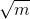文章目录
- 1 Apriori算法简介
- 2 关联分析简介
- 2.1 关联分析
- 2.2 频繁项集的度量标准
- 2.2.1 支持度
- 2.2.2 置信度
- 2.3 关联规则
- 3 Apriori算法原理
- 3.1 先验原理
- 3.2 Apriori 算法流程
- 4 实验
- 4.1 使用Apriori算法来发现频繁项集
- 4.1.1. 生成候选项集
- 4.1.2 完整的Apriori算法
- 参考资料
注:转载请标明原文出处链接:https://xiongyiming.blog.csdn.net/article/details/97645929
1 Apriori算法简介
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支持度的项集称为频繁项集,简称频集。
经典的关联规则数据挖掘算法Apriori 算法广泛应用于各种领域,通过对数据的关联性进行了分析和挖掘,挖掘出的这些信息在决策制定过程中具有重要的参考价值。
Apriori算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。而且算法已经被广泛的应用到商业、网络安全等各个领域。例如Apriori算法广泛应用于商业中,应用于消费市场价格分析中,它能够很快的求出各种产品之间的价格关系和它们之间的影响。Apriori算法应用于网络安全领域,比如网络入侵检测技术中。
(以上均来自百度百科)
2 关联分析简介
大型超市有海量的交易数据,作为精明的商家肯定不会放弃对这些海量数据的应用,他们希望通过对这些交易数据的分析,了解顾客的购买行为。我们可以通过聚类算法寻找购买相似物品的人群,从而为特定人群提供更具个性化的服务。但是对于超市来讲,更有价值的是找出商品之间的隐藏关联,从而可以用于商品定价、市场促销、存货管理等一系列环节,来增加营业收入。
那如何从这种海量而又繁杂的交易数据中找出商品之间的关联呢?
当然,你可以使用穷举法,但是这是一种十分耗时且计算代价高的笨方法,所以需要用更智能的方法在合理的时间范围内找到答案。
因此,关联分析就此诞生了
2.1 关联分析
关联分析(association analysis)是一种在大规模数据集中寻找有趣关系的非监督学习算法。这种关系可以有两种形式:频繁项集或者关联规则。频繁项集(frequent item sets)是经常出现在一块的物品的集合,关联规则(association rules)暗示两种物品之间可能存在很强的关系。
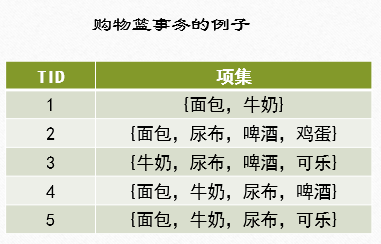
在关联分析中的一个典型例子就是购物篮分析,下表是某超市购物篮的信息列表:

在这里需要明确几个专有名词定义:
事务:每一条交易称为一个事务。例如,在这个例子中包含了5个事务。
项:交易的每一个物品称为一个项,例如豆奶、尿布等。
项集:包含零个或者多个项的集合叫做项集,例如 {豆奶,莴苣}。
k k k-项集:包含 k k k个项的项集叫做 k k k-项集。例如 {豆奶} 叫做1-项集,{豆奶,尿布,啤酒} 叫做3-项集。
"啤酒与尿布的故事"
关联分析中最有名的例子是"啤酒与尿布"。“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,沃尔玛的超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中,这种独特的销售现象引起了管理人员的注意,经过后续调查发现,这种现象出现在年轻的父亲身上。在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。如果这个年轻的父亲在卖场只能买到两件商品之一,则他很有可能会放弃购物而到另一家商店,直到可以一次同时买到啤酒与尿布为止。沃尔玛发现了这一独特的现象,开始在卖场尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以同时找到这两件商品,并很快地完成购物;而沃尔玛超市也可以让这些客户一次购买两件商品、而不是一件,从而获得了很好的商品销售收入,这就是“啤酒与尿布”故事的由来。
2.2 频繁项集的度量标准
频繁项集是经常出现在一块的物品的集合,那么问题就来了:
(1) 当数据量非常大的时候,我们无法凭肉眼找出经常出现在一起的物品,这就催生了关联规则挖掘算法,比如 Apriori、PrefixSpan、CBA 等。
