按照行列划分后,将相同列的数据存储在一起。parquet文件内部划分为一下几个单元:
RowGroup:首先将数据按一定数量或固定行数划分为多个RowGroup
ColumnChunk:在同一个RowGroup中按照不同的列划分为不同的ColumnChunk
Page:一个ColumnChunk中按照一定大小,一般建议8kb,划分为多个page,每个page作为数据压缩和编码的基本单位。page内部根据存储内容分为:DataPage(存储编码后的数据)、DictionaryPage(对于字典编码,DictionaryPage存储index和数据的映射关系)、IndexPage(MinMaxIndex、BloomFilter)
Footer保存文件元数据:保存了文件的Schema、Config和Metadatea(RowGroup Meta和Column Meta)。可以根据文件Footer中记录的不同RowGroup中不同ColumnChunk的date page和index page的offset快速定位到数据文件。
Parquet编码格式
- Plain 直接存储原始数据,将数据序列化后直接存储,不进行特殊处理。
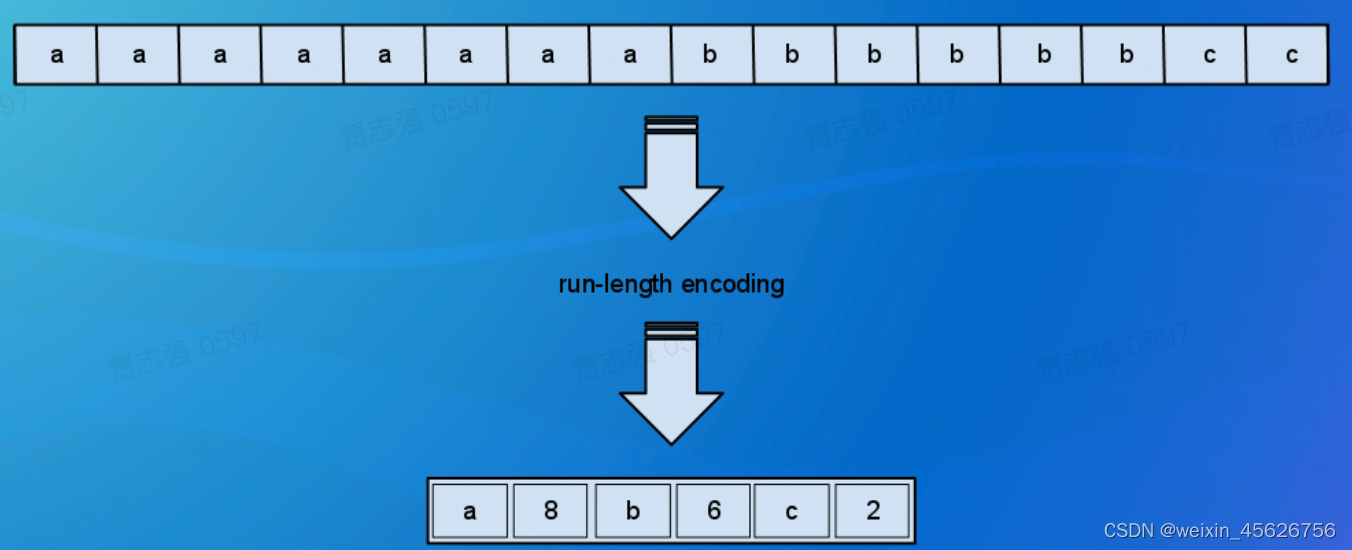
- Run Length Encoding(RLE):适用于基数不大,重复值较多的场景。如Boolean、枚举等,相较于Plain节省更多存储空间。
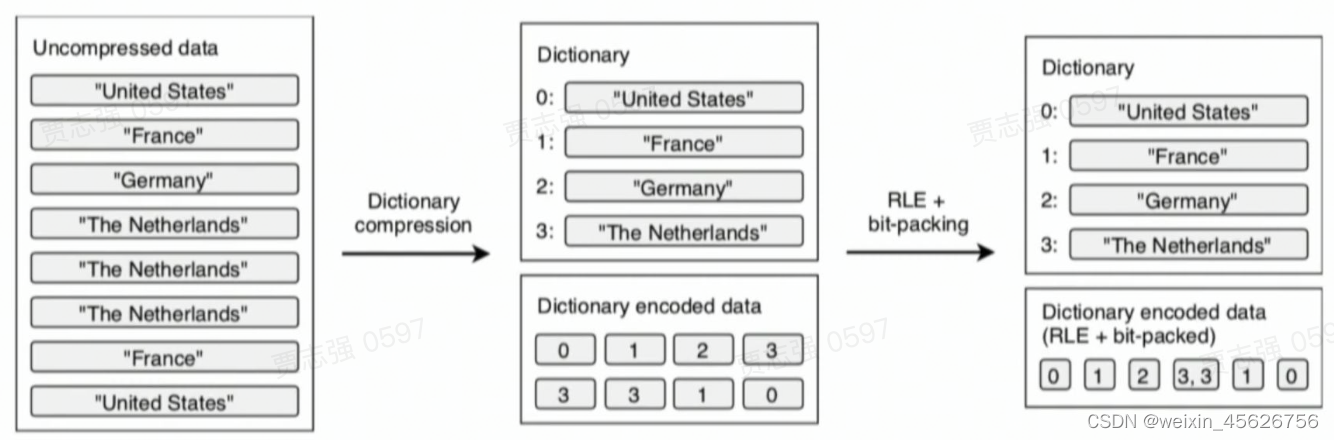
- 字典编码 Dictionary Encoding:基于基数不大的场景构建字典表,写入Dictionary Page,把数据用Index代替,然后用RLE编码。
Parquet索引
相较于OLTP数据库的索引,parquet的索引机制相对简陋。
- Min-Max Index:记录Page内部Column的Min_Value和Max_Value
- Column Index:在Footer的Column Metadata中记录了每个ColumnChunk的全部Page的Min-Max Value
- Offset Index:在Footer中记录Page在文件中的offset和Row Range
- Bloom Index:对于基数较大,或者非排序的过滤场景,Min_Max很难发挥作用,BloomFilter可以加速过滤匹配。开启Parquet文件会在每个ColumnChunk的头部保存Bloom Filter数据,并在Footer的ColumnMetaData记录BloomFilter的page offset。
过滤下推
parquet-mr实现的高效过滤机制,引擎侧传入Filter Expression,parquet-mr转换成具体的Column匹配条件,然后查询Footer的ColumnIndex定位到具体的行号,并利用Index过滤一些不匹配的ColumnChunk,将有效数据返回给引擎侧,减少IO量。