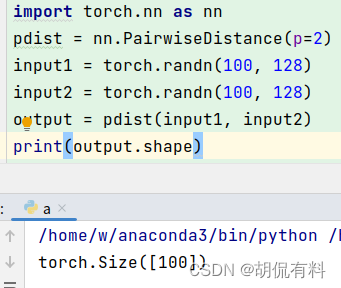
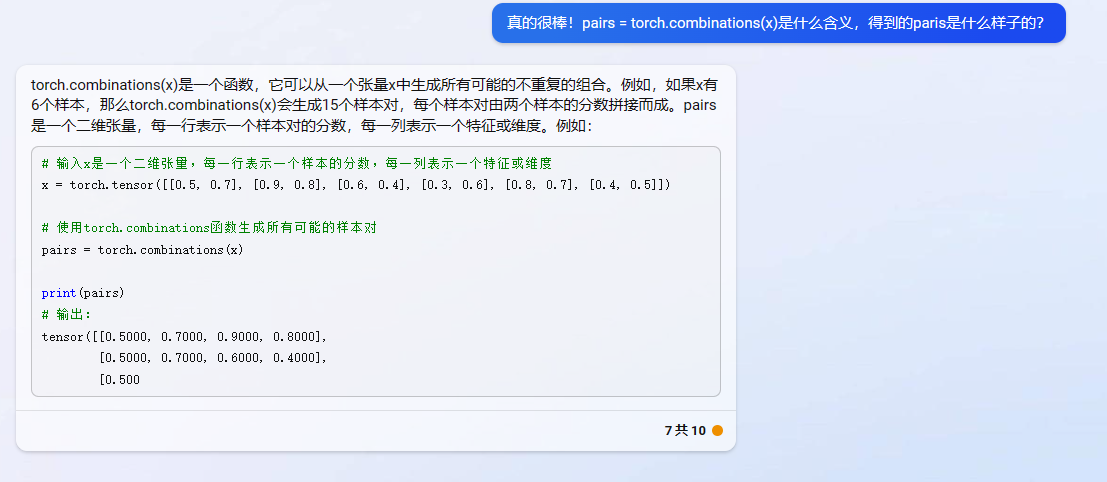
(2021.05.26补充)nn.Embedding.from_pretrained()的使用:
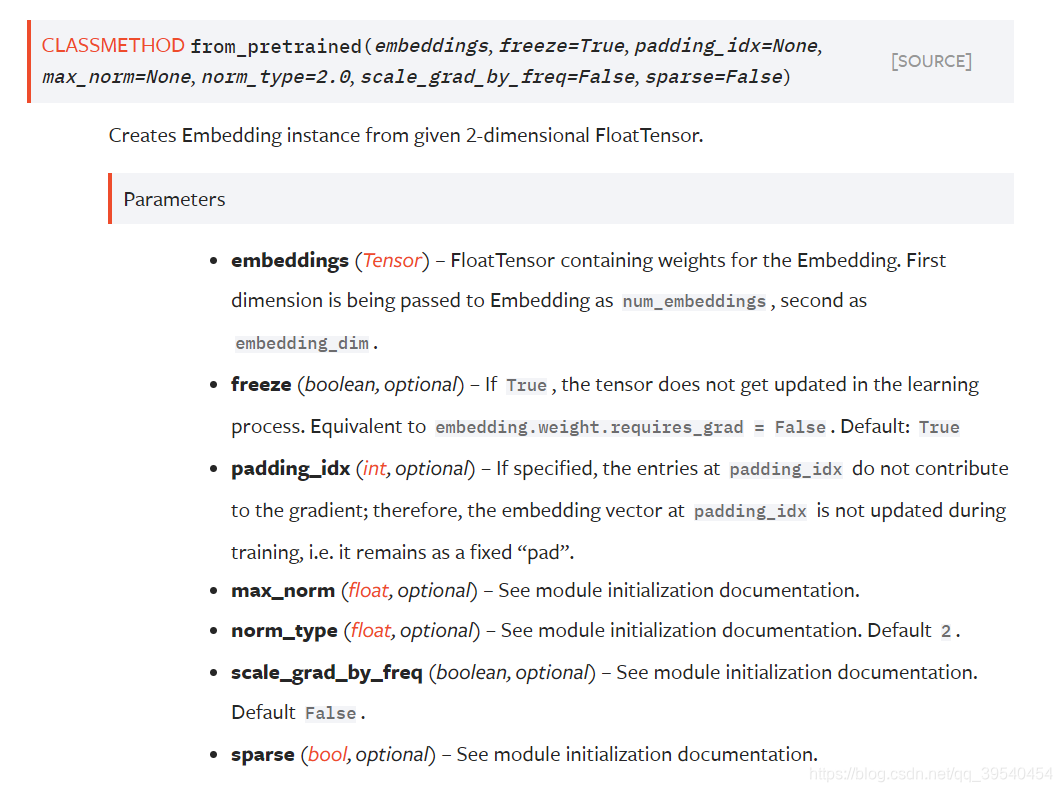
>>> # FloatTensor containing pretrained weights
>>> weight = torch.FloatTensor([[1, 2.3, 3], [4, 5.1, 6.3]])
>>> embedding = nn.Embedding.from_pretrained(weight)
>>> # Get embeddings for index 1
>>> input = torch.LongTensor([1])
>>> embedding(input)
tensor([[ 4.0000, 5.1000, 6.3000]])
首先来看official docs对nn.Embedding的定义:
是一个lookup table,存储了固定大小的dictionary(的word embeddings)。输入是indices,来获取指定indices的word embedding向量。

](https://img-blog.csdnimg.cn/2021032518101276.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM5NTQwNDU0,size_16,color_FFFFFF,t_70)
习惯性地,(1)把从单词到索引的映射存储在word_to_idx的字典中。(2)索引embedding表时,必须使用torch.LongTensor(因为索引是整数)
官方文档的示例:
>>> # an Embedding module containing 10 tensors of size 3
>>> embedding = nn.Embedding(10, 3)
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
>>> embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],[-0.6431, 0.0748, 0.6969],[ 1.4970, 1.3448, -0.9685],[-0.3677, -2.7265, -0.1685]],[[ 1.4970, 1.3448, -0.9685],[ 0.4362, -0.4004, 0.9400],[-0.6431, 0.0748, 0.6969],[ 0.9124, -2.3616, 1.1151]]])
我不太懂的是定义完nn.Embedding(num_embeddings-词典长度,embedding_dim-向量维度)之后,为什么就可以直接使用embedding(input)进行输入。
