事情是这样的,有一个图片数据集需要根据分成很多类以便于给其设置标签,但所有的图片都在一个文件里,另外又给了个.txt文件,其中每行都是对应图片的类别。例如第1行对应的第0001.jpg是第14类(每个类都有多张图片),显而易见,.txt文件的行数和图片的总数是相等的。
以下为待分类的文件: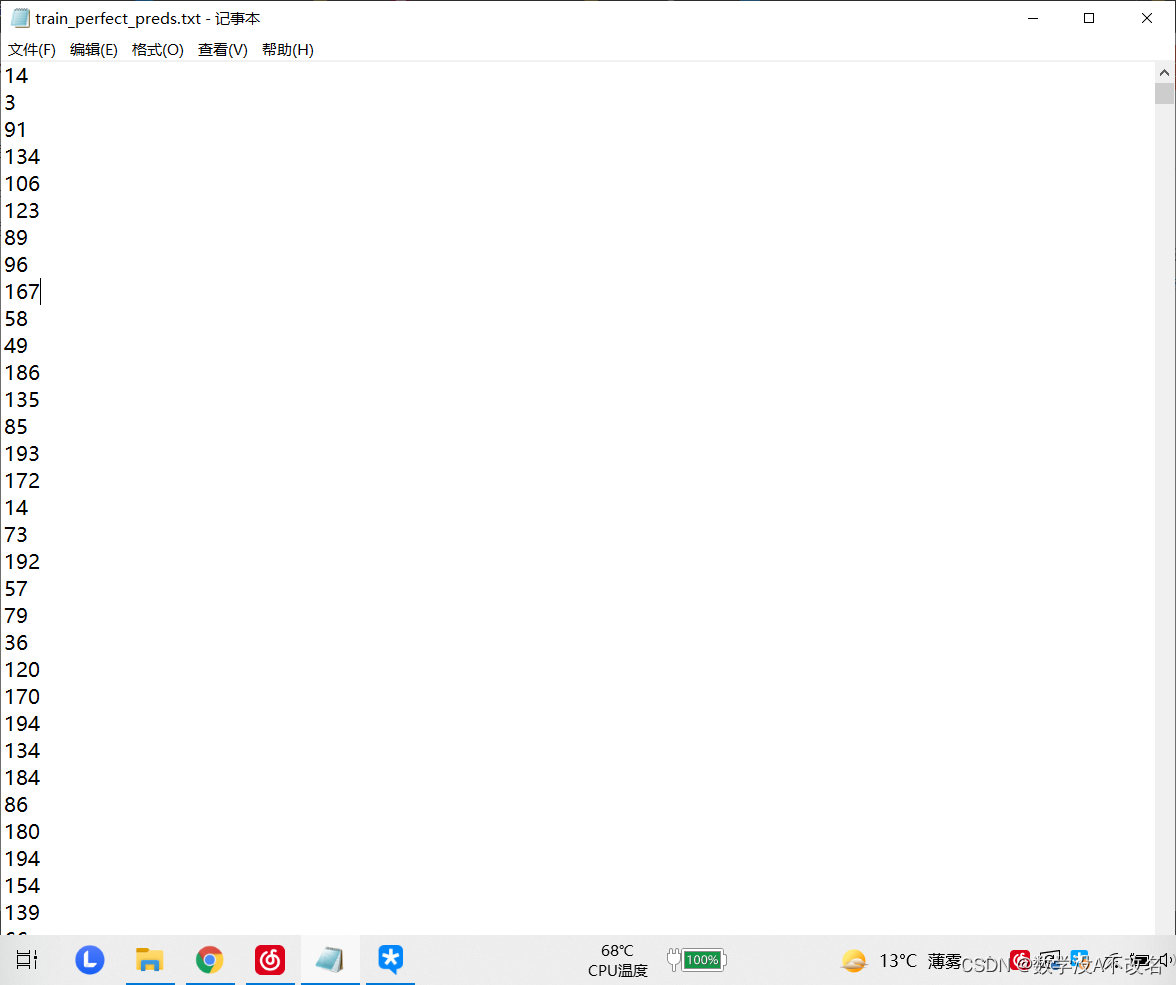
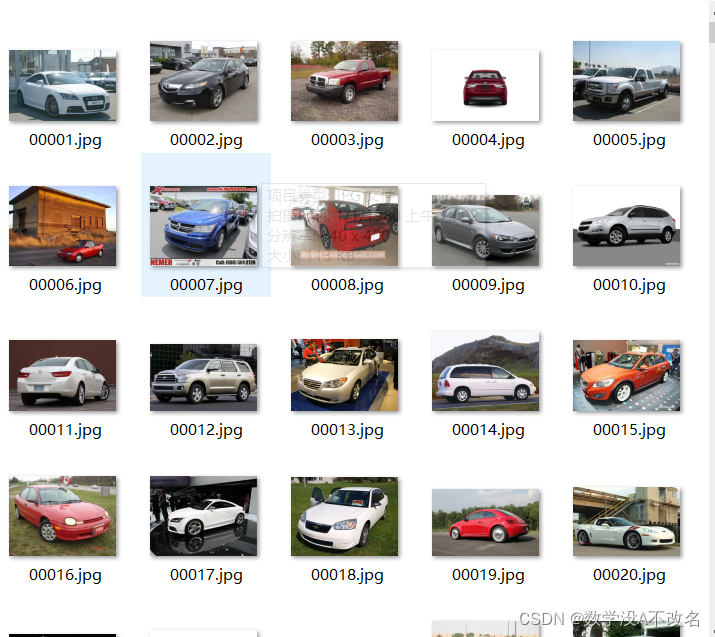
现在需要根据标签将同类的文件放入同一个文件夹中,如图为分类完成的结果,总览和第一类文件夹: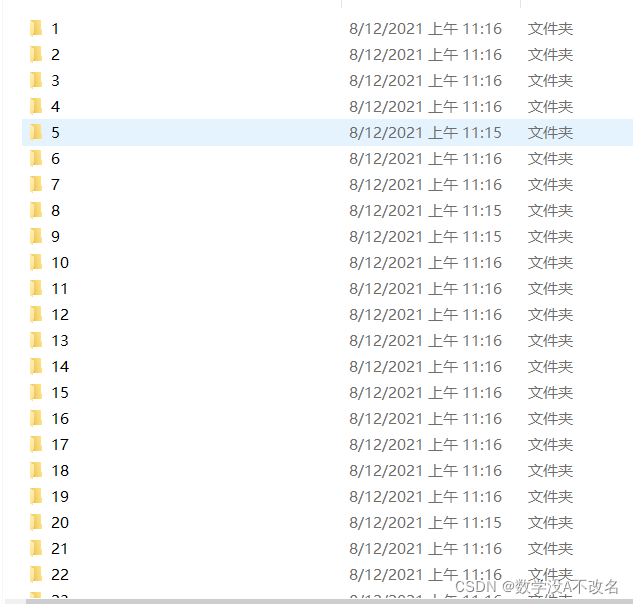
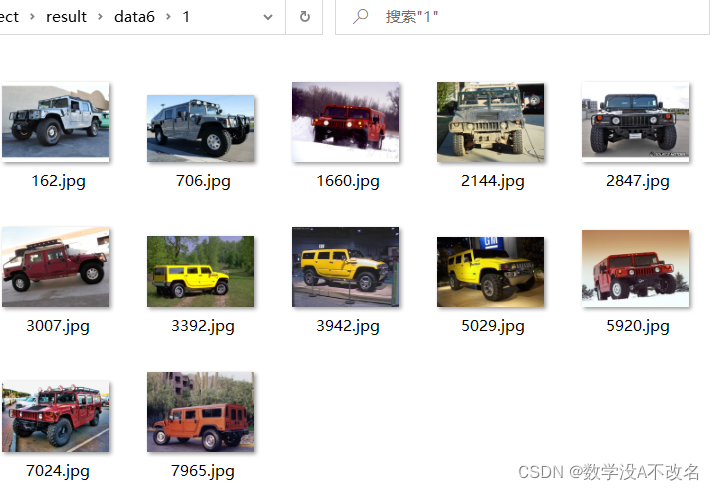
其中过滤了图片宽和高小于400的图片,如果不需要将if判断部分注释掉即可,代码如下,
import shutil
import cv2# 读入分类的标签txt文件
label_file = open("E:\\pythonProject\\data\\train_perfect_preds.txt", 'r')
# 原始文件的根目录
input_path = "E:\\pythonProject\\data\\cars_train"
# 保存文件的根目录
output_path = "E:\\pythonProject\\result"
# 标签数组
#lables = ["Classical", "Rock", "Symphony", "Country"]
paths = ['/fdfs_data/data/', '/fdfs_data/data1/']trainpath = '/home/*/*/SR/raisr/test'file_name = "E:\pythonProject\data\cars_train"
def get_img_file(file_name):imagelist = []for parent, dirnames, filenames in os.walk(file_name):for filename in filenames:if