Watermark 策略简介 #
为了使用事件时间语义,Flink 应用程序需要知道事件时间戳对应的字段,意味着数据流中的每个元素都需要拥有可分配的事件时间戳。其通常通过使用 TimestampAssigner API 从元素中的某个字段去访问/提取时间戳。
时间戳的分配与 watermark 的生成是齐头并进的,其可以告诉 Flink 应用程序事件时间的进度。其可以通过指定 WatermarkGenerator 来配置 watermark 的生成方式。
使用 Flink API 时需要设置一个同时包含 TimestampAssigner 和 WatermarkGenerator 的 WatermarkStrategy。WatermarkStrategy 工具类中也提供了许多常用的 watermark 策略,并且用户也可以在某些必要场景下构建自己的 watermark 策略。WatermarkStrategy 接口如下:
public interface WatermarkStrategy<T> extends TimestampAssignerSupplier<T>, WatermarkGeneratorSupplier<T>{/*** 根据策略实例化一个可分配时间戳的 {@link TimestampAssigner}。*/@OverrideTimestampAssigner<T> createTimestampAssigner(TimestampAssignerSupplier.Context context);/*** 根据策略实例化一个 watermark 生成器。*/@OverrideWatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}
如上所述,通常情况下,你不用实现此接口,而是可以使用 WatermarkStrategy 工具类中通用的 watermark 策略,或者可以使用这个工具类将自定义的 TimestampAssigner 与 WatermarkGenerator 进行绑定。例如,你想要要使用有界无序(bounded-out-of-orderness)watermark 生成器和一个 lambda 表达式作为时间戳分配器,那么可以按照如下方式实现:
WatermarkStrategy.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20)).withTimestampAssigner((event, timestamp) -> event.f0);
其中 TimestampAssigner 的设置与否是可选的,大多数情况下,可以不用去特别指定。例如,当使用 Kafka 或 Kinesis 数据源时,你可以直接从 Kafka/Kinesis 数据源记录中获取到时间戳。
稍后我们将在自定义 WatermarkGenerator 小节学习 WatermarkGenerator 接口。
注意: 时间戳和 watermark 都是从 1970-01-01T00:00:00Z 起的 Java 纪元开始,并以毫秒为单位。
使用 Watermark 策略 #
WatermarkStrategy 可以在 Flink 应用程序中的两处使用,第一种是直接在数据源上使用,第二种是直接在非数据源的操作之后使用。
第一种方式相比会更好,因为数据源可以利用 watermark 生成逻辑中有关分片/分区(shards/partitions/splits)的信息。使用这种方式,数据源通常可以更精准地跟踪 watermark,整体 watermark 生成将更精确。直接在源上指定 WatermarkStrategy 意味着你必须使用特定数据源接口,参阅 Watermark 策略与 Kafka 连接器以了解如何使用 Kafka Connector,以及有关每个分区的 watermark 是如何生成以及工作的。
