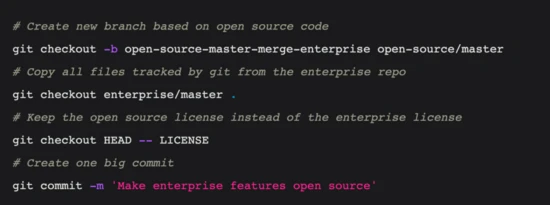
在为 Postgres 运行性能基准测试时,主要建议是:“自动化!”
如果您正在测量数据库性能,您可能不得不一遍又一遍地运行相同的基准测试。 要么是因为你想要一个稍微不同的配置,要么是因为你意识到你使用了一些错误的设置,或者可能是其他一些原因。通过自动化运行性能基准测试的方式,当发生这种情况时您不会太烦恼,因为重新运行基准测试将花费很少的精力(它只会花费一些时间)。
但是,为数据库基准测试构建这种自动化也可能非常耗时。 因此,在这篇文章中,我将分享我构建的工具,以便轻松运行针对 Postgres 的基准测试 — 特别是针对在 Azure Database for PostgreSQL 中名为 Hyperscale (Citus) 的 Azure 托管数据库服务中运行的 Postgres 的 Citus 扩展。
- https://docs.microsoft.com/azure/postgresql/hyperscale/
- https://github.com/citusdata/citus
第一部分探讨了不同类型的应用程序工作负载及其特征,以及每种常用的现成基准。 之后,您可以深入了解如何在 Azure 上将 HammerDB 与 Citus 和 Postgres 一起使用。 是的,您还会看到一些示例基准测试结果。
为什么要先深入了解不同工作负载和数据库基准测试的背景? 因为有比自动化运行性能基准的方式更重要的事情:为您选择正确的基准!
- 针对不同工作负载的不同基准
- 基准规范与完整的基准测试套件
OLTP工作负载OLAP工作负载HTAP工作负载- 比较基准测试结果的
Dangers HammerDB TPROC-C- 如何使用
HammerDB、ARM、Bicep和cloud-init对Citus进行基准测试 - 在
Azure上使用更大的Citus数据库集群达到200 万 NOPM - 享受对数据库性能进行基准测试的乐趣
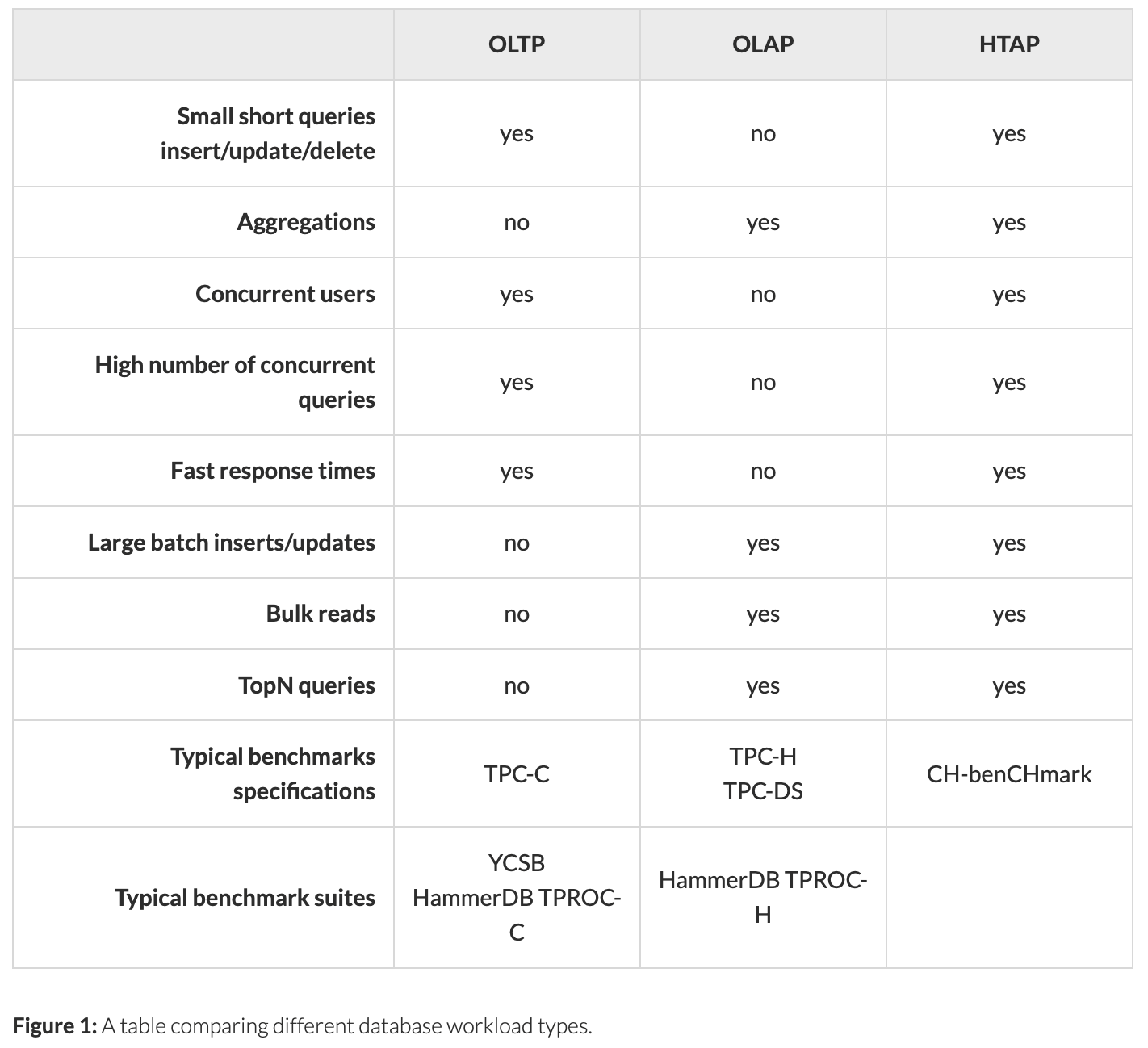
针对不同类型工作负载的不同类型基准测试
每个使用数据库的人都将它用于不同的工作负载,因为每个人都有不同的数据集并运行不同的查询。 因此,在比较数据库性能时,您将通过运行基于您自己的工作负载的基准来获得最准确的结果。 然而,准备一个完全自定义的基准测试可能需要相当多的工作。
因此,您可能希望使用与您自己的工作负载非常相似的工作负载运行现成的基准测试。
基准规范与完整的基准套件
可以通过两种不同的方式为您提供现成的基准:
- 基准测试规范。 在这种情况下,描述了如何在文档中运行基准测试。 它将告诉您如何准备表、如何加载数据以及要运行哪些查询。 但是您需要手动完成所有这些操作。
- 完整的基准测试套件。 在这种情况下,将向您提供一个应用程序,它将运行基准测试。 您将基准测试应用程序配置为针对您的数据库服务器运行 — 一旦运行完成,它会吐出一些数字来指示运行的好坏。