我们来仔细看看:
>>> embedding = nn.Embedding(10, 3)
构造一个(假装)vocab size=10,每个vocab用3-d向量表示的table
>>> embedding.weight
Parameter containing:
tensor([[ 1.2402, -1.0914, -0.5382],[-1.1031, -1.2430, -0.2571],[ 1.6682, -0.8926, 1.4263],[ 0.8971, 1.4592, 0.6712],[-1.1625, -0.1598, 0.4034],[-0.2902, -0.0323, -2.2259],[ 0.8332, -0.2452, -1.1508],[ 0.3786, 1.7752, -0.0591],[-1.8527, -2.5141, -0.4990],[-0.6188, 0.5902, -0.0860]], requires_grad=True)
可以看做每行是一个词汇的向量表示!
>>> embedding.weight.size
torch.Size([10, 3])
和nn.Embedding处的定义一致
>>> input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
>>> input
tensor([[1, 2, 4, 5],[4, 3, 2, 9]])
牢记:input是indices
>>> input.shape
torch.Size([2, 4])
Input size表示这批有2个句子,每个句子由4个单词构成
>>> a = embedding(input)
>>> a
tensor([[[-1.1031, -1.2430, -0.2571], [ 1.6682, -0.8926, 1.4263], [-1.1625, -0.1598, 0.4034],[-0.2902, -0.0323, -2.2259]],[[-1.1625, -0.1598, 0.4034],[ 0.8971, 1.4592, 0.6712],[ 1.6682, -0.8926, 1.4263],[-0.6188, 0.5902, -0.0860]]], grad_fn=<EmbeddingBackward>)
a=embedding(input)是去embedding.weight中取对应index的词向量!
看a的第一行,input处index=1,对应取出weight中index=1的那一行。其实就是按index取词向量!
>>> a.size()
torch.Size([2, 4, 3])
取出来之后变成了2*4*3的张量。
终于弄懂了,爽了






![推荐系统[四]:精排-详解排序算法LTR (Learning to Rank): poitwise, pairwise, listwise相关评价指标,超详细知识指南。](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)