Embedding 嵌入,我们可以将其理解为一种降维行为。可以将高维数据映射到低维空间来解决稀疏输入数据的问题。
它主要有以下三个目的:
- 在 embedding 空间中查找最近邻,这可以很好的用于根据用户的兴趣来进行推荐。
- 作为监督性学习任务的输入。
- 用于可视化不同离散变量之间的关系。
此时,我们先介绍一下One Hot编码。这是一种表示离散数据很常见的编码方法,用N位状态寄存器对N个状态进行编码。
编码的第一步是确定编码对象,eg:[“中国”、“美国”、“日本”、“中国”],紧接着确定分类变量-- 中国 美国 日本共三种类别。那么对于每一个样本都有三种特征。对应的One Hot编码如下:
[“中国”、“美国”、“日本”、“中国”]--> [ [1,0,0], [0,1,0], [0,0,1], [1,0,0] ]
这时,我们可以发现One Hot由于对N个离散变量的某一对象用N-1个0和单个1组成的vector表示类别,那此时具有以下缺陷:
- 对于具有非常多类型的类别变量,变换后的向量维数过于巨大,且过于稀疏。
- 映射之间完全独立,并不能表示出不同类别之间的关系。
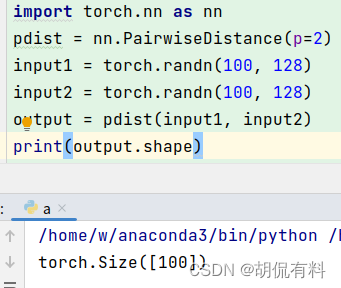
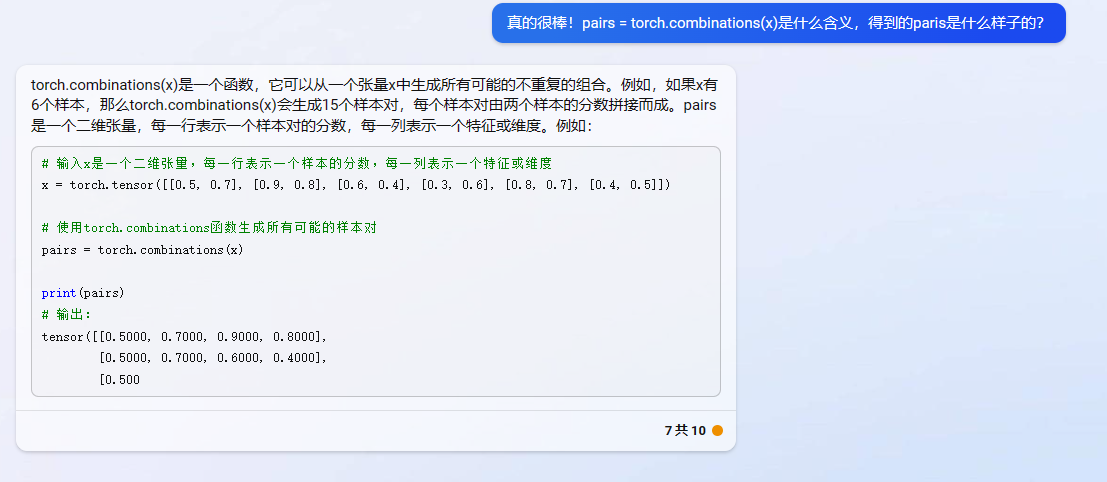
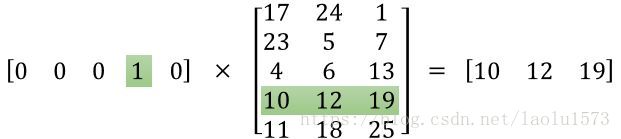
基于此,我们考虑可不可以用较少的维度表示每个类别,同时还可以变现出不同类别变量之间的关系。既然Embedding某种意义上可以说是降维的,那么我们假设现在有一个2*6的矩阵,然后乘一个6*3的矩阵就变成了一个2*3的矩阵。即从12个元素变成了6个元素。我们可以看做Embedding的降维原理就是矩阵乘法。深度学习中Embedding层可以看作一个特殊的全连接层,其输入为one hot输入,中间层结点为字向量维数的全连接层。
假设,我们现在只有4个词汇,girl, woman, boy, man。
对于One Hot:每个单词都会看作一个节点,每个维度之间是独立的,不会对其他维度的训练产生影响。

在我们想降维处理时,我们会发掘这四个节点之间的关系:

此时我们可以用两个结点表示四个单词,每个节点取不同值意义如上表。那么此时,girl就可以表示为[0,1],而man则可以表示为[1,1]。(第一个维度是gender,第二个维度为age)
此时神经网络需要学习的连接线权重就缩小到了2*3。

Word embedding也就是要达到第二个神经网络所表示的结果,降低训练所需要的数据量。









![推荐系统[四]:精排-详解排序算法LTR (Learning to Rank): poitwise, pairwise, listwise相关评价指标,超详细知识指南。](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)