很明显,完整的基准测试套件通常是您想要的,因为您可以简单地启动基准测试应用程序并获得结果。如果您只有一个基准测试规范,那么您首先需要编写工具来针对数据库运行该规范。
OLTP (在线事务处理)工作负载
数据库的一个常见工作负载类别称为 OLTP(在线事务处理)。属于 OLTP 类别的工作负载会向数据库发送大量小型、短时间运行的查询(或事务)。
OLTP 工作负载的一些特征是:
- 插入、更新和删除只影响一行。 示例:将商品添加到用户的购物车。
- 读取操作仅从数据库中读取少数项目。 示例:为用户列出购物车中的商品。
- 很少使用聚合, 当它们被使用时,它们仅用于小数据集。 示例:获取用户购物车中所有商品的总价格。
创建此类工作负载的应用程序类型通常具有许多并发用户,这些用户每秒总共执行许多请求。 因此,对于 OLTP 工作负载,数据库能够同时处理大量此类查询非常重要。 应用程序的响应时间通常也很重要,因此数据库查询不应该花费很长时间来运行。 查询应始终在不到 5 秒内完成,大多数查询应在 100 毫秒内完成,甚至可能更快。
属于 OLTP 类别的知名数据库基准是 YCSB (full suite)、TPC-C (specification) 和 HammerDB TPROC-C (full suite)。人们通常感兴趣的这些 OLTP 基准测试中有两种类型的数字:
- YCSB: https://github.com/brianfrankcooper/YCSB/
- TPC-C: http://tpc.org/tpcc/default5.asp
- HammerDB TPROC-C: https://www.hammerdb.com/docs/ch03.html
TPS吞吐量(每秒事务数)- 查询延迟,通常在不同的百分位数(
p95等)
OLAP(在线分析处理)工作负载
另一种常见的数据库工作负载称为 OLAP(在线分析处理)。 这是经常在数据仓库上运行的工作负载类型。
OLAP 工作负载的一些特征是:
- 定期批量插入数据。 新数据通常是从其他系统批量添加到数据库中的。 这通常在用户不使用数据库的一天中的特定时间完成,例如本地时区的午夜。
- 读操作通常会读取数据库的大部分内容。 这样做的常见原因是回答业务分析师的问题,或者有可以在季度股东大会上展示的结果。 一些需要的问题示例:
- 去年最畅销的 10 款产品是什么?
- 上个月有多少新客户加入?
- 回头客产生了多少收入?
- 几乎每个查询都使用聚合。 鉴于读取操作读取大部分数据库聚合对于使这些数据易于被人类消化是必要的。
- 查询量大且复杂。 要回答查询,通常需要从多个不同的表中收集数据,或者需要将数据与同一个表中的不同数据进行比较。收集和组合这些数据的查询通常在单个查询中使用
SQL的许多特性,例如JOINs、CTEs、subqueries和window函数。因为它们结合了如此多的特性,OLAP查询通常变得非常庞大和复杂。
与 OLTP 不同,OLAP 系统中的并发用户通常并不多。通常一次只运行一个查询(或几个查询)。 这些查询的响应时间也远高于 OLTP 工作负载。OLAP 查询通常需要几秒钟甚至几分钟才能完成。 但当然,数据库响应时间在 OLAP 工作负载中仍然很重要,并且等待超过 20 分钟的查询结果通常是不可接受的。