(2) 缺乏一个频繁项集的衡量标准。比如10条记录,里面A和B同时出现了三次,那么我们能不能说A和B一起构成频繁项集呢?因此我们需要一个评估频繁项集的标准。
常用的频繁项集的度量标准最重要的是支持度和置信度。
2.2.1 支持度
支持度就是几个关联的数据在数据集中出现的次数占总数据集的比重。或者说几个数据关联出现的概率。如果我们有两个想分析关联性的数据X和Y,则对应的支持度为:
(1) s u p p o r t ( X , Y ) = P ( X Y ) = N u m ( X Y ) N u m ( A l l ) {\rm{support}}(X,Y) = P(XY) = {{Nu{m_{(XY)}}} \over {Nu{m_{(All)}}}} \tag{1} support(X,Y)=P(XY)=Num(All)Num(XY)(1)
以此类推,如果我们有三个想分析关联性的数据X,Y和Z,则对应的支持度为:
(2) s u p p o r t ( X , Y , Z ) = P ( X Y Z ) = N u m ( X Y Z ) N u m ( A l l ) {\rm{support}}(X,Y,Z) = P(XYZ) = {{Nu{m_{(XYZ)}}} \over {Nu{m_{(All)}}}} \tag{2} support(X,Y,Z)=P(XYZ)=Num(All)Num(XYZ)(2)
一般来说,支持度高的数据不一定构成频繁项集,但是支持度太低的数据肯定不构成频繁项集。 另外,支持度是针对项集来说的,因此,可以定义一个最小支持度,而只保留满足最小支持度的项集,起到一个项集过滤的作用。
2.2.2 置信度
置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。如果我们有两个想分析关联性的数据X和Y,X对Y的置信度为
(3) c o n f i d e n c e ( X → Y ) = P ( X ∣ Y ) = P ( X Y ) P ( Y ) {\rm{confidence}}(X \to Y) = P(X\left| Y \right.) = {{P(XY)} \over {P(Y)}} \tag{3} confidence(X→Y)=P(X∣Y)=P(Y)P(XY)(3)也可以以此类推到多个数据的关联置信度,比如对于三个数据X,Y,Z,则X对于Y和Z的置信度为:
(4) c o n f i d e n c e ( X → Y Z ) = P ( X ∣ Y Z ) = P ( X Y Z ) P ( Y Z ) {\rm{confidence}}(X \to YZ) = P(X\left| {YZ} \right.) = {{P(XYZ)} \over {P(YZ)}} \tag{4} confidence(X→YZ)=P(X∣YZ)=P(YZ)P(XYZ)(4)
支持度是一种重要度量,因为支持度很低的规则可能只是偶然出现。从商务角度来看,低支持度的规则多半也是无意义的,因为对顾客很少同时购买的商品进行促销可能并无益处。因此,支持度通常用来删去那些无意义的规则。此外,支持度还具有一种期望的性质,可以用于关联规则的有效发现。
置信度度量通过规则进行推理具有可靠性。对于给定的规则X→Y,置信度越高,Y在包含X的事务中出现的可能性就越大。置信度也可以估计Y在给定X下的条件概率。
同时,应当小心解释关联分析的结果。由关联规则作出的推论并不必然蕴涵因果关系。它只表示规则前件和后件同时出现的一种概率。
2.3 关联规则
挖掘关联规则的一种原始方法是:计算每个可能规则的支持度和置信度。但是这种方法的代价很高,令人望而却步,因为可以从数据集提取的规则的数目达指数级。更具体地说,从包含 d d d个项的数据集提取的可能规则的总数为:
(5) R = 3 d − 2 d − 1 + 1 R = {3^d} - {2^{d - 1}} + 1 \tag{5} R=3d−2d−1+1(5)对于我们前面购物篮例子中一共有6中商品,提取的可能规则数达到602种,复杂度极高。其中大部分的计算是无用的开销。为了避免进行不必要的计算,事先对规则剪枝, 因此,大多数关联规则挖掘算法通常采用的一种策略是,将关联规则挖掘任务分解为如下两个主要的子任务:
(1) 频繁项集产生
频繁项集产生目标是发现满足最小支持度阈值的所有项集,这些项集称作频繁项集(frequent itemset).
