作者:RainMan
链接:https://www.zhihu.com/question/37608201/answer/545635054
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
引用是C++引入的重要机制(C语言没有引用),它使原来在C中必须用指针来实现的功能有了另一种实现的选择,在书写形式上更为简洁。那么引用的本质是什么,它与指针又有什么关系呢?
1.引用的底层实现方式
引用被称为变量的别名,它不能脱离被引用对象独立存在,这是在高级语言层面的概念和理解,并未解释引用的实现方式。常见错误说法是“引用”自身不是一个变量,甚至编译器可以不以引用分配空间。
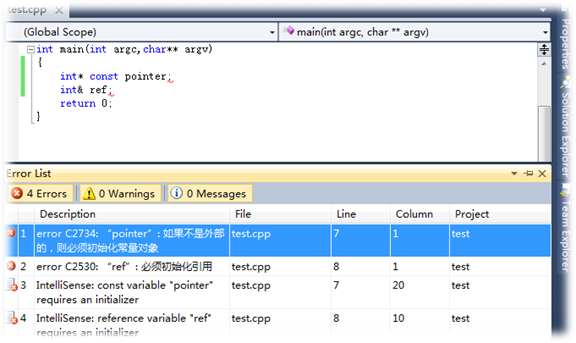
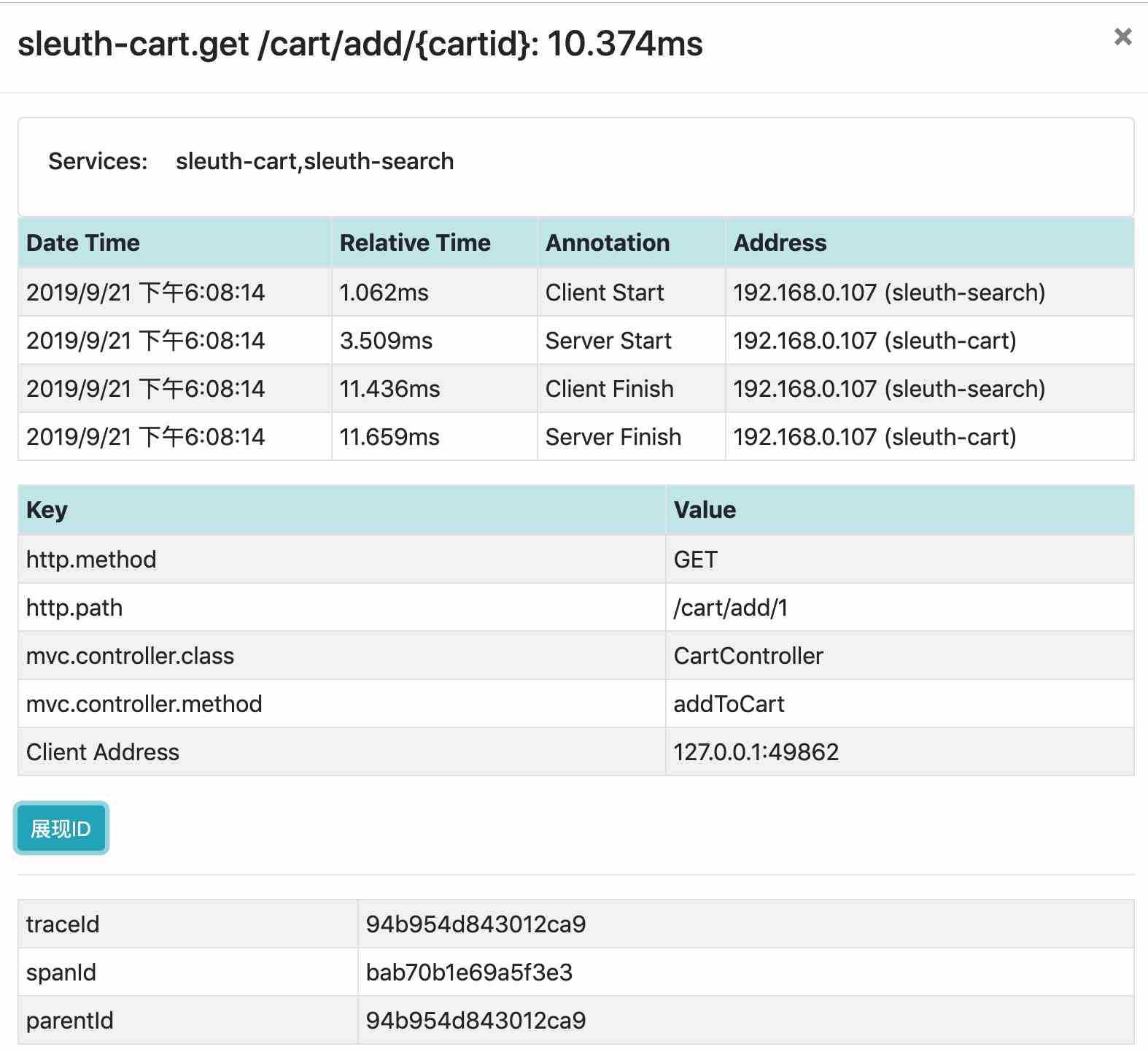
实际上,引用本身是一个变量,只不过这个变量的定义和使用与普通变量有显著的不同。为了解引用变量底层实现机制,考查如下代码:
int i=5;
int &ri=i;
ri=8;在Visual Studio 2017环境的debug模式调试代码,反汇编查看源码对应的汇编代码的步骤是:调试->窗口->反汇编,即可得到如下原码对应的汇编代码:
int i=5;
00A013DE mov dword ptr [i],5 //将文字常量5送入变量i
int &ri=i;
00A013E5 lea eax,[i] //将变量i的地址送入寄存器eax
00A013E8 mov dword ptr [ri],eax //将寄存器的内容(也就是变量i的地址)送入变量ri
ri=8;
00A013EB mov eax,dword ptr [ri] //将变量ri的值送入寄存器eax
00A013EE mov dword ptr [eax],8 //将数值8送入以eax的内容为地址的单元中
return 0;
00A013F4 xor eax,eax
考查以上代码,在汇编代码中,ri的数据类型为dword,也就是说,ri要在内存中占据4个字节的位置。所以,ri的确是一个变量,它存放的是被引用对象的地址。由于通常情况下,地址是由指针变量存放的,那么,指针变量和引用变量有什么区别呢?使用指针常量实现上面的代码功能。考查如下代码:
int i=5;
int* const pi=&i;
*pi=8;按照相同的方式,在VS2017中得都如下汇编代码:
int i=5;
011F13DE mov dword ptr [i],5
int * const pi=&i;
011F13E5 lea eax,[i]
011F13E8 mov dword ptr [pi],eax
*pi=8;
011F13EB mov eax,dword ptr [pi]