仅当无法直接在数据源上设置策略时,才应该使用第二种方式(在任意转换操作之后设置 WatermarkStrategy):
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<MyEvent> stream = env.readFile(myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,FilePathFilter.createDefaultFilter(), typeInfo);DataStream<MyEvent> withTimestampsAndWatermarks = stream.filter( event -> event.severity() == WARNING ).assignTimestampsAndWatermarks(<watermark strategy>);withTimestampsAndWatermarks.keyBy( (event) -> event.getGroup() ).window(TumblingEventTimeWindows.of(Time.seconds(10))).reduce( (a, b) -> a.add(b) ).addSink(...);
使用 WatermarkStrategy 去获取流并生成带有时间戳的元素和 watermark 的新流时,如果原始流已经具有时间戳或 watermark,则新指定的时间戳分配器将覆盖原有的时间戳和 watermark。
处理空闲数据源 #
如果数据源中的某一个分区/分片在一段时间内未发送事件数据,则意味着 WatermarkGenerator 也不会获得任何新数据去生成 watermark。我们称这类数据源为空闲输入或空闲源。在这种情况下,当某些其他分区仍然发送事件数据的时候就会出现问题。由于下游算子 watermark 的计算方式是取所有不同的上游并行数据源 watermark 的最小值,则其 watermark 将不会发生变化。
为了解决这个问题,你可以使用 WatermarkStrategy 来检测空闲输入并将其标记为空闲状态。WatermarkStrategy 为此提供了一个工具接口:
WatermarkStrategy.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20)).withIdleness(Duration.ofMinutes(1));
Watermark alignment Beta #
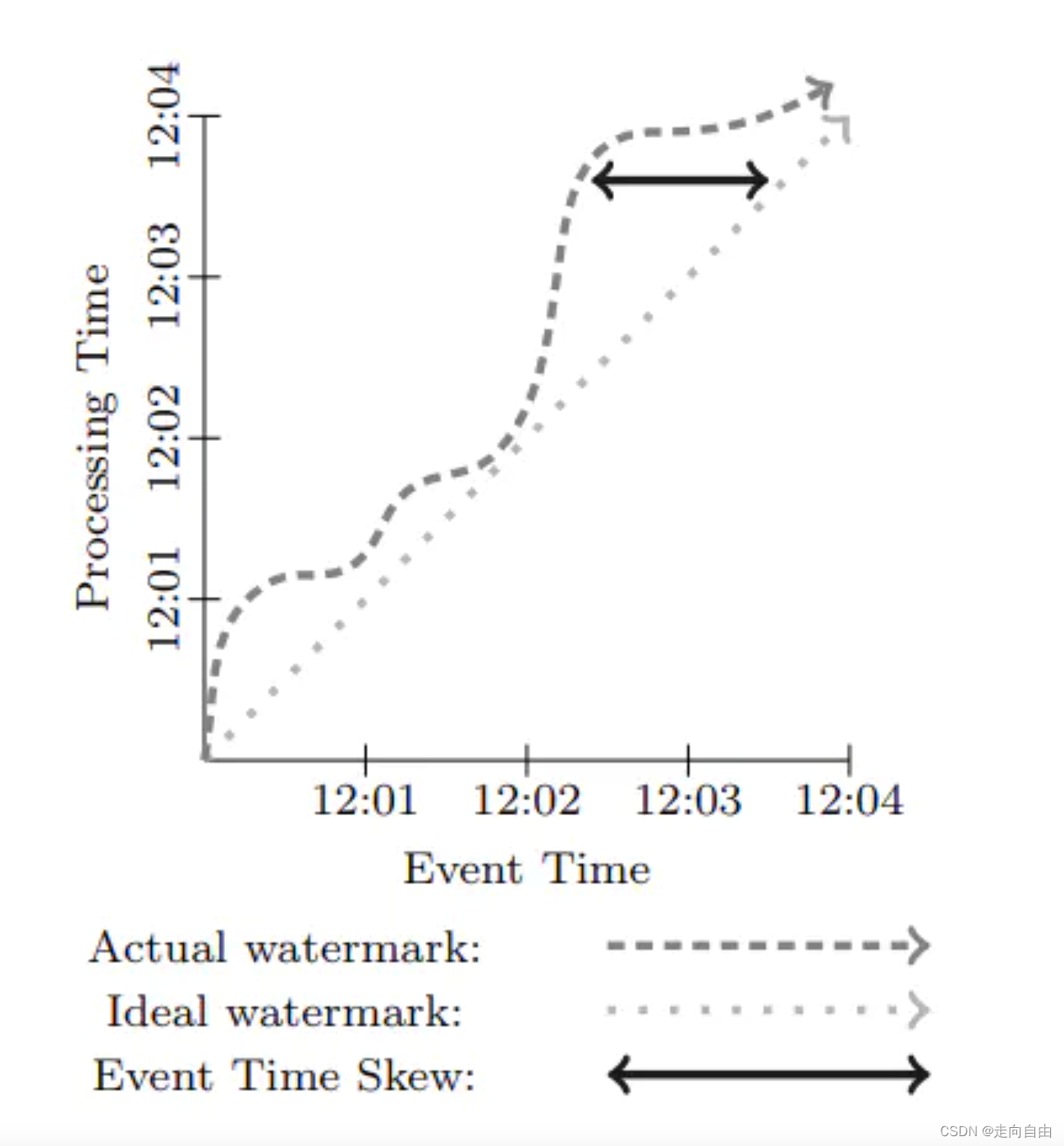
In the previous paragraph we discussed a situation when splits/partitions/shards or sources are idle and can stall increasing watermarks. On the other side of the spectrum, a split/partition/shard or source may process records very fast and in turn increase its watermark relatively faster than the others. This on its own is not a problem per se. However, for downstream operators that are using watermarks to emit some data it can actually become a problem.