属于 OLAP 类别的知名基准是 TPC-H (specification)、TPC-DS(specification) 和 HammerDB TPROC-H(full suite)。这些基准具有一组使用各种 SQL 功能的查询,并且具有不同级别的复杂性和 JOIN 数量。
- TPC-H: http://tpc.org/tpch/default5.asp
- TPC-DS: http://tpc.org/tpcds/default5.asp
- HammerDB TPROC-H: https://www.hammerdb.com/docs/ch11.html
OLAP 基准测试可以为您提供两种不同的结果:
- 运行作为基准测试一部分的所有查询需要多长时间
- 运行每个查询需要多长时间,每个查询单独测量
HTAP(混合事务/分析处理)工作负载
另一个数据库工作负载类别称为 HTAP(混合事务/分析处理)。此类别包含结合了 OLTP 和 OLAP 工作负载方面的工作负载。 因此,会有很多活跃用户在做小事务,同时运行一些繁重的长时间运行的查询。
对 HTAP 工作负载进行基准测试的挑战
在不同的运行中比较 HTAP 基准测试得出的数据是非常困难的。这源于这样一个事实: 每次运行基准测试,你会得到两个数字,这些数字通常显示出相反的相关性:
OLTP部分的TPS吞吐量(每秒事务数)OLAP部分运行分析查询所需的时间(以秒为单位)
问题是随着每秒事务数量的增加,分析查询将需要更长的时间来运行。换句话说,当 TPS 增加时 (good),OLAP 查询需要更长的时间(bad)。有两个原因:
- 更多的
TPS通常意味着机器的资源(cpu/disk)更忙于处理OLTP查询。这样做的副作用是这些资源不经常可供OLAP查询使用。 - 一定比例的
OLTP事务会将数据插入到数据库中。所以更高的TPS,意味着数据库中的数据量会增长得更快。这反过来意味着OLAP查询将不得不读取更多数据,从而变得更慢。
这些数字之间的反向相关性使得很难最终确定一个 HTAP 基准测试运行是否比另一个具有更好的结果。 只有当且仅当两个数字都更好时,您才能得出一个更好的结论。如果其中一个数字更好,而另一个数字更差,那么这就成为一个权衡问题:您可以决定您认为工作负载最重要的因素是什么:每秒 OLTP 事务的数量,或者运行 OLAP 查询所需的时间。
比较您在网上找到的基准结果的 Dangers
与其自己运行基准测试,不如比较其他人在网上发布的数据。在比较其他人运行的基准时要小心一点:配置基准有很多不同的方法。所以,比较它们通常是苹果和橙子。重要的几个差异是:
- 它是否在生产基础架构上运行? 当关键的生产功能被禁用时,通常可以实现更多的性能。备份、高可用性 (
HA) 或安全功能(如TLS)等都会影响性能。 - 使用的数据集有多大? 它是否适合RAM? 从磁盘读取比从
RAM读取慢得多。因此,如果所有数据都适合RAM,那么对于基准测试的结果非常重要。 - 硬件是否过于昂贵? 显然,每月花费 500 美元的数据库的性能预计会比每月花费 50,000 美元的数据库差。