011F13EE mov dword ptr [eax],8
观察以上代码可以看出:
(1)除了pi与ri变量名不同,所得汇编代码与第一段所对应的汇编代码完全一样。所以,引用变量在功能上等于一个指针常量,即一旦指向某一个单元就不能在指向别处。
(2)在底层,引用变量由指针按照指针常量的方式实现。
2.高级语言层面引用与指针常量的关系
1.引用和指针,在内存中都是占用4个字节(32bits系统中)的存储空间。指针和引用存放的都是被引用对象的地址,都必须在定义的同时进行初始化。
2.指针常量本身(以p为例)允许寻址,即&p返回指针常量(常变量)本身的地址,被引用对象用*p表示;引用变量本身(以r为例)不允许寻址,&r返回的是被引用对象的地址,而不是变量r的地址(r的地址由编译器掌握,程序员无法直接对它进行存取),被引用对象直接用r表示。
3.凡是使用了引用变量的代码,都可以转换成使用指针常量的对应形式的代码,只不过书写形式上要繁琐一些。反过来,由于对引用变量使用方式上的限制,使用指针常量能够实现的功能,却不一定能够用引用来实现。
例如,下面的代码是合法的:
int i=5,j=6;
int* const array[]={&i,&j};而如下代码是非法的:
int i=5,j=6;
int& array[]={i,j};也就是说,数组元素允许是指针常量,却不允许是引用。C++语言机制如此规定,原因是避免C++语法变得过于晦涩。假如定义一个“引用的数组”,那么array[0]=8;这条语句该如何理解?是将数组元素array[0]本身的值变成8呢,还是将array[0]所引用的对象的值变成8呢?对于程序员来说,这种解释上的二义性对正确编程是一种严重的威胁,毕竟程序员在编写程序的时候,不可能每次使用数组时都要回过头去检查数组的原始定义。
即得出两个不同:引用只能在定义时被初始化一次,之后不可变,但是指针可变;引用没有 const,指针有 const。
4.一些其他不同:
引用使用时无需解引用(*),指针需要解引用;
“sizeof 引用”得到的是所指向的变量(对象)的大小,而“sizeof 指针”得到的是指针本身(所指向的变量或对象的地址)的大小;
引用不能为空,指针可以为空;
指针和引用的自增(++)运算意义不一样;引用自增被引用对象的值,指针自增内存地址。
https://blog.csdn.net/tianguiyuyu/article/details/102941951
c++中引用的本质
c++中引用就是一个常指针,其也占用内存空间。
1)引用在C++中的内部实现是一个常指针
Type& name 《-》Type* const name
2)C++编译器在编译过程中使用常指针作为引用的内部实现,因此引用所占用的空间大小与指针相同。
3)从使用的角度,引用会让人误会其只是一个别名,没有自己的存储空间。这是C++为了实用性而做出的细节隐藏
