目录
- 1.前言
- 2.embedding表示方法
- 2.1 word2vec embedding
- 2.2 neural network embedding
- 2.3 graph embedding
- 3.参考文献
1.前言
近几年embedding的使用及优化在各种比赛、论文中都有很多的应用,使用embedding表示特征的空间表示也在各种应用中确定是一种很有效的特征表示方法,基于embedding进行的特征交叉的工作也有很多,因此本文主要整理常用的embedding表示方法及原理
2.embedding表示方法
embedding的制作方法比较常见的有word2vec embedding,neural network embedding和graph embedding,本文主要对这三种方法进行论述,embedding实际上就是把原先的特征表示映射到一个新的空间表达中去
embedding的训练方法大致可以分为两类,一类是无监督或弱监督的预训练,一类是端对端的有监督训练,无监督或弱监督的训练以word2vec为代表,不需要标记可以得到质量还可以的embedding表示,但因为缺少任务导向,一般在得到预训练的embedding向量后,用少量人工标注的样本fine-tune模型

2.1 word2vec embedding
word2vec基本操作如下图,
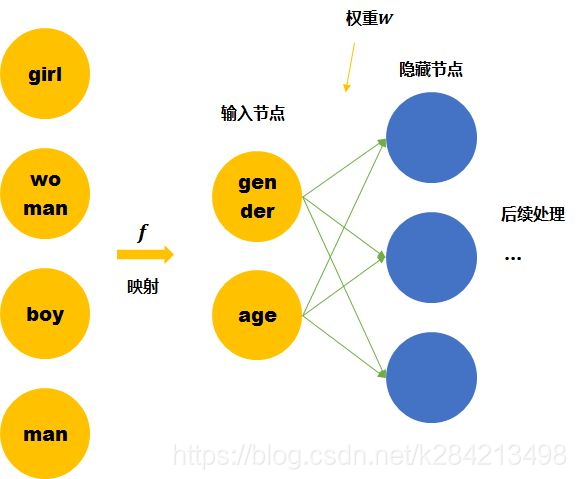
整个隐层的激活函数是线性的,相当于没有做任何处理,当神经网络训练完后,最后得到的是神经网络的权重
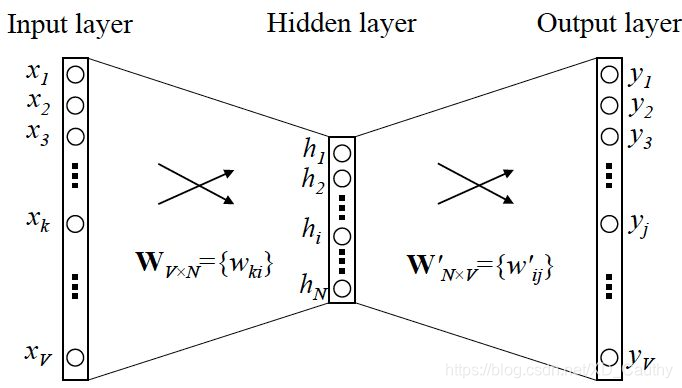
word2vec共有两种常见的模型,cbow和skip-gram模型,
cbow模型拿一个词的上下文作为输入,来预测词语本身
skip-gram用一个词语作为输入,预测周围的上下文