- 使用了什么基准实现? 许多供应商发布了 TPC 基准规范的结果,其中基准是使用规范的自定义实现运行的。这些实现通常未经验证,因此可能无法正确实现规范。
因此,虽然比较您在网上找到的数据库基准数字是最容易的,但您可能也想用自己的数据运行自己的基准。
用于 OLTP 工作负载的 HammerDB TPROC-C
HammerDB 是一个易于使用的开源数据库基准测试套件。 HammerDB 可用于运行 OLTP 或 OLAP 基准测试。 OLTP 称为 TPROC-C1,基于 TPC-C 规范。OLAP 基准称为 TPROC-H,它基于 TPC-H 规范。 HammerDB 为许多不同的数据库实现了这些基准测试,这使得比较不同数据库类型的结果变得容易。
- HammerDB: https://www.hammerdb.com/
- TPC-C: http://tpc.org/tpcc/default5.asp
- TPC-H: http://tpc.org/tpch/default5.asphttp://tpc.org/tpch/default5.asp
我已经向 HammerDB 提交了几个 PR 以改进基准测试套件。这些 PR 之一使 HammerDB TPROC-C 与 Citus 对 Postgres 的扩展一起工作(因此与分布式 PostgreSQL 一起工作)。 另外两个大大提高了将基准数据加载到 Postgres 的速度。我所有的 PR 都已被接受并在 HammerDB 4.4 中发布。 因此,从 HammerDB 4.4 开始,您可以针对 Citus 运行 HammerDB TPROC-C 基准测试。
- https://github.com/TPC-Council/HammerDB/pulls?q=is%3Apr+author%3AJelteF
- https://github.com/TPC-Council/HammerDB/releases/tag/v4.4
HammerDB 为您提供的用于比较基准运行的主要数字称为 NOPM(每分钟新订单数)。 HammerDB 使用 NOPM 而不是 TPS(每秒事务数),以使 HammerDB 支持的不同数据库之间的数量具有可比性。测量 NOPM 的方式是基于官方 TPC-C 规范中的 tpmC 指标——尽管在 HammerDB 中,它被称为 NOPM 而不是 tpmC,因为 tpmC 在技术上用于官方的、经过全面审核的基准测试结果。
- https://www.hammerdb.com/blog/uncategorized/why-both-tpm-and-nopm-performance-metrics/
如何使用 HammerDB、ARM、Bicep、tmux 和 cloud-init 在 Azure 上对 Citus 和 Postgres 进行基准测试
就像我在开头提到的那样,运行基准测试时最重要的是自动运行它们。根据我的经验,您将(几乎)重新运行相同的基准测试!
