引用和指针的概念及区别
- 1. 引用及指针概念
- 1.1 指针概念
- 1.2 引用概念
- 2. 引用与指针的区别
1. 引用及指针概念
如果熟悉指针和引用的使用,应该能感觉到指针和引用在很多场景使用起来还是有很大的相似性的,尽管它们在语法层面上是俩个完全不同的概念。
那么这二者之间到底具有怎样的相似性以及又有什么样的区别呢?这篇文章就和大家一起来探讨一下这俩个问题。
在谈这个话题之前我们先简单回顾一下指针和引用的概念:
1.1 指针概念
在计算机科学中,指针(Pointer)是编程语言中的一个对象,利用地址,它的值直接指向(points to)存在电脑存储器中另一个地方的值。由于通过地址能找到所需的变量单元,可以说,地址指向该变量单元。因此,将地址形象化的称为“指针”。 意思是通过它能找到以它为地址的内存单元。
也就是说,“指针”是一个地址,变量的指针就是变量的地址。而我们通常所谈的“指针”,其实是 “指针变量”,它的概念是存放着地址的变量。“指针”和“指针变量”实际上是俩个不同的概念,但我们在日常的学习和使用中,经常把“指针变量”简称为“指针”,因此,作为使用者的我们,一定要能够在心中区分这俩个不同的概念,以免混淆。
而我们这里所谈的指针,正是指针变量,用来存放地址, 地址唯一标识一块内存空间。也就是说,指针(变量)保存着其所指向对象的地址。因此,对指针的操作,也可以联系到其所指向的变量。如以下代码:
int main()
{int a = 10;int *pa = &a; //定义指针变量pa,指向整形变量a*pa = 20; //通过指针的解引用操作修改a的值cout << "a = " << a << endl;return 0;
}
1.2 引用概念
通过上述对指针概念的回顾我们可以知道,指针其实是一个变量,既然是变量,就会占据一定的内存空间。 而现在要谈的引用,并不是定义一个新的变量,而是给一个已经存在的变量取一个“别名”, 编译器不会为引用开辟内存空间,它和它所引用的变量共用一块内存空间。
比如说,我的一位高中同学有一个外号叫“二狗”,我们一般不喊的真名,只需要喊他“二狗”,他就知道我们是在叫他,并给予我们回应。

也就是说,引用其实就是其所指向的实体本身, 就像“二狗”就是我那个同学本人,只不过是另一个名字(外号)罢了。
定义引用类型的方式与定义指针变量的方式类似,一般形式为:
类型 &引用变量名(对象名) = 引用实体;
int main()
{int a = 10;int &ra = a; //定义引用类型ra = 20; //通过引用修改a的值cout << "a = " << a << endl; //20cout << "ra = " << ra << endl; //20return 0;
}
2. 引用与指针的区别
通过上述概念回顾,我们初步感受到其实指针和引用在使用上是有一定的相似性的, 比如二者都可以代表其所指向或者所引用的变量,并能够通过指针或者引用来修改他们联系的对象。
甚至有一个结论说出来可能还有读者会感到震惊:
在底层实现上,引用和指针甚至没有任何区别,引用就是指针!
可是口说无凭啊,这篇文章谈的不就是指针和引用的区别吗,看到这才感觉重点要来了,你却说指针和引用是一样的?证据呢?