通常,频繁项集产生所需的计算开销远大于产生规则所需的计算开销。那有没有办法可以减少这种无用的计算呢?下面这两种方法可以降低产生频繁项集的计算复杂度
(a) 减少候选项集的数目M。
(b) 减少比较次数。替代将每个候选项集与每个事务相匹配,可以使用更高级的数据结构,或者存储候选项集或者压缩数据集,来减少比较次数。
这些策略都是Apriori算法基本思想。
(2) 规则的产生
规则的产生目标是从上一步发现的频繁项集中提取所有高置信度的规则,这些规则称作强规则(strong rule)。
3 Apriori算法原理
3.1 先验原理
先验原理:如果一个项集是频繁的,则它的所有子集一定也是频繁的。
例子
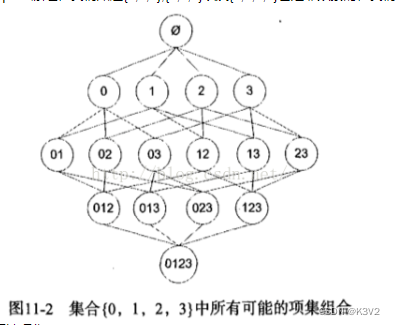
假设我们在经营一家商品种类并不多的杂货店,我们对那些经常在一起被购买的商品非常感兴趣。我们只有4种商品:商品0,商品1,商品2和商品3。那么所有可能被一起购买的商品组合都有哪些?这些商品组合可能只有一种商品,比如商品0,也可能包括两种、三种或者所有四种商品。我们并不关心某人买了两件商品0以及四件商品2的情况,我们只关心他购买了一种或多种商品。
下图显示了物品之间所有可能的组合。为了让该图更容易懂,图中使用物品的编号0来取代物品0本身。另外,图中从上往下的第一个集合是Ф,表示空集或不包含任何物品的集合。物品集合之间的连线表明两个或者更多集合可以组合形成一个更大的集合。
根据先验原理,假如 {1,2,3} 是频繁项集,那么它的所有子集(下图中橙色项集)一定也是频繁的。

这个先验原理直观上并没有什么帮助,但是反过来看就有用了。
如果一个项集是非频繁项集,那么它的所有超集也是非频繁的。
如下图所示,已知阴影项集 {2,3} 是非频繁的。利用这个知识,我们就知道项集{0,2,3} ,{1,2,3}以及{0,1,2,3}也是非频繁的。这也就是说,一旦计算出了{2,3}的支持度,知道它是非频繁的之后,就不需要再计算{0,2,3}、{1,2,3}和0,1,2,3}的支持度,因为我们知道这些集合不会满足我们的要求。使用该原理就可以避免项集数目的指数增长,从而在合理时间内计算出频繁项集。

3.2 Apriori 算法流程
关联分析的目的包括两项:发现频繁项集和发现关联规则。首先需要找到频繁项集,然后才能获得关联规则。Apriori 算法过程如下图所示:

其中:
C1,C2,…,Ck分别表示1-项集,2-项集,…,k-项集;
L1,L2,…,Lk分别表示有k个数据项的频繁项集。
Scan表示数据集扫描函数。该函数起到的作用是支持度过滤,满足最小支持度的项集才留下,不满足最小支持度的项集直接舍掉。
如上图所示,Apriori 算法的两个输入参数分别是最小支持度和数据集。首先会生成所有单个物品的项集合列表。接着对扫描交易记录来查看哪些项集满足最小支持度要求,哪些不满足最小支持度的集合将被去掉。然后对剩下的集合进行组合来生成包含两个元素的项集。接下来,再重新扫描交易记录,去掉不满足最小支持度的项集。该过程重复进行直到所有项集都被去掉。
下面通过实验来了解Apriori 算法。
4 实验
4.1 使用Apriori算法来发现频繁项集
4.1.1. 生成候选项集
数据集扫描的伪代码如下:
对数据集中的每条交易记录transaction
对每个候选项集can:
检查can是否是transaction的子集:
如果是,增加can的计数
对每个候选项集:
如果支持度不低于最小值,则保留该项集
返回所有频繁项集列表
所用到的函数:
(1) 创建用于简单数据集
(2) 构建第一个候选集合C1
由于算法一开始是从输入数据集中提取候选项集列表,所以这里需要一个特殊的函数来处理——frozenset类型。frozenset是指被“冰冻”的集合,也就是用户不能修改他们。这里必须要用frozenset而非set类型
(3) 生成满足最小支持度的频繁项集L1
C1是大小为1的所有候选项集的集合,Apriori算法首先构建集合C1,然后扫描数据集来判断这些只有一个元素的项集是否满足最小支持度的要求。那些满足最低要求的项集构成集合L1。
代码示例
def loadDataSet():dataSet = [[1,3,4],[2,3,5],[1,2,3,5],[2,5]]return dataSet"""
函数功能:生成第一个候选集合C1
参数说明:
dataSet:原始数据集
返回:
frozenset形式的候选集合C1
"""
def createC1(dataSet):C1 = []for transaction in dataSet:#print(transaction)for item in transaction:#print(item)if not {item} in C1:#print({item})C1.append({item})#print(C1)C1.sort()return list(map(frozenset, C1))"""
