目录
- 引用
- 一.引入</font>
- 二.C++中较为麻烦的运算符</font>
- 三.引用的定义</font>
- 四.引用的特点
- 五.对比指针与引用
- 六.引用与指针的区别(重点)
- 1.语法层面的区别
- 2.汇编层面的区别
- 七.引用的其他使用
引用
一.引入
在生活中,我们可能也会给一些同学起外号,以“张磊”同学为例,我们可以叫他“张三石”,当我们叫到这个外号的时候就会自然而然的想到“张磊”同学,”张三石”就是张磊的别名,而引用也可以这样简单理解:在语法层面上,引用就是取别名。
二.C++中较为麻烦的运算符
C++中的 * 和 & 有多重含义,在不同的使用条件下有不同的意思:
*
int *p = &a; /1.指针
a = a * b; /2.乘法
*p = 100; /3.指向
&
int c = a&b; /1.位运算 转换为二进制
int *p = &a; /2.取地址
int a = 100;
int & ar = a; /3.引用
三.引用的定义
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它与引用的变量共用同一块内存空间。
格式如下:
类型 & 引用变量名(对象名) = 引用实体
注意这里的空格是可选的,即
- &符号与前后均可以有一个空格;如下:int & ra=a;
- &符号与类型挨着,如下:int& ra=a;
- &符号与引用名称挨着,如下:int &ra=a;
int main()
{
int a =100; \\定义变量名
int b = a;\\将a的值赋给变量
int &c = a;\\引用 将c作为a的别名 c11中成为左值引用
return 0;
}
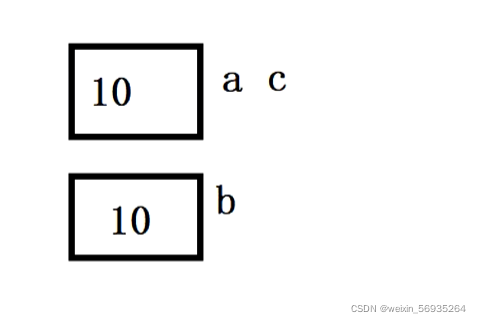
在这里就是相当于一个实体取了两个名字分别为a和c,并且在这个空间中不开辟新的空间。
四.引用的特点
- 定义引用时必须给初始化
- 没有空引用
- 没有所谓的二级引用
- 一个变量可以有多个引用(就相当于一个变量有好几个别名,这是可以的)
说明:
int main()
{
int a = 10;
int& b = a;
int& x;
int& y = NULL;
int&& c = a;
}

总而言之:
引用本身是一个变量,但是这个变量又仅仅是另外一个变量一个别名,它不占用内存空间,它不是指针哦!仅仅是一个别名!
五.对比指针与引用
我们以交换函数为例
使用指针交换两个整型值:
int my _swap (int*ap, int*bp)
{assert(ap != NULL && bp != NULL);int tmp = *ap;*ap = *bp;*bp = *ap;
}
int main()
{int x = 10, y = 20;my_swap{&x,&y);cout<< "x = " << x << " y = " << y << endl;return 0;
}
使用引用交换两个指针:
void my_swap (int& a,int& b)
{int tmp = a;a = b;b = tmp;
}
int main ()
{int x = 10, y = 20;my_swap(x,y) ;cout << " x = " << x<< " y = " << y << endl;return 0;
}
形参为指针时:第一句话一定要断言,必须判断空不空;并且在使用指针的时候 我们需要注意:是否为 野指针, 空指针 ,失效指针。
当我们使用引用时,不存在NULL引用,不需要判空,比指针更加安全
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
所以:能不使用指针就尽量不要使用指针!
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
六.引用与指针的区别(重点)
1.语法层面的区别
- 从语法规则上讲,指针变量存储某个实例(变量或对象)的地址;
引用是某个实例的别名。 - 程序为指针变量分配内存区域;而不为引用分配内存区域。
int main()
{int a = 10;int* ip = &a;int& b = a; \\b是a的别名 并没有分配新的空间
}
- 解引用是指针使用时要在前加“*”;引用可以直接使用。
int main()
{int a = 10;int* ip = &a;int& b = a; *ip = 100;//对于指针使用加“*”b = 200; //引用不需要“*”}
- 指针变量的值可以发生改变,存储不同实例的地址;
引用在定义时就被初始化,之后无法改变(不能是其他实例的引用)。
int main()
{int a = 10,b = 20;int* ip = &a;ip = &b ;int& c = a;c = b; //b的值给c实则是把b的值给a,将a的值改为20
