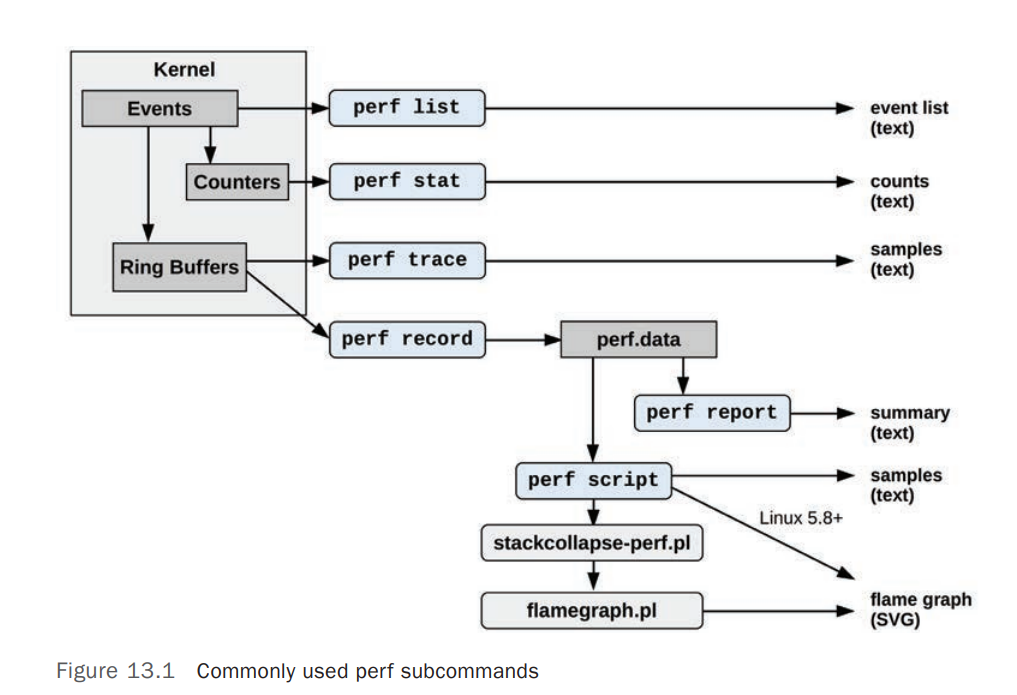
从2.6.31内核开始,Linux内核自带了一个性能分析工具perf,能够进行函数级与指令级的热点查找。通过它,应用程序可以利用 PMU,tracepoint 和内核中的特殊计数器来进行性能统计。它不但可以分析指定应用程序的性能问题 (per thread),也可以用来分析内核的性能问题,当然也可以同时分析应用代码和内核,从而全面理解应用程序中的性能瓶颈。
Perf是内置于Linux内核源码树中的性能剖析(profiling)工具。
它基于事件采样原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性能指标的性能剖析。
常用于性能瓶颈的查找与热点代码的定位。
CPU周期(cpu-cycles)是默认的性能事件,所谓的CPU周期是指CPU所能识别的最小时间单元,通常为亿分之几秒,
是CPU执行最简单的指令时所需要的时间,例如读取寄存器中的内容,也叫做clock tick。
Perf是一个包含22种子工具的工具集,以下是最常用的5种:
perf-list
perf-stat
perf-top
perf-record
perf-report
perf-list
Perf-list用来查看perf所支持的性能事件,有软件的也有硬件的。
List all symbolic event types.
perf list [hw | sw | cache | tracepoint | event_glob]
(1) 性能事件的分布
hw:Hardware event,9个
sw:Software event,9个
cache:Hardware cache event,26个
tracepoint:Tracepoint event,775个
sw实际上是内核的计数器,与硬件无关。
hw和cache是CPU架构相关的,依赖于具体硬件。
tracepoint是基于内核的ftrace,主线2.6.3x以上的内核版本才支持。
(2) 指定性能事件(以它的属性)
-e <event> : u // userspace
-e <event> : k // kernel
-e <event> : h // hypervisor
-e <event> : G // guest counting (in KVM guests)
-e <event> : H // host counting (not in KVM guests)
(3) 使用例子
显示内核和模块中,消耗最多CPU周期的函数:
# perf top -e cycles:k
显示分配高速缓存最多的函数:
# perf top -e kmem:kmem_cache_alloc
perf-top
对于一个指定的性能事件(默认是CPU周期),显示消耗最多的函数或指令。
System profiling tool.