函数功能:生成满足最小支持度的频繁项集L1
参数说明:
D:原始数据集Ck:候选项集
minSupport:最小支持度
返回:
retList:频繁项集
supportData:候选项集的支持度
"""
def scanD(D, Ck, minSupport):ssCnt = {}for tid in D:for can in Ck:if can.issubset(tid): #判断can是否是tid的子集,返回的是布尔型数据if can not in ssCnt.keys( ):ssCnt[can]=1else:ssCnt[can] += 1numItems = float(len(D))retList = []supportData = {} #候选集项Ck的支持度字典(key:候选项, value:支持度)for key in ssCnt:support = ssCnt[key]/numItemsif support >= minSupport:retList.insert(0,key)supportData[key] = supportreturn retList, supportDatadataSet=loadDataSet() #读取数据
C1=createC1(dataSet) #生成第一个候选集合C1
print("C1=",C1)L1, supportData = scanD(dataSet, C1, 0.5) # 生成满足最小支持度的频繁项集L1
print("L1=",L1)
print("supportData=",supportData)
运行结果

从上面运行结果中可以看出,设定最小支持度为0.5时,因为frozenset({4})支持度为0.25 < 0.5,所以就被舍弃了,没有放入到L1中。
下面将介绍完整的Apriori算法。
4.1.2 完整的Apriori算法
Apriori算法的伪代码如下:
当集合中项的个数大于0时:
构建一个 k k k-项集组成的列表
检查数据确保每个项集都是频繁的
保留频繁项集并构建( k k k+1)-项集组成列表
代码示例
def loadDataSet():dataSet = [[1,3,4],[2,3,5],[1,2,3,5],[2,5]]return dataSet"""
函数功能:生成第一个候选集合C1
参数说明:
dataSet:原始数据集
返回:
frozenset形式的候选集合C1
"""
def createC1(dataSet):C1 = []for transaction in dataSet:#print(transaction)for item in transaction:#print(item)if not {item} in C1:#print({item})C1.append({item})#print(C1)C1.sort()return list(map(frozenset, C1))"""
函数功能:生成满足最小支持度的频繁项集L1
参数说明:
D:原始数据集Ck:候选项集
minSupport:最小支持度
返回:
retList:频繁项集
supportData:候选项集的支持度
"""
def scanD(D, Ck, minSupport):ssCnt = {}for tid in D:for can in Ck:if can.issubset(tid): #判断can是否是tid的子集,返回的是布尔型数据if can not in ssCnt.keys( ):ssCnt[can]=1else:ssCnt[can] += 1numItems = float(len(D))retList = []supportData = {} #候选集项Ck的支持度字典(key:候选项, value:支持度)for key in ssCnt:support = ssCnt[key]/numItemsif support >= minSupport:retList.insert(0,key)supportData[key] = supportreturn retList, supportData# dataSet=loadDataSet() #读取数据
# C1=createC1(dataSet) #生成第一个候选集合C1
# print("C1=",C1)
#
# L1, supportData = scanD(dataSet, C1, 0.5) # 生成满足最小支持度的频繁项集L1
# print("L1=",L1)
# print("supportData=",supportData)"""
函数功能: 输入参数为频繁项集Lk与项集元素个数k,输出为Ck.