因此,我围绕 HammerDB 创建了开源基准测试工具(GitHub repo),以使运行基准测试更加容易——尤其是对于在 Azure 上运行的 Postgres 的 Citus 扩展。 当您使用 Postgres 扩展时,涉及到两层数据库软件:您既在 Postgres 数据库上运行,也在 Postgres 扩展上运行。 因此,我为 Citus 创建的开源基准测试自动化在 Azure Database for PostgreSQL 托管服务中的 Hyperscale (Citus) 选项上运行基准测试。
- https://github.com/citusdata/citus-benchmark/tree/master/azure
- https://docs.microsoft.com/azure/postgresql/
- https://docs.microsoft.com/azure/postgresql/hyperscale/
我创建的基准测试工具使用各种东西使运行基准测试尽可能简单:
- Bicep 格式的 ARM 模板用于预配基准测试所需的所有 Azure 资源。 它预配了您需要的主要内容:Citus 数据库集群,特别是 Azure Database for PostgreSQL 中的 Hyperscale (Citus) 服务器组。 但它还提供了一个单独的 VM,用于在其上运行基准测试程序 — 该 VM 也称为“driver VM”。
- https://docs.microsoft.com/azure/azure-resource-manager/bicep/overview
- https://docs.microsoft.com/azure/azure-resource-manager/templates/overview
- Tmux 用于在后台运行基准测试。 没有什么比在 5 小时后重新启动 6 小时基准测试更糟糕的了,只是因为您的互联网连接中断了。Tmux 通过保持基准应用程序在后台运行来解决这个问题,即使您断开连接也是如此。
- https://github.com/tmux/tmux/wiki
- cloud-init 脚本用于启动基准测试。 驱动程序 VM 的 ARM 模板包含一个 cloud-init 脚本,该脚本会在 Postgres 变得可访问时自动启动基准测试。 这样,您可以在开始配置过程后高枕无忧。配置数据库和驱动程序 VM 后,基准测试将自动开始在后台运行。
- https://docs.microsoft.com/azure/virtual-machines/linux/using-cloud-init
在撰写本文时,我创建的开源基准测试工具支持运行 HammerDB TPROC-C (OLTP) 和 CH-benCHmark 规范 (HTAP) 的自定义实现。 但是,即使您想运行不同的基准测试,我创建的工具可能仍然对您非常有用。 运行另一个基准测试时唯一需要更改的应该是 cloud-init 脚本中安装和启动基准测试的部分。随时向存储库发送 PR 以添加对另一个基准测试的支持。
- https://github.com/citusdata/citus-benchmark/tree/master/azure
- https://github.com/citusdata/citus-benchmark/blob/6052801fad5c360acfee203342bbe3c25f1d54b0/azure/driver-vm.bicep#L75-L81
关于 Citus 数据库配置的提示
除了自动化你的基准测试之外,还有一些与 Citus 和 Postgres 相关的事情,在运行基准测试时你应该记住:
- 不要忘记分发 Postgres 表! 大多数基准测试工具没有内置支持使用 Citus 扩展分发 Postgres 表,因此您需要添加一些分发表的步骤。 如果可能,最好在加载数据之前执行此操作,这样加载数据会更快。
- 选择正确的分布列。 使用 Citus 分布表时,选择正确的分布列很重要,否则性能会受到影响。 什么是正确的分布列取决于基准中的查询。 幸运的是,我们提供了有关为您选择正确分布列的建议的文档。
- https://docs.citusdata.com/en/v10.2/sharding/data_modeling.html
- 构建数据集后,在所有表上运行 VACUUM ANALYZE。否则,Postgres 统计信息可能完全错误,您可能会得到非常慢的查询计划。
- 确保您的 shard_count 是您拥有的 worker 数量的倍数。否则,分片无法在您的 worker 之间平均分配,并且一些 worker 会比其他 worker 获得更多的负载。一个好的默认
shard_count是 48,因为数字 48 可以被很多数字整除。
如何使用 citus-benchmark 工具运行 HammerDB 基准测试
就像我说的,我试图让运行基准测试尽可能简单。因此,您需要做的就是运行这个简单的命令(有关详细说明,请查看“azure”目录中的自述文件):