Generates and displays a performance counter profile in real time.
perf top [-e <EVENT> | --event=EVENT] [<options>]
perf top主要用于实时分析各个函数在某个性能事件上的热度,能够快速的定位热点函数,包括应用程序函数、
模块函数与内核函数,甚至能够定位到热点指令。默认的性能事件为cpu cycles。
(1) 输出格式
# perf top
[plain] view plain copy ![]()
![]()
- Samples: 1M of event 'cycles', Event count (approx.): 73891391490
- 5.44% perf [.] 0x0000000000023256
- 4.86% [kernel] [k] _spin_lock
- 2.43% [kernel] [k] _spin_lock_bh
- 2.29% [kernel] [k] _spin_lock_irqsave
- 1.77% [kernel] [k] __d_lookup
- 1.55% libc-2.12.so [.] __strcmp_sse42
- 1.43% nginx [.] ngx_vslprintf
- 1.37% [kernel] [k] tcp_poll
第一列:符号引发的性能事件的比例,默认指占用的cpu周期比例。
第二列:符号所在的DSO(Dynamic Shared Object),可以是应用程序、内核、动态链接库、模块。
第三列:DSO的类型。[.]表示此符号属于用户态的ELF文件,包括可执行文件与动态链接库,[k]表述此符号属于内核或模块。
第四列:符号名。有些符号不能解析为函数名,只能用地址表示。
(2) 常用交互命令
h:显示帮助
UP/DOWN/PGUP/PGDN/SPACE:上下和翻页。
a:annotate current symbol,注解当前符号。能够给出汇编语言的注解,给出各条指令的采样率。
d:过滤掉所有不属于此DSO的符号。非常方便查看同一类别的符号。
P:将当前信息保存到perf.hist.N中。
(3) 常用命令行参数
-e <event>:指明要分析的性能事件。
-p <pid>:Profile events on existing Process ID (comma sperated list). 仅分析目标进程及其创建的线程。
-k <path>:Path to vmlinux. Required for annotation functionality. 带符号表的内核映像所在的路径。
-K:不显示属于内核或模块的符号。
-U:不显示属于用户态程序的符号。
-d <n>:界面的刷新周期,默认为2s,因为perf top默认每2s从mmap的内存区域读取一次性能数据。
-G:得到函数的调用关系图。
perf top -G [fractal],路径概率为相对值,加起来为100%,调用顺序为从下往上。
perf top -G graph,路径概率为绝对值,加起来为该函数的热度。
(4) 使用例子
# perf top // 默认配置
# perf top -G // 得到调用关系图
# perf top -e cycles // 指定性能事件
# perf top -p 23015,32476 // 查看这两个进程的cpu cycles使用情况
# perf top -s comm,pid,symbol // 显示调用symbol的进程名和进程号
# perf top --comms nginx,top // 仅显示属于指定进程的符号
# perf top --symbols kfree // 仅显示指定的符号
perf-stat
用于分析指定程序的性能概况。
Run a command and gather performance counter statistics.
perf stat [-e <EVENT> | --event=EVENT] [-a] <command>
perf stat [-e <EVENT> | --event=EVENT] [-a] - <command> [<options>]
(1) 输出格式
# perf stat ls
[plain] view plain copy ![]()
![]()
- Performance counter stats for 'ls':
- 0.653782 task-clock # 0.691 CPUs utilized
- 0 context-switches # 0.000 K/sec
- 0 CPU-migrations # 0.000 K/sec
- 247 page-faults # 0.378 M/sec
- 1,625,426 cycles # 2.486 GHz
- 1,050,293 stalled-cycles-frontend # 64.62% frontend cycles idle
- 838,781 stalled-cycles-backend # 51.60% backend cycles idle
- 1,055,735 instructions # 0.65 insns per cycle
- # 0.99 stalled cycles per insn
- 210,587 branches # 322.106 M/sec
- 10,809 branch-misses # 5.13% of all branches
- 0.000945883 seconds time elapsed
输出包括ls的执行时间,以及10个性能事件的统计。
task-clock:任务真正占用的处理器时间,单位为ms。CPUs utilized = task-clock / time elapsed,CPU的占用率。
context-switches:上下文的切换次数。
CPU-migrations:处理器迁移次数。Linux为了维持多个处理器的负载均衡,在特定条件下会将某个任务从一个CPU
迁移到另一个CPU。
page-faults:缺页异常的次数。当应用程序请求的页面尚未建立、请求的页面不在内存中,或者请求的页面虽然在内
存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页异常。另外TLB不命中,页面访问权限不匹配
等情况也会触发缺页异常。
cycles:消耗的处理器周期数。如果把被ls使用的cpu cycles看成是一个处理器的,那么它的主频为2.486GHz。
可以用cycles / task-clock算出。
stalled-cycles-frontend:略过。
stalled-cycles-backend:略过。
instructions:执行了多少条指令。IPC为平均每个cpu cycle执行了多少条指令。
branches:遇到的分支指令数。branch-misses是预测错误的分支指令数。
(2) 常用参数
-p:stat events on existing process id (comma separated list). 仅分析目标进程及其创建的线程。