参数说明:
输入参数
频繁项集Lk
项集元素个数k输出参数为Ck."""def aprioriGen(Lk, k): #creates CkretList = []lenLk = len(Lk)for i in range(lenLk):for j in range(i+1, lenLk):L1 = list(Lk[i])[:k-2]; L2 = list(Lk[j])[:k-2]L1.sort(); L2.sort()if L1==L2: #if first k-2 elements are equalretList.append(Lk[i] | Lk[j]) #set unionreturn retList"""
函数功能:根据数据集和支持度,返回所有的频繁项集,以及所有项集的支持度。
参数说明:
输入参数
输出参数"""
def apriori(dataSet, minSupport = 0.5):C1 = createC1(dataSet)D=dataSetL1, supportData = scanD(D, C1, minSupport)L = [L1]k = 2while (len(L[k-2]) > 0):Ck = aprioriGen(L[k-2], k)Lk, supK = scanD(D, Ck, minSupport)#scan DB to get LksupportData.update(supK)L.append(Lk)k += 1return L, supportDatadataSet=loadDataSet() #读取数据
C1=createC1(dataSet) #生成第一个候选集合C1
print("C1=",C1)L1, supportData = scanD(dataSet, C1, 0.5) # 生成满足最小支持度的频繁项集L1
print("L1=",L1)
print("supportData=",supportData)L, supportData2 = apriori(dataSet, minSupport=0.5) #使用Apriori算法
print("L=", L)
print("supportData2=",supportData2)
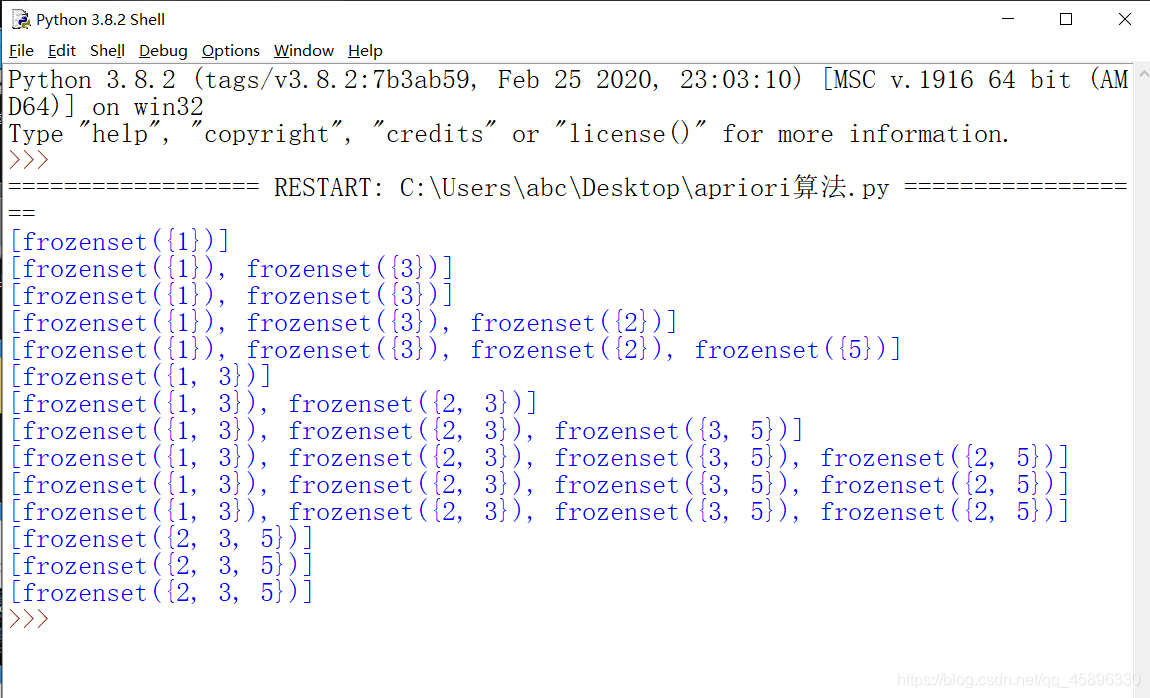
运行结果

L= [[frozenset({5}), frozenset({2}), frozenset({3}), frozenset({1})], [frozenset({2, 3}), frozenset({3, 5}), frozenset({2, 5}), frozenset({1, 3})], [frozenset({2, 3, 5})], []]supportData2= {frozenset({1}): 0.5, frozenset({3}): 0.75, frozenset({4}): 0.25, frozenset({2}): 0.75, frozenset({5}): 0.75, frozenset({1, 3}): 0.5, frozenset({2, 5}): 0.75, frozenset({3, 5}): 0.5, frozenset({2, 3}): 0.5, frozenset({1, 5}): 0.25, frozenset({1, 2}): 0.25, frozenset({2, 3, 5}): 0.5}
上面这一系列函数实现的功能可以用下图表示:

参考资料
[1] 机器学习实战. 人民邮电出版社.
[2] https://www.bilibili.com/video/av40186599