In this case, contrary to idle sources, the watermark of such downstream operator (like windowed joins on aggregations) can progress. However, such operator might need to buffer excessive amount of data coming from the fast inputs, as the minimal watermark from all of its inputs is held back by the lagging input. All records emitted by the fast input will hence have to be buffered in the said downstream operator state, which can lead into uncontrollable growth of the operator’s state.
In order to address the issue, you can enable watermark alignment, which will make sure no sources/splits/shards/partitions increase their watermarks too far ahead of the rest. You can enable alignment for every source separately:
WatermarkStrategy.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20)).withWatermarkAlignment("alignment-group-1", Duration.ofSeconds(20), Duration.ofSeconds(1));
Note: You can enable watermark alignment only for FLIP-27 sources. It does not work for legacy or if applied after the source via DataStream#assignTimestampsAndWatermarks.
When enabling the alignment, you need to tell Flink, which group should the source belong. You do that by providing a label (e.g. alignment-group-1) which bind together all sources that share it. Moreover, you have to tell the maximal drift from the current minimal watermarks across all sources belonging to that group. The third parameter describes how often the current maximal watermark should be updated. The downside of frequent updates is that there will be more RPC messages travelling between TMs and the JM.
In order to achieve the alignment Flink will pause consuming from the source/task, which generated watermark that is too far into the future. In the meantime it will continue reading records from other sources/tasks which can move the combined watermark forward and that way unblock the faster one.
Note: As of 1.15, Flink supports aligning across tasks of the same source and/or different sources. It does not support aligning splits/partitions/shards in the same task.
In a case where there are e.g. two Kafka partitions that produce watermarks at different pace, that get assigned to the same task watermark might not behave as expected. Fortunately, worst case it should not perform worse than without alignment.
Given the limitation above, we suggest applying watermark alignment in two situations:
- You have two different sources (e.g. Kafka and File) that produce watermarks at different speeds
- You run your source with parallelism equal to the number of splits/shards/partitions, which results in every subtask being assigned a single unit of work.
自定义 WatermarkGenerator #
TimestampAssigner 是一个可以从事件数据中提取时间戳字段的简单函数,我们无需详细查看其实现。但是 WatermarkGenerator 的编写相对就要复杂一些了,我们将在接下来的两小节中介绍如何实现此接口。WatermarkGenerator 接口代码如下:
/*** {@code WatermarkGenerator} 可以基于事件或者周期性的生成 watermark。** <p><b>注意:</b> WatermarkGenerator 将以前互相独立的 {@code AssignerWithPunctuatedWatermarks} * 和 {@code AssignerWithPeriodicWatermarks} 一同包含了进来。*/
@Public
public interface WatermarkGenerator<T> {/*** 每来一条事件数据调用一次,可以检查或者记录事件的时间戳,或者也可以基于事件数据本身去生成 watermark。*/void onEvent(T event, long eventTimestamp, WatermarkOutput output);/*** 周期性的调用,也许会生成新的 watermark,也许不会。** <p>调用此方法生成 watermark 的间隔时间由 {@link ExecutionConfig#getAutoWatermarkInterval()} 决定。*/void onPeriodicEmit(WatermarkOutput output);
}
watermark 的生成方式本质上是有两种:周期性生成和标记生成。
周期性生成器通常通过 onEvent() 观察传入的事件数据,然后在框架调用 onPeriodicEmit() 时发出 watermark。
标记生成器将查看 onEvent() 中的事件数据,并等待检查在流中携带 watermark 的特殊标记事件或打点数据。当获取到这些事件数据时,它将立即发出 watermark。通常情况下,标记生成器不会通过 onPeriodicEmit() 发出 watermark。
接下来,我们将学习如何实现上述两类生成器。
自定义周期性 Watermark 生成器 #
周期性生成器会观察流事件数据并定期生成 watermark(其生成可能取决于流数据,或者完全基于处理时间)。
生成 watermark 的时间间隔(每 n 毫秒)可以通过 ExecutionConfig.setAutoWatermarkInterval(...) 指定。每次都会调用生成器的 onPeriodicEmit() 方法,如果返回的 watermark 非空且值大于前一个 watermark,则将发出新的 watermark。
如下是两个使用周期性 watermark 生成器的简单示例。注意:Flink 已经附带了 BoundedOutOfOrdernessWatermarks,它实现了 WatermarkGenerator,其工作原理与下面的 BoundedOutOfOrdernessGenerator 相似。可以在这里参阅如何使用它的内容。
/*** 该 watermark 生成器可以覆盖的场景是:数据源在一定程度上乱序。* 即某个最新到达的时间戳为 t 的元素将在最早到达的时间戳为 t 的元素之后最多 n 毫秒到达。*/
public class BoundedOutOfOrdernessGenerator implements WatermarkGenerator<MyEvent> {private final long maxOutOfOrderness = 3500; // 3.5 秒private long currentMaxTimestamp;@Overridepublic void onEvent(MyEvent event, long eventTimestamp, WatermarkOutput output) {currentMaxTimestamp = Math.max(currentMaxTimestamp, eventTimestamp);}@Overridepublic void onPeriodicEmit(WatermarkOutput output) {// 发出的 watermark = 当前最大时间戳 - 最大乱序时间output.emitWatermark(new Watermark(currentMaxTimestamp - maxOutOfOrderness - 1));}}/*** 该生成器生成的 watermark 滞后于处理时间固定量。它假定元素会在有限延迟后到达 Flink。*/