-a:system-wide collection from all CPUs. 从所有CPU上收集性能数据。
-r:repeat command and print average + stddev (max: 100). 重复执行命令求平均。
-C:Count only on the list of CPUs provided (comma separated list), 从指定CPU上收集性能数据。
-v:be more verbose (show counter open errors, etc), 显示更多性能数据。
-n:null run - don't start any counters,只显示任务的执行时间 。
-x SEP:指定输出列的分隔符。
-o file:指定输出文件,--append指定追加模式。
--pre <cmd>:执行目标程序前先执行的程序。
--post <cmd>:执行目标程序后再执行的程序。
(3) 使用例子
执行10次程序,给出标准偏差与期望的比值:
# perf stat -r 10 ls > /dev/null
显示更详细的信息:
# perf stat -v ls > /dev/null
只显示任务执行时间,不显示性能计数器:
# perf stat -n ls > /dev/null
单独给出每个CPU上的信息:
# perf stat -a -A ls > /dev/null
ls命令执行了多少次系统调用:
# perf stat -e syscalls:sys_enter ls
perf-record
收集采样信息,并将其记录在数据文件中。
随后可以通过其它工具(perf-report)对数据文件进行分析,结果类似于perf-top的。
Run a command and record its profile into perf.data.
This command runs a command and gathers a performance counter profile from it, into perf.data,
without displaying anything. This file can then be inspected later on, using perf report.
(1) 常用参数
-e:Select the PMU event.
-a:System-wide collection from all CPUs.
-p:Record events on existing process ID (comma separated list).
-A:Append to the output file to do incremental profiling.
-f:Overwrite existing data file.
-o:Output file name.
-g:Do call-graph (stack chain/backtrace) recording.
-C:Collect samples only on the list of CPUs provided.
(2) 使用例子
记录nginx进程的性能数据:
# perf record -p `pgrep -d ',' nginx`
记录执行ls时的性能数据:
# perf record ls -g
记录执行ls时的系统调用,可以知道哪些系统调用最频繁:
# perf record -e syscalls:sys_enter ls
perf-report
读取perf record创建的数据文件,并给出热点分析结果。
Read perf.data (created by perf record) and display the profile.
This command displays the performance counter profile information recorded via perf record.
(1) 常用参数
-i:Input file name. (default: perf.data)
(2) 使用例子
# perf report -i perf.data.2
More
除了以上5个常用工具外,还有一些适用于较特殊场景的工具, 比如内核锁、slab分配器、调度器,
也支持自定义探测点。
perf-lock
内核锁的性能分析。
Analyze lock events.
perf lock {record | report | script | info}
需要编译选项的支持:CONFIG_LOCKDEP、CONFIG_LOCK_STAT。
CONFIG_LOCKDEP defines acquired and release events.
CONFIG_LOCK_STAT defines contended and acquired lock events.
(1) 常用选项
-i <file>:输入文件
-k <value>:sorting key,默认为acquired,还可以按contended、wait_total、wait_max和wait_min来排序。
(2) 使用例子
# perf lock record ls // 记录
# perf lock report // 报告
(3) 输出格式
[plain] view plain copy ![]()
![]()
- Name acquired contended total wait (ns) max wait (ns) min wait (ns)
- &mm->page_table_... 382 0 0 0 0
- &mm->page_table_... 72 0 0 0 0
- &fs->lock 64 0 0 0 0
- dcache_lock 62 0 0 0 0
- vfsmount_lock 43 0 0 0 0
- &newf->file_lock... 41 0 0 0 0
Name:内核锁的名字。
aquired:该锁被直接获得的次数,因为没有其它内核路径占用该锁,此时不用等待。
contended:该锁等待后获得的次数,此时被其它内核路径占用,需要等待。
total wait:为了获得该锁,总共的等待时间。
max wait:为了获得该锁,最大的等待时间。
min wait:为了获得该锁,最小的等待时间。
最后还有一个Summary:
[plain] view plain copy ![]()
![]()
- === output for debug===
- bad: 10, total: 246
- bad rate: 4.065041 %
- histogram of events caused bad sequence
- acquire: 0
- acquired: 0
- contended: 0
- release: 10
perf-kmem
slab分配器的性能分析。
Tool to trace/measure kernel memory(slab) properties.