}
- 指针变量的值可以为空(NULL,nullptr);没有空引用。
- 指针变量作为形参时需要测试它的合法性(判空NULL);
引用不需要判空。 - 对指针变量使用"sizeof"得到的是指针变量的大小;
对引用变量使用"sizeof"得到的是变量的大小。
int main()
{double dx = 10;double* dp = &dx;double& a = dx; printf("sizeof(dp):%d\n", sizeof(dp));printf("sizeof(a):%d", sizeof(a));
}
运行结果:

-
理论上指针的级数没有限制;但引用只有一级。
即不存在引用的引用,但可以有指针的指针。 -
++引用与++指针的效果不一样。
例如就++操作而言:
int main()
(int ar[5] = { 1,2,3,4,5 };int* ip = ar; //数组首元素地址int& b = ar[O]; //数组首元素的别名叫b++ip; //由0下标的地址指向1下标的地址++b; //由0下标指向1下标
}
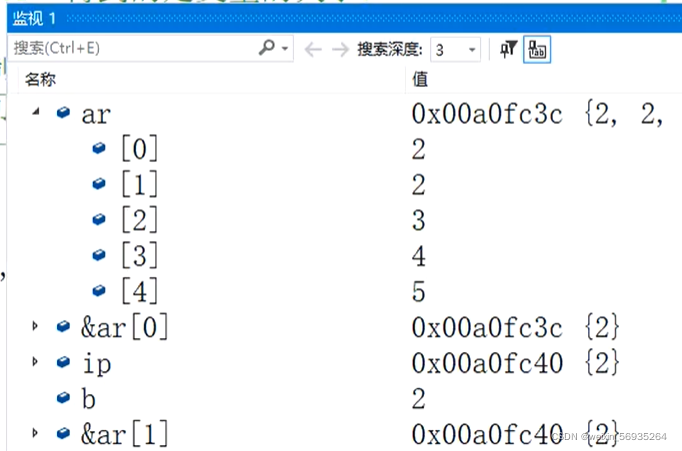
- 对引用的操作直接反应到所引用的实体(变量或对象)。
对指针变量的操作,会使指针变量指向下一个实体(变量或对象)的地址;而不是改变所指实体(变量或对象)的内容。
int main()
(int ar[5] = { 1,2,3,4,5 };int* ip = ar; //数组首元素地址int& b = ar[O]; //数组首元素的别名叫b++(*ip); //值由1>>2 (*ip)++; //所有表达式结束后 进行++ //有括号 先取ip的值与*结合 然后++为所指之物的++int x = *ip++;//没有括号 先将ip的值取出 与*结合 把所指之物取出(此时已与*结合完) 然后将ip取出进行++ ++后的值回写给ip 将值存储到x中//通过()提高了优先级
}
-
不可以对函数中的局部变量或对象以引用或指针方式返回。
当变量的生存期不受函数的影响时就可以返回地址
2.汇编层面的区别
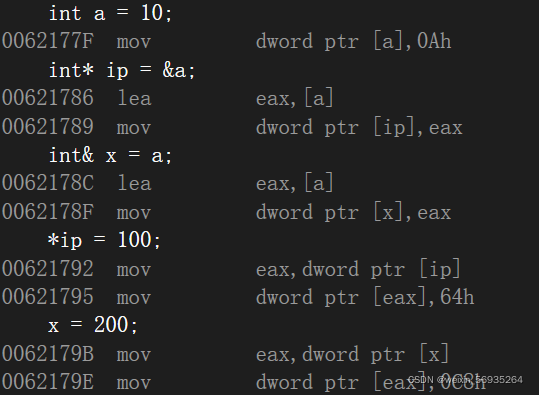
汇编层面来讲引用就是一个指针,但是引用并不是一个普通的指针是指针的语法槽,也可以看作是常性的指针 。
int main()
{int a = 10;int* ip = &a;int& x = a;*ip = 100;x = 200;
}
七.引用的其他使用
- 常引用:
常引用实际上是一种万能引用既可以引用普通变量 ,常量,也可以引用字面常量。
(1)引用普通变量
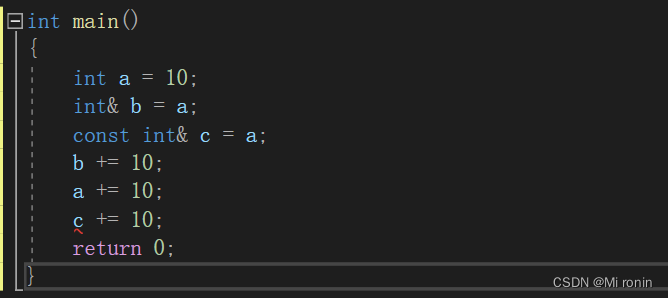
int main()
{int a = 10;int & b = a;const int& c = a;b += 10;a += 10;c += 10;return 0;
}
对于这块报错问题:是因为c是不可修改的
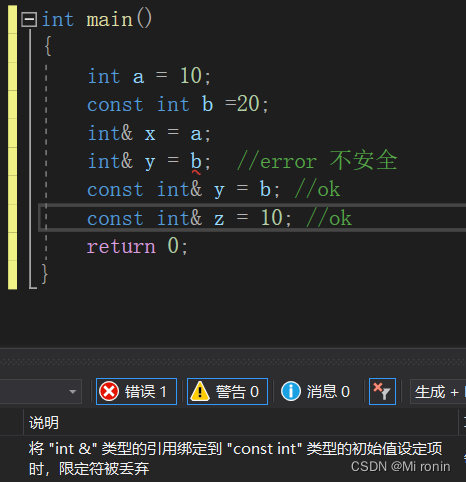
(2)引用常量
int main()
{int a = 10;const int b =20;int& x = a;int& y = b; //error 不安全const int& y = b; //okconst int& z =10; //okreturn 0;
}
(3)引用字面常量
引用字面常量时,分两步走,首先定义一个临时量 去引用临时量 不是引用真实的字面常量10。
int main()
{int a = 10;const int& z =10; //ok//int tmp =10;//const int &z = tmp;return 0;
}
- 数组引用
在引用数组时,必须知道数组的大小
int main()
{int a = 10;int b = 10;int ar[5] = { 1,2,3,4,5 };int& x = ar[0]; //okint(&x)[5] = ar; //ok 没有[5]无法编译通过return 0;
}
- 指针引用
引用既然就是一个变量,那我同样也可以给指针变量取一个别名
int main()
{int a = 100;int *p = &a;int * &rp = p;cout << a << endl;cout << *p << endl;cout << *rp << endl; //这里为什么要将*放在前面,因为p的类型是 int * 作为一个整体哦!!cout << p << endl;cout << rp << endl;getchar();return 0;
}
/*
100
100
100
012FF84C
012FF84C
*/
我们发现这里的指针变量p和它的引用(别名)rp是完全一样的。但是由于引用的目的跟指针的目的是类似的,所以一般不需要对指针再起别名了。