public class TimeLagWatermarkGenerator implements WatermarkGenerator<MyEvent> {private final long maxTimeLag = 5000; // 5 秒@Overridepublic void onEvent(MyEvent event, long eventTimestamp, WatermarkOutput output) {// 处理时间场景下不需要实现}@Overridepublic void onPeriodicEmit(WatermarkOutput output) {output.emitWatermark(new Watermark(System.currentTimeMillis() - maxTimeLag));}
}
自定义标记 Watermark 生成器 #
标记 watermark 生成器观察流事件数据并在获取到带有 watermark 信息的特殊事件元素时发出 watermark。
如下是实现标记生成器的方法,当事件带有某个指定标记时,该生成器就会发出 watermark:
public class PunctuatedAssigner implements WatermarkGenerator<MyEvent> {@Overridepublic void onEvent(MyEvent event, long eventTimestamp, WatermarkOutput output) {if (event.hasWatermarkMarker()) {output.emitWatermark(new Watermark(event.getWatermarkTimestamp()));}}@Overridepublic void onPeriodicEmit(WatermarkOutput output) {// onEvent 中已经实现}
}
注意: 可以针对每个事件去生成 watermark。但是由于每个 watermark 都会在下游做一些计算,因此过多的 watermark 会降低程序性能。
Watermark 策略与 Kafka 连接器 #
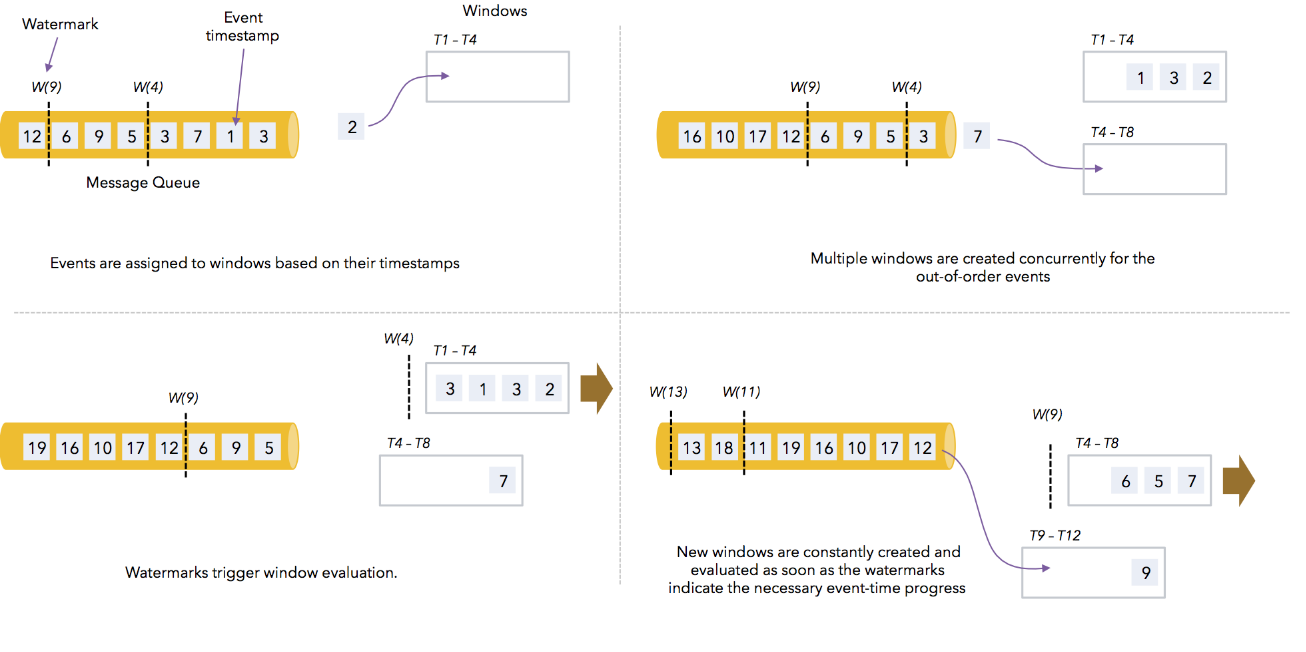
当使用 Apache Kafka 连接器作为数据源时,每个 Kafka 分区可能有一个简单的事件时间模式(递增的时间戳或有界无序)。然而,当使用 Kafka 数据源时,多个分区常常并行使用,因此交错来自各个分区的事件数据就会破坏每个分区的事件时间模式(这是 Kafka 消费客户端所固有的)。
在这种情况下,你可以使用 Flink 中可识别 Kafka 分区的 watermark 生成机制。使用此特性,将在 Kafka 消费端内部针对每个 Kafka 分区生成 watermark,并且不同分区 watermark 的合并方式与在数据流 shuffle 时的合并方式相同。
例如,如果每个 Kafka 分区中的事件时间戳严格递增,则使用单调递增时间戳分配器按分区生成的 watermark 将生成完美的全局 watermark。注意,我们在示例中未使用 TimestampAssigner,而是使用了 Kafka 记录自身的时间戳。
下图展示了如何使用单 kafka 分区 watermark 生成机制,以及在这种情况下 watermark 如何通过 dataflow 传播。
FlinkKafkaConsumer<MyType> kafkaSource = new FlinkKafkaConsumer<>("myTopic", schema, props);
kafkaSource.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(20)));DataStream<MyType> stream = env.addSource(kafkaSource);
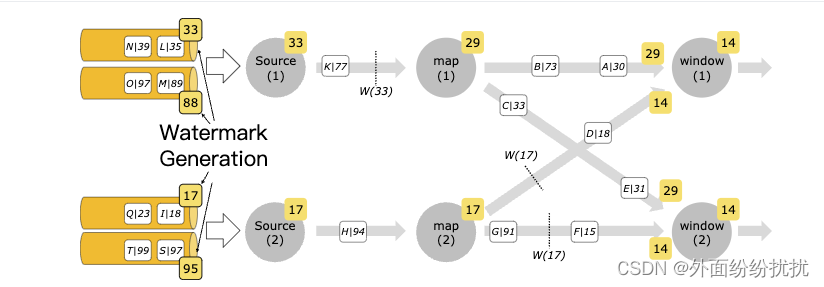
算子处理 Watermark 的方式 #
一般情况下,在将 watermark 转发到下游之前,需要算子对其进行触发的事件完全进行处理。例如,WindowOperator 将首先计算该 watermark 触发的所有窗口数据,当且仅当由此 watermark 触发计算进而生成的所有数据被转发到下游之后,其才会被发送到下游。换句话说,由于此 watermark 的出现而产生的所有数据元素都将在此 watermark 之前发出。
相同的规则也适用于 TwoInputStreamOperator。但是,在这种情况下,算子当前的 watermark 会取其两个输入的最小值。
详细内容可查看对应算子的实现:OneInputStreamOperator#processWatermark、TwoInputStreamOperator#processWatermark1 和 TwoInputStreamOperator#processWatermark2。
可以弃用 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks 了 #
在 Flink 新的 WatermarkStrategy,TimestampAssigner 和 WatermarkGenerator 的抽象接口之前,Flink 使用的是 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks。你仍可以在 API 中看到它们,但建议使用新接口,因为其对时间戳和 watermark 等重点的抽象和分离很清晰,并且还统一了周期性和标记形式的 watermark 生成方式。