引用和指针的区别:







C++的引用(Reference)
1.定义引用就是给某个变量起别名,对引用的操作和对该变量操作完全相同。
int a = 10;
int& b = a;//b就是a的别名
b++;
cout << a << endl;//11
2 常引用
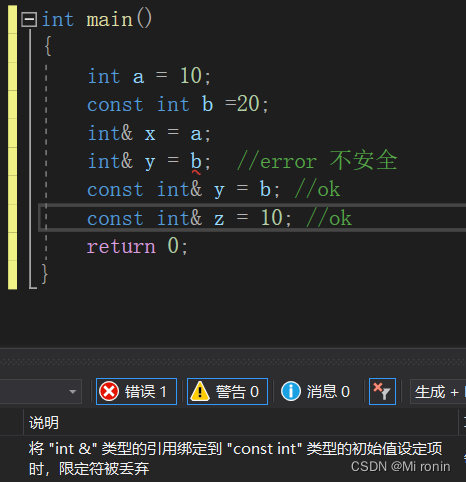
1)定义引用时加const修饰,即为常引用,不能通过常引用修改引用的目标。
eg:
int a = 100;
const int& b = a;//b是a常引用
a = 200;//ok
b = 200;//error
============
2)普通的引用只能引用左值,常引用也叫作万能引用,既能够引用左值也能够引用右值。
int& r = 100;//error
const int& rc = 100;//ok
3)关于左值和右值
左值:可以放在赋值运算符左侧,可以被修改,可以被取地址
int i;
i = 100;
++i;//101
int* pi = &i;
--》普通的变量都是左值
--》前缀表达式值是左值
--》赋值表达式值是左值
(++i) = 200;//ok
cout << i << endl;//200
(i = 300) = 400;//ok
cout << i << endl;//400
右值:只能放在赋值运算符右侧,不可被修改,不可被取地址
常见的右值:
--》字面值常量:10 = i; ++10; int* p = &10;
--》大部分的表达式值都是右值:
int a = 10;
int b = 20;
(a+b) = 30;//error
int i = 1;
cout << i++ << endl;//1
cout << i << endl;//2
--》函数的返回值
int foo(void){
int a=100;
return a;//编译会定义一个临时变量"temp"保存a
}
int main(void){
int res = foo();//函数调用结果就是"temp"
foo() = 200;//error
++foo();//error
int* p = &foo();//error
}
3 引用型函数的参数
1)将引用用于函数的参数,可以修改实参变量的值,可以减小函数调用的开销,避免实参到形参值的复制。
2)引用型参数有可能意外修改实参变量的值,如果不希望修改实参本身,可以将形参定义为常引用,提高传参效率的同时可以接受常量型的实参。
4 引用型函数返回值
1)可以将函数的返回类型声明为引用,避免函数返回值所带来的内存开销,如果一个函数返回类型被声明为引用,那么该函数的返回值就是一个左值。
2)为了避免在函数外部修改 引用的目标变量,可以为该引用附加常属性。
3)不要从函数中返回局部变量的引用,因为所引用的内存会在函数返回以后被释放。
4)可以在函数中返回成员变量,静态变量、全局变量的引用
5 引用与指针(笔试题)
1)引用本质就是指针,但是建议使用引用而不是指针。
double d = 1.234;
-->double& rd = d;//rd
-->double* const pd = &d;//*pd
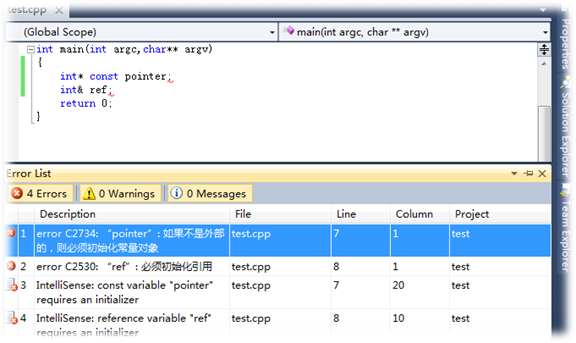
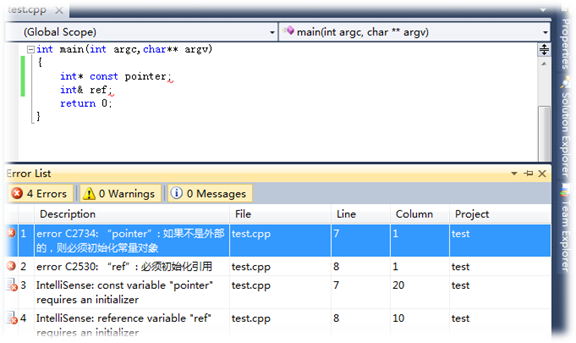
2)指针可以不初始化,其指向目标可以修改(除指针常量),而引用定义时必须初始化,且一旦初始化引用目标不能修改。
int a,b;
int* p;//ok
p = &a;
p = &b;
int& r;//error
int& r = a;//r引用变量a
r = b;//把b的值赋值给a
3)可以定义指针的指针(二级指针),但是不能定义引用的指针
int a = 10;
int* p = &a;
int** pp = &p;//ok
int& r = a;
int& *pr = &r;//error
4)可以定义指针的引用,但是不能定义引用的引用
int a = 10;
int* p = &a;
int*& rp = p;//ok
int& r = a;
int&& rr = r;//error,int&&在C++11叫右值引用
5)可以定义指针数组,但是不能定义引用数组
int a=10,b=20,c=30;
int *arr[3]={&a,&b,&c};//ok
int& rarr[3]={a,b,c};//error
6)可以定义数组引用
int arr[3]={1,2,3};
int (&r)[3] = arr;//r就是数组的别名
arr[0] <==> r[0]
7)和函数指针一样,可以定义函数的引用,其语法基本一致
void func(int a,int b){
cout << a << b << endl;
}
int main(void){
void (*pfunc)(int,int) = func;
pfunc(10,20);//10 20
void (&rfunc)(int,int) = func;
rfunc(10,20);//10 20
}