perf kmem {record | stat} [<options>]
(1) 常用选项
--i <file>:输入文件
--caller:show per-callsite statistics,显示内核中调用kmalloc和kfree的地方。
--alloc:show per-allocation statistics,显示分配的内存地址。
-l <num>:print n lines only,只显示num行。
-s <key[,key2...]>:sort the output (default: frag,hit,bytes)
(2) 使用例子
# perf kmem record ls // 记录
# perf kmem stat --caller --alloc -l 20 // 报告
(3) 输出格式
[plain] view plain copy ![]()
![]()
- ------------------------------------------------------------------------------------------------------
- Callsite | Total_alloc/Per | Total_req/Per | Hit | Ping-pong | Frag
- ------------------------------------------------------------------------------------------------------
- perf_event_mmap+ec | 311296/8192 | 155952/4104 | 38 | 0 | 49.902%
- proc_reg_open+41 | 64/64 | 40/40 | 1 | 0 | 37.500%
- __kmalloc_node+4d | 1024/1024 | 664/664 | 1 | 0 | 35.156%
- ext3_readdir+5bd | 64/64 | 48/48 | 1 | 0 | 25.000%
- load_elf_binary+8ec | 512/512 | 392/392 | 1 | 0 | 23.438%
Callsite:内核代码中调用kmalloc和kfree的地方。
Total_alloc/Per:总共分配的内存大小,平均每次分配的内存大小。
Total_req/Per:总共请求的内存大小,平均每次请求的内存大小。
Hit:调用的次数。
Ping-pong:kmalloc和kfree不被同一个CPU执行时的次数,这会导致cache效率降低。
Frag:碎片所占的百分比,碎片 = 分配的内存 - 请求的内存,这部分是浪费的。
有使用--alloc选项,还会看到Alloc Ptr,即所分配内存的地址。
最后还有一个Summary:
[plain] view plain copy ![]()
![]()
- SUMMARY
- =======
- Total bytes requested: 290544
- Total bytes allocated: 447016
- Total bytes wasted on internal fragmentation: 156472
- Internal fragmentation: 35.003669%
- Cross CPU allocations: 2/509
probe-sched
调度模块分析。
trace/measure scheduler properties (latencies)
perf sched {record | latency | map | replay | script}
(1) 使用例子
# perf sched record sleep 10 // perf sched record <command>
# perf report latency --sort max
(2) 输出格式
[plain] view plain copy ![]()
![]()
- ---------------------------------------------------------------------------------------------------------------
- Task | Runtime ms | Switches | Average delay ms | Maximum delay ms | Maximum delay at |
- ---------------------------------------------------------------------------------------------------------------
- events/10:61 | 0.655 ms | 10 | avg: 0.045 ms | max: 0.161 ms | max at: 9804.958730 s
- sleep:11156 | 2.263 ms | 4 | avg: 0.052 ms | max: 0.118 ms | max at: 9804.865552 s
- edac-poller:1125 | 0.598 ms | 10 | avg: 0.042 ms | max: 0.113 ms | max at: 9804.958698 s
- events/2:53 | 0.676 ms | 10 | avg: 0.037 ms | max: 0.102 ms | max at: 9814.751605 s
- perf:11155 | 2.109 ms | 1 | avg: 0.068 ms | max: 0.068 ms | max at: 9814.867918 s
TASK:进程名和pid。
Runtime:实际的运行时间。
Switches:进程切换的次数。
Average delay:平均的调度延迟。
Maximum delay:最大的调度延迟。
Maximum delay at:最大调度延迟发生的时刻。
perf-probe
可以自定义探测点。
Define new dynamic tracepoints.
使用例子
(1) Display which lines in schedule() can be probed
# perf probe --line schedule
前面有行号的可以探测,没有行号的就不行了。
(2) Add a probe on schedule() function 12th line.
# perf probe -a schedule:12
在schedule函数的12处增加一个探测点。
Reference
[1]. Linux的系统级性能剖析工具系列,by 承刚
[2]. http://www.ibm.com/developerworks/cn/linux/l-cn-perf1/
[3]. http://www.ibm.com/developerworks/cn/linux/l-cn-perf2/
[4]. https://perf.wiki.kernel.org/index.php/Tutorial