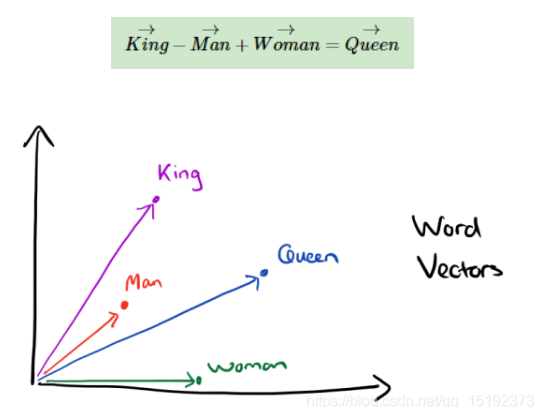
对于单个word对应多种embedding的情况,采用平均是最简单的方法,如果说存在一词多义的问题,可以采用根据场景选择适合的embedding的方式,也可以采用动态embeded的方式,通过上下文调整最终的embedding
2.2 neural network embedding
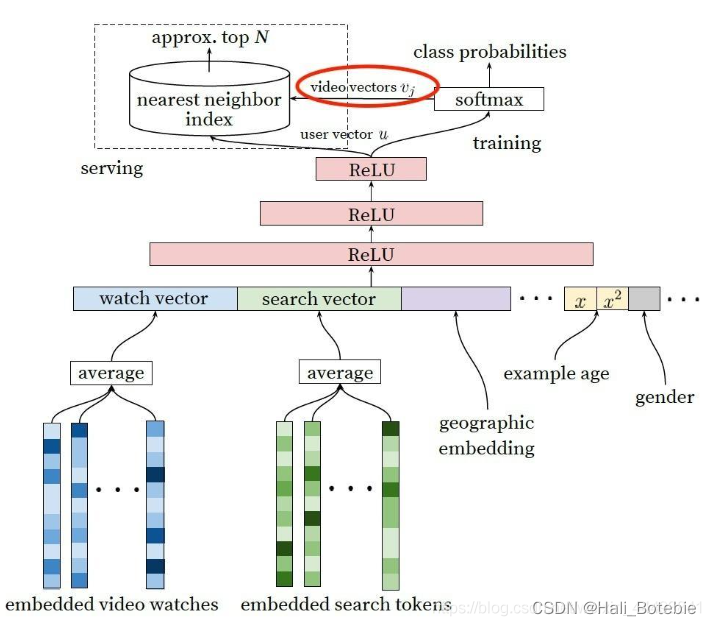
dnn生成embeddding的方式,这里引用Deep Neural Networks for YouTube Recommendations,是google在2016年发的一篇文章,其中user vector是dnn的最后一层的输出,video vector是weighted softmax(sampled)的权重序列,论文当时的做法是将video vector的作为视频表征存储,然后在serve阶段,计算出user vector,再通过最近邻的方式计算要推荐的视频内容,接下来将候选集合进行下一阶段的排序工作

2.3 graph embedding
(1)deepwalk(2014)
下图明确说明了通过deepwalk生成graph embedding的过程

具体可分为以下几步:
1.图a展示了原始的用户行为序列
2.图b基于这些用户行为序列构建了物品相关图,可以看出,物品A,B之间的边产生的原因就是因为用户U1先后购买了物品A和物品B,所以产生了一条由A到B的有向边。如果后续产生了多条相同的有向边,则有向边的权重被加强。在将所有用户行为序列都转换成物品相关图中的边之后,全局的物品相关图就建立起来了
3.图c采用随机游走的方式随机选择起始点,重新产生物品序列
4.图d最终将这些物品序列输入word2vec模型,生成最终的物品embedding向量
(2)node2vec(2016)
node2vec是一种基于deepwalk的改进的graph embedding的优化算法,主要有两种生成embedding的遍历方法,深度优先游走(Depth-first Sampling,DFS)和广度优先游走(Breadth-first Sampling,BFS)
使用着两种算法,主要想体现graph embedding的同质性和结构性,其中‘’同质性‘’指的是距离相近节点的embedding应该尽量近似,用BFS来做,“结构性”指的是结构上相似的节点的embedding应该尽量接近,用DFS来做

如下图所示,是算法在选择下一个连接节点的过程,通过给是否与t相等,相连的三种情况,分配选择的权重

具体做法:
1.根据p、q和之前的公式计算一个节点到它的邻居的转移概率
2.将这个转移概率加到图G中形成G’
3.walks用来存储随机游走,先初始化为空
4.外循环r次表示每个节点作为初始节点要生成r个随机游走
5.然后对图中每个节点
6.生成一条随机游走walk
7.将walk添加到walks中保存
8.然后用SGD的方法对walks进行训练(与deepwalk相同)
(3)EGES(2018)
如果单纯使用用户行为生成的物品相关图,固然可以生成物品的embedding,但是如果遇到新加入的物品,或者没有过多互动信息的长尾物品,推荐系统将出现严重的冷启动问题。为了使“冷启动”的商品获得“合理”的初始Embedding,阿里团队通过引入了更多补充信息来丰富Embedding信息的来源,从而使没有历史行为记录的商品获得Embedding
基于知识图谱生成对同一个物品的多个graph表示,然后对graph embeddding进行加权平均,主要是解决了添加物品的冷启动问题

3.参考文献
1.理解 Word2Vec 之 Skip-Gram 模型
2.Skip-Gram二三事
3.Embedding 技术在推荐系统中的实践总结
4.深度学习中不得不学的Graph Embedding方法