具体点:如下:
1)引用在实现上,只不过是把:间接赋值成立的三个条件的后两步和二为一
(简介赋值的三个条件: 1定义两个变量 (一个实参一个形参) 2建立关联 实参取地址传给形参 3 *p形参去间接的修改实参的值)
//当实参传给形参引用的时候,只不过是c++编译器帮我们程序员手工取了一个实参地址,传给了形参引用(常量指针)
如下图所示,c++编译器会把左边的代码翻译成右边的。

2)当我们使用引用语法的时,我们不去关心编译器引用是怎么做的
当我们分析奇怪的语法现象的时,我们才去考虑c++编译器是怎么做的。
详细点就是看下面的代码:
#include <iostream>using namespace std;//1 第一点 单独定义的引用时,必须初始化;说明很像一个常量void main1(){//const int c1 = 10;int a = 10;int& b = a; //b很想一个常量printf("&a:%d \n", &a);printf("&b:%d \n", &b); //===> a 和 b就是同一块内存空间的门牌号,a和b的地址是一样的,说明引用b就是a的别名cout << "hello..." << endl;system("pause");return;}//2 普通引用有自己的空间吗? 有struct Teacher{char name[64]; //64int age; //4int& a; //4 0 //很像指针 所占的内存空间大小int& b; //4 0};//3 引用的本质void modifyA(int& a1){a1 = 100;}void modifyA2(int* const a1){*a1 = 200; //*实参的地址 ,去间接的修改实参的值}void main(){int a = 10;//1modifyA(a); //指向这个函数调用的时候,我们程序员不需要取a的地址printf("a:%d \n", a); //输出100//a = 10;modifyA2(&a); //如果是指针 需要我们程序员手工的取实参的地址printf("a:%d \n", a); //输出200printf("sizeof(Teacher):%d \n", sizeof(Teacher)); //输出76,说明普通引用有自己的内存空间system("pause");}void modifyA3(int* p){*p = 200; //*p 3*p形参去间接修改实参的值}//间接赋值void main11(){int a = 10;int* p = NULL; //间接赋值成立的三个条件 1 定义两个变量p = &a;*p = 100;{*p = 200;}modifyA3(&a); //2 建立关联}// 123 写在一块// 12 3//1 23