filename.lower().endswith(('.bmp', '.dib', '.png', '.jpg', '.jpeg', '.pbm', '.pgm', '.ppm', '.tif', '.tiff')):imagelist.append(os.path.join(parent, filename))return imagelistlist = get_img_file(file_name) #图片的路径数组
#print(list)
# 一行行读入标签文件
data = label_file.readlines()
#data1 = pic_file.readlines()
# 计数用
i = 0for line in data:# 通过空格拆分成数组str1 = line.split(" ")# 第一个是文件名#file_name = str1[0]# 第二个是标签类别,并去除最后的换行字符#file_label = str1[1].strip()file_label = str1[0].strip()# 原始文件的路径str2=file_label.zfill(5)#old_file_path = os.path.join(input_path, str2)old_file_path = list[i]# 新文件路径new_file_path = ""# 如果文件名中有test字符,将其保存至test文件夹下的对应标签文件夹中#if "test" in file_name:new_file_path = os.path.join(output_path, "data6", file_label)# 如果文件名中有 train 字符,将其保存至train文件夹下的对应标签文件夹中#elif "train" in file_name:#new_file_path = os.path.join(output_path, "train", lables[int(file_label) - 1])# 如果路径不存在,则创建if not os.path.exists(new_file_path):print("路径 " + new_file_path + " 不存在,正在创建......")os.makedirs(new_file_path)# 新文件位置new_file_path = os.path.join(new_file_path, str(i))img = cv2.imread(old_file_path)sp = img.shapeheight = sp[0]width = sp[1]channel = sp[2]# 复制文件if height>400 and width >400:print("" + str(i) + "\t正在将 " + old_file_path + " 复制到 " + new_file_path)shutil.copyfile(old_file_path, new_file_path+'.jpg')else:print(old_file_path,sp)i = i + 1
# 完成提示
print("完成")```python
在这里插入代码片
文件夹不需要新建,下面的data6即是分类后的文件名,新建一个result空文件夹即可。
new_file_path = os.path.join(output_path, “data6”, file_label)
另外,这里的 old_file_path 已经包含了图片后缀(是根据你原文件的图片后置j给的,我这里都是jpg类型),然后默认分类完的图片类别为.jpg后缀,可自行尝试修改。
shutil.copyfile(old_file_path, new_file_path+’.jpg’)
大概思路就是定义一个读取图片文件名的方法,然后将所有待分类的图片名全存进list[],识别类别,如果不存在就新建一个以该类别为文件名的new_file_path,然后就是复制文件到该目录下了,整个在list[]循环下进行,大概就是这样了。
第一次想写点可能有用的东西,从前写的博客都是因为课程作业需要,水的一,希望这篇博客能对你能有亿点点帮助。最后说几句题外话,最近觉得Python还是挺有意思的,跟着某个博主整了个类似自动化办公的区域识别然后进行一些简单操作的小脚本,又听说了AI斗地主,也想玩玩,但感觉配置可能有些困难,轻薄本CPU训练效率也会比GPU低很多,加之C盘快炸了,不禁感概自己都装了些什么玩意儿。
另外有部分代码借鉴了下文,因为本人是懒狗,所以代码中有些注释的或非注释的与本文目的无关的内容就不要纠结了。
https://cxhit.blog.csdn.net/article/details/115391008