- https://github.com/citusdata/ch-benchmark/tree/master/azure
# 重要说明:运行此命令将在您的 Azure 订阅中配置 4 个新的 Citus 集群
# 和 4 个 64-vCore driver VM。
# 因此,运行以下命令将花费您(或您的雇主)的钱!
azure/bulk-run.sh azure/how-to-benchmark-blog.runs | tee -a results.csv上面的命令将开始在 Hyperscale (Citus) 的生产基础架构上的几个不同集群大小上运行 HammerDB TPROC-C,这是 Azure Database for PostgreSQL 托管服务中的一个部署选项。这些基准运行的结果都收集在 results.csv 文件。
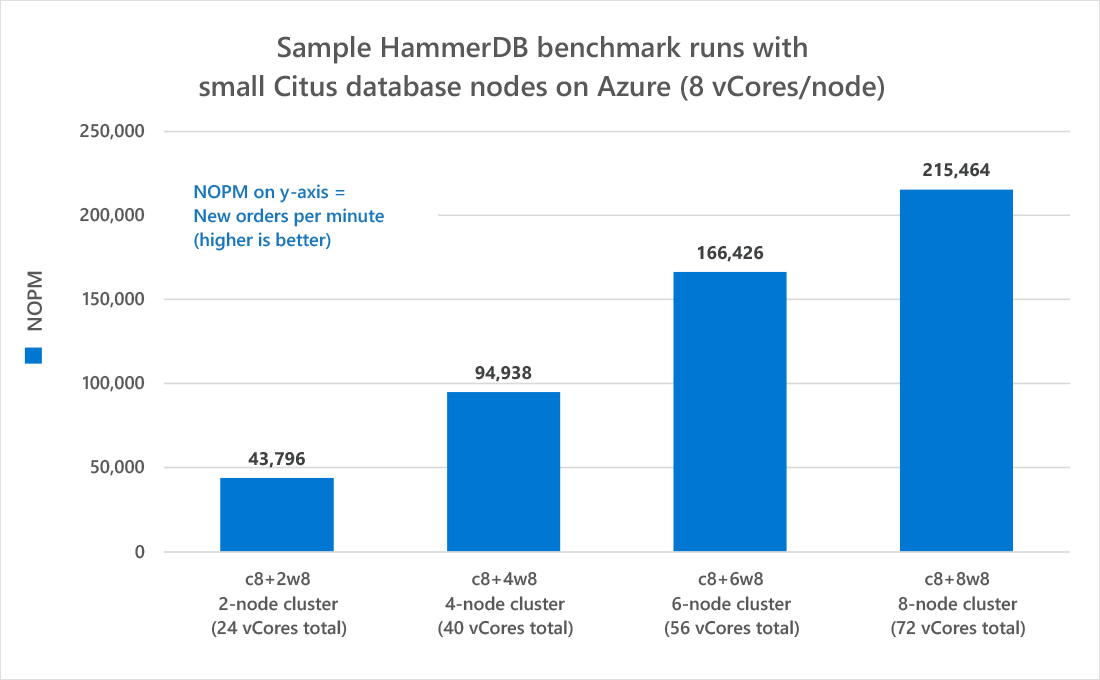
当您查看新创建的 results.csv 文件时,您会看到类似于 “c4+2w8” 的字符串:
- c4+2w8: 这只是一个简短的说法,即该运行的集群有一个 4 vCore 协调器 (“c”) 和 2 个工作器 (“2w”),两者都有 8 vCore。
集群中存在的内核总数也显示在括号中。
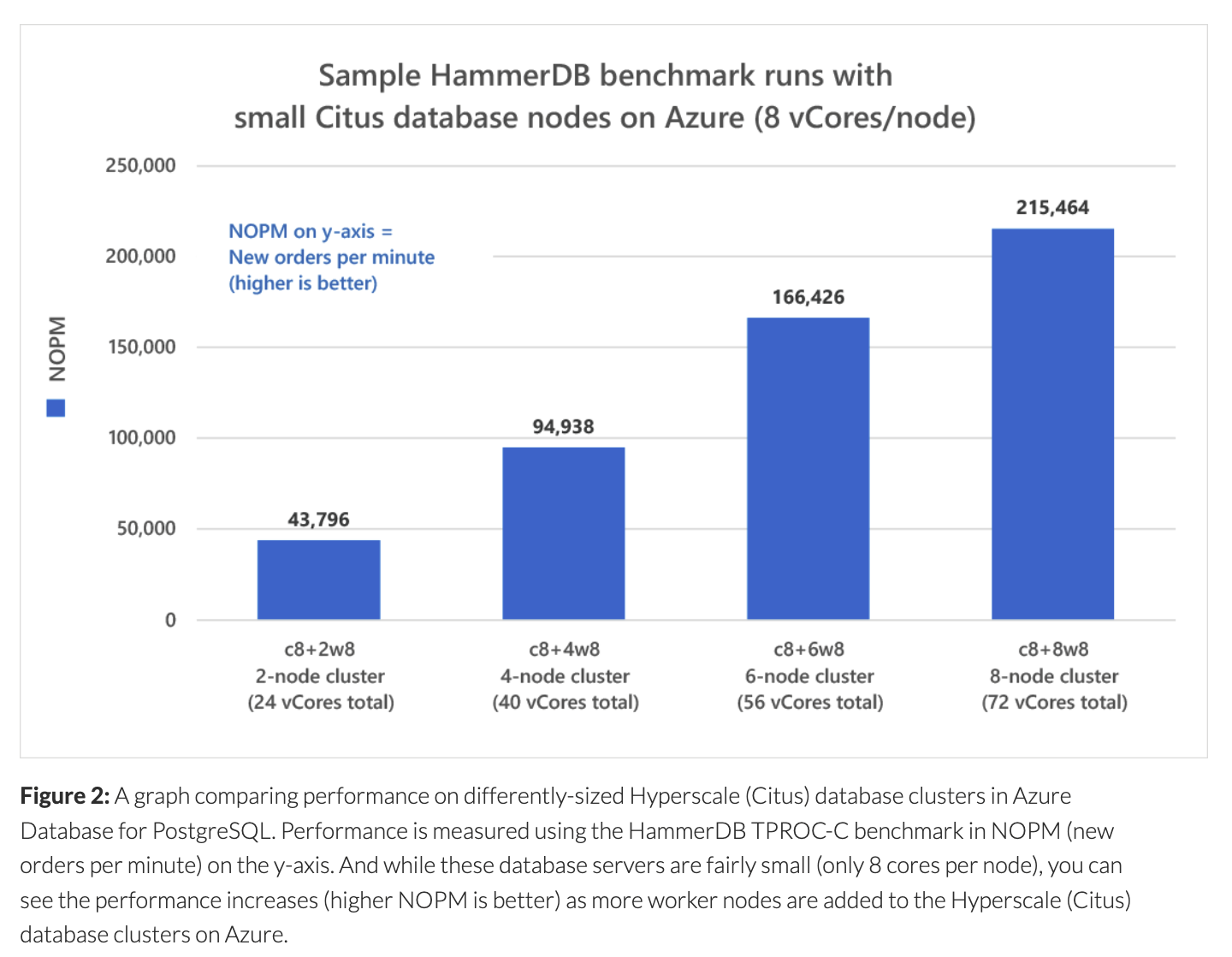
如您所见,当您向 Citus 集群添加更多 worker 时,NOPM 会不断增加。这表明 Citus 兑现了横向扩展的承诺:只需向 Azure Database for PostgreSQL 中的集群添加更多 Citus 节点,我们的性能就会提高。
在 Azure 上使用更大的 Citus 数据库集群达到 200 万 NOPM
上图中的数字是使用相对较小的 Citus 集群收集的。 该图表的主要目的是向您展示使用 HammerDB 和我创建的开源基准测试工具获取这些数字是多么容易。
