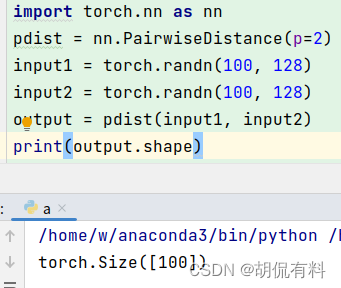
[1] 名词理解
embedding层:嵌入层,神经网络结构中的一层,由embedding_size个神经元组成,[可调整的模型参数]。是input输入层的输出。
词嵌入:也就是word embedding…根据维基百科,被定义为自然语言处理NLP中的一组语言建模和特征学习技术的集体名称,其中来自词汇表的单词或者短语被映射成实数向量。
word2vec:词嵌入这个技术的具体实现,也可以理解成是将向量从高维度映射到低维度的计算过程。 具体的包含两种处理方式也就是两个典型的模型—CBOW模型和SG模型。假设,原始数据有F个特征,通过one-hot编码后,表示成N维的向量,即input层的维度是N,和权重矩阵相乘,变成embedding_size维的向量。(embedding_size <N)
词向量:也就是通过word2vec计算处理后的结果的释义。比如说…从input输入层到embedding层的权重矩阵,记作是N*embedding_size的,那么这个矩阵的一行就是一个词向量,是第几行就对应input输入层one-hot编码中第几列那个1所对应的词。
[2] embedding层模型
embedding层模型如下图所示:

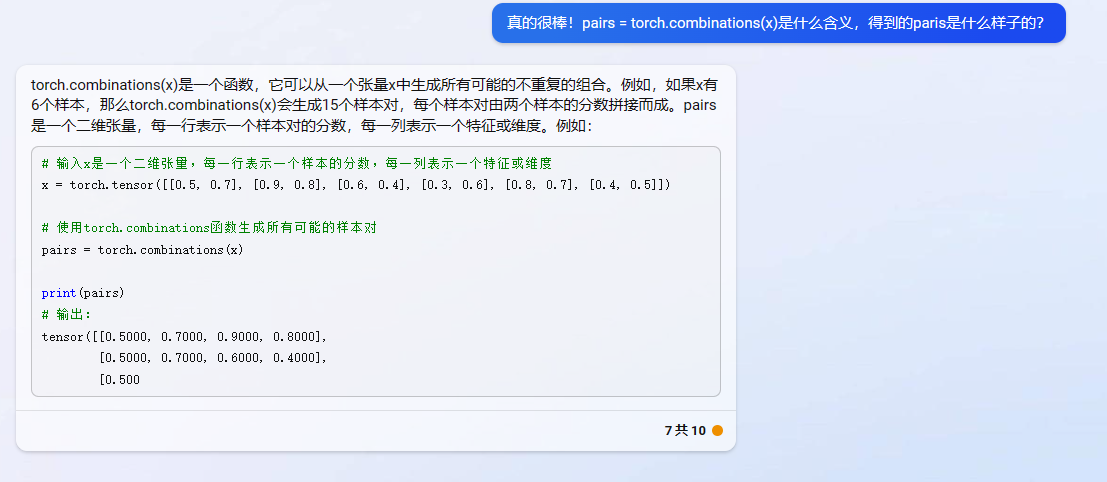
很多人说【词向量只是embedding层训练的一个中间产物】,从上面的模型图中可以很容易理解。在深度学习处理此类问题中,我们关心的是文本如果通过向量表示,向量化的文本才是最终产物。对于embedding层,输入是分词后的序列,输出是向量化文本,中间会计算参数矩阵,就是词向量。所以说它是中间产物。
[2.1] 文本预处理
首先拿到的数据集是比较原始的,一条文本(content)+标签(label):
content|label
皮肤真好啊|女性
翻开课本|校园
然后要对文本进行分词,一条文本(词语list)+标签(label):
content|label
['皮肤','真好','啊']|女性
['翻开','课本']|校园
构建数据集的词典,把文本用词典索引表示:
· 词典:
0 '皮肤'
1 '真好'
2 '啊'
3 '翻开'
4 '课本'
·表示:
content|label
[0, 1, 2]|女性
[3, 4]|校园
[2.2] 数据集分批(batch)
这里使用的是torch的分批。
同一batch里,文本长度要一致。所以torch会使长度相近的文本分在一个batch里,这样降低填充/删减文本数据带来的误差。
[2.3] 参数矩阵(词向量)
上图中,假设1个batch内的文本数为k,每篇文本中的词语数为4,嵌入层的维度为n,|v|为词典中的总词数,那么输入为(k,4)的张量,文本矩阵为(k,4,n)的三维张量,嵌入层参数矩阵形状为(|v|,n)。
从降维的角度看,定义了嵌入层的维度为n后,词向量就是把词典中的所有词用n个维度来表征出来,相当于特征提取。
举个例子:假设词典里面的每个词是一个个人,那么嵌入层维度就相当于人的‘鼻子’、‘眼睛’、‘身高’等等属于人的特征。那么我取嵌入层维度为n,就是取在我本次词典中的这些人,最能区别他们的前n个特征是什么、权重如何。只不过我们提取出的词典的n个特征并不是那么好理解,没法像‘鼻子’、‘眼睛’、‘身高’这么直观。
[2.4] 文本矩阵
对于一个batch中的一条文本,会有一个文本矩阵。这个文本矩阵的行数是这个文本的词数,列数是嵌入层维度。好好看看上图,理解一下对应关系,图中已经用颜色标注。但这不是最终输出。
[2.5] 最终输出的文本矩阵
在文本矩阵的基础上,相加求均值。
[3] embedding层批次与word2vec
embedding层模型如上图所示。在得到batch数据之后,Embedding层还不能直接计算,需要使用word2vec算法思想来把数据进一步细分,之后才能训练。
Word2Vec模型介绍
Word2Vec模型实际上分为了两个部分,第一部分为训练数据集的构造,第二部分是通过模型获取词嵌入向量,即word embedding。
Word2Vec的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,并不会用这个训练好的模型处理新任务,而真正需要的是这个模型通过训练数据所更新到的参数。
关于word embedding的发展,由于考虑上下文关系,所以模型的输入和输出分别是词汇表中的词组成,进而产生出了两种词模型方法:Skip-Gram和CBOW。同时,在隐藏层-输出层,也从softmax()方法演化到了分层softmax和negative sample方法。
所以,要拿到每个词的词嵌入向量,首先需要理解Skip-Gram和CBOW。下图展示了CBOW和Skip-Gram的网络结构:

以Skip-Gram为例,来理解词嵌入的相关知识。Skip-Gram是给定input word来预测上下文。我们可以用小学英语课上的造句来帮助理解,例如:“The __________”。
关于Skip-Gram的模型结构,主要分为几下几步:
1、从句子中定义一个中心词,即Skip-Gram的模型input word
2、定义skip_window参数,用于表示从当前input word的一侧(左边及右边)选取词的数量。
3、根据中心词和skip_window,构建窗口列表。
4、定义num_skips参数,用于表示从当前窗口列表中选择多少个不同的词作为output word。
假设有一句子"The quick brown fox jumps over the lazy dog" ,设定的窗口大小为2(window_size=2),也就是说仅选中心词(input word)前后各两个词和中心词(input word)进行组合。如下图所示,以步长为1对中心词进行滑动,其中蓝色代表input word,方框代表位于窗口列表的词。

所以,我们可以使用Skip-Gram构建出神经网络的训练数据。
我们需要明白,不能把一个词作为文本字符串输入到神经网络中,所以我们需要一种方法把词进行编码进而输入到网络。为了做到这一点,首先从需要训练的文档中构建出一个词汇表,假设有10,000个各不相同的词组成的词汇表。那么需要做的就是把每一个词做One hot representation。此外神经网络的输出是一个单一的向量(也有10000个分量),它包含了词汇表中每一个词随机选择附近的一个词的概率。


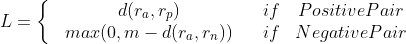

![推荐系统[四]:精排-详解排序算法LTR (Learning to Rank): poitwise, pairwise, listwise相关评价指标,超详细知识指南。](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)