首先要说一句这并不是在开玩笑,至于原因,大家往下看:
int main()
{int a = 10;int *pa = &a;*pa = 20;int &ra = a;ra = 20;return 0;
}
通过VS2013下的监视窗口,我们来观察一下这段代码的反汇编指令

看到上图,尽管我们可能看不懂汇编代码,但我们却能看出二者在底层实现上的确是没有什么区别的,毕竟一模一样的汇编代码足以说明问题。也就是说,引用的底层其实就是按照指针的方式来实现的,在底层实现上引用其实也是有空间的。
如果觉得仅仅上边一个例子还不足以说明问题,那么大家下去可以自行多加尝试,比如观察分别以引用和指针变量作为形参的函数汇编代码的对比,看看是否依然相同。这个问题这里就不在过多赘述。
但在日常学习和使用中,我们更关心的其实是二者在语法概念上的区别,毕竟我们只是使用者,至于它们在底层究竟是如何实现的,大多数情况下我们并不关心。理解指针和引用在语法概念上的区别, 才是我们着重需要考虑的。
总体来说,指针和引用主要有以下几个方面的不同点:
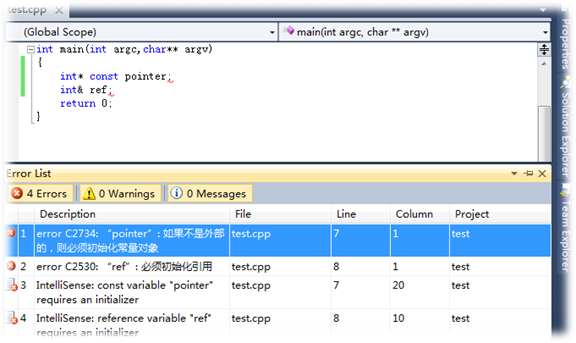
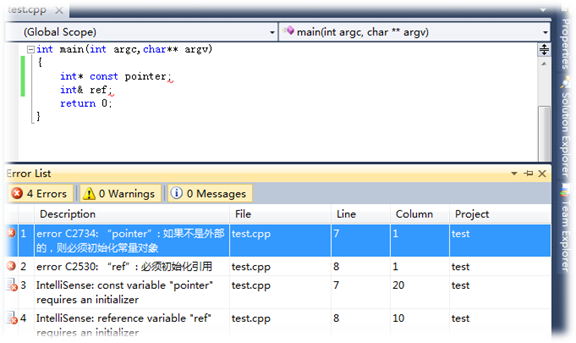
1. 引用在定义时必须初始化,而指针没有要求
int main()
{int a = 10;//int &ra; //会报错,引用在定义时必须同时进行初始化int &ra = a; //正确的定义方式int *p; //定义时可以不初始化return 0;
}
2. 用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
int main()
{int a = 10;int b = 20;int &ra = a;//&ra = b; //会报错,引用一旦定义,不能在引用其他实体//ra = b; //不会报错,但这条语句的意思是将b的值赋给ra(a),并不是引用其他实体int *pa = &a;pa = &b; //正确,修改pa的指向,使其指向变量breturn 0;
}
3. 指针有空值NULL,但引用没有NULL引用这一说
int *p = NULL; //正确,初始化指针变量p为NULL
int &r = NULL; //错误,没有NULL引用
4. 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
int main()
{char c = 'a';char *pc = &c;char &rc = c;cout << "sizeof(pc) = " << sizeof(pc) << endl; //4cout << "sizeof(rc) = " << sizeof(rc) << endl; //1return 0;
}
5. 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
int main()
{int arr[] = { 1, 3, 5, 7 };int *p = &arr[0];p++;//指向下一个元素cout << "*p = " << *p << endl; //3int &r = arr[0];r++; //其引用的实体自加1,即arr[0] = arr[0] + 1cout << "r = " << r << endl; //2cout << "arr[0] = " << arr[0] << endl; //同上return 0;
}
7. 有多级指针,但是没有多级引用
int main()
{int a = 10;int *pa = &a; //定义一级指针,指向一个同类型变量int **ppa = &pa; //定义二级指针,指向一个一级指针int &ra = a; //定义引用//int &&rra = ra; //错误,没有多级引用return 0;
}
8. 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
int main()
{int a = 10;int b = 20;int *pa = &a;*pa = 30; //通过解引用操作修改a的值cout << "a = " << *pa << endl; //通过解引用打印a的值(30)int &rb = b;rb = 40; //通过引用直接修改b的值cout << "b = " << rb << endl; //通过引用直接打印b值(40)return 0;
}
9. 引用比指针使用起来相对更安全 :
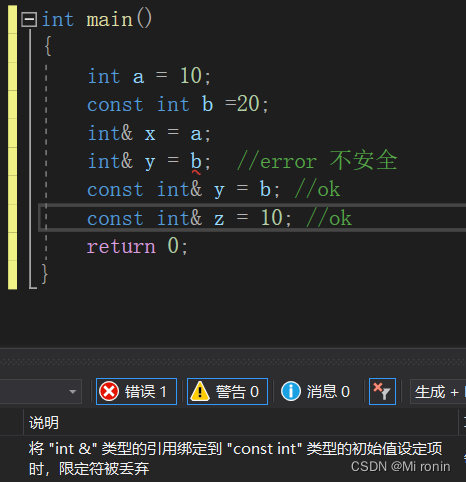
比如使用指针可能会出现野指针的情况,如果操作失误,可能会访问不合法的空间,造成我们不想看到的后果,但引用不会。并且引用一旦定义, 即与当前所引用实体绑定,不能再引用其他实体, 这个规则一定程度上也使得引用在使用时更加安全。
没有提到的相关内容欢迎大家补充交流!