如果增加每个数据库节点上的 vCore 数量和/或增加 Citus 集群中的 worker 节点总数,则可能会在 Azure 上观察到更高的 Citus 基准测试结果。 我们在 SIGMOD ‘21 接受的论文中可以看到具有更多 vCore 的更高性能。我们使用了一个协调器和 8 个 16 核的 worker,那篇论文中的 NOPM 高得多。
最近,我们还在一个非常大的 Citus 数据库集群上运行了 HammerDB TPROC-C,并使用我们在 Azure 上的常规托管服务基础架构获得了高达 200 万的 NOPM。
有关此 2M NOPM HammerDB 结果的更多详细信息:
- 用于此基准测试的 Azure Database for PostgreSQL - Hyperscale (Citus) 数据库集群有 64 个核协调器和 20 个工作节点,每个节点有 32 个核(因此总共 704 个核。)
- 除了使用比本文前面讨论的示例运行更多的工作节点和每个节点更多的 vCore 之外(详情见上面的图2),为了实现 2M NOPM,还需要修改另一件事: 需要配置
HammerDB以使用更多的并发连接。上面图2所示的较早的示例基准测试运行使用了 250 个连接,但为了使这个大集群始终处于繁忙状态,我将 HammerDB 配置为使用 5000 个连接。
Azure Database for PostgreSQL 中的 Hyperscale (Citus) 服务器组默认提供的连接数取决于协调器大小,系统将最大用户连接数设置为 1000。要增加它,您只需联系 Azure 支持并请求将 Postgres 14 上的最大用户连接数增加到至少 5000 个——为了安全起见,多一点更好——对于您的超大规模 (Citus) 服务器组。 因此,创建一个可以重现 2M NOPM 结果的超大规模 (Citus) 集群只需一张支持票即可。 之后,您可以简单地使用我的基准测试工具对该集群运行基准测试。
享受对数据库性能进行基准测试的乐趣
比较数据库或云提供商的性能似乎令人生畏。 但是借助本博客中提供的知识和工具,在 Azure Database for PostgreSQL 中对 Hyperscale (Citus) 的数据库性能进行基准测试应该会容易得多。 在自己运行任何性能基准测试时,请确保:
- https://docs.microsoft.com/azure/postgresql/hyperscale/
- 选择与您的工作负载相匹配的基准测试。 您的工作负载是否属于 OLTP、OLAP 或 HTAP 类别?
- 自动化运行基准测试。 ARM、Bicep、tmux 和 cloud-init 可以让运行数据库性能基准测试变得轻而易举。您甚至可以重用我编写的开源工具!
- https://docs.microsoft.com/en-gb/azure/azure-resource-manager/templates/overview
- https://docs.microsoft.com/en-gb/azure/azure-resource-manager/bicep/overview?tabs=bicep
- https://github.com/tmux/tmux/wiki
- https://docs.microsoft.com/en-gb/azure/virtual-machines/linux/using-cloud-init
- https://github.com/citusdata/citus-benchmark/tree/master/azure
无论您是希望以自我管理的方式在 Citus 开源上运行您的应用程序,还是希望在 Azure 上的托管数据库服务上运行应用程序,使用 Citus 扩展 Postgres 都很容易。
- https://www.citusdata.com/getting-started/