perf学习
什么是perf?
linux性能调优工具,32内核以上自带的工具,软件性能分析。在2.6.31及后续版本的Linux内核里,安装perf非常的容易。
几乎能够处理所有与性能相关的事件。perf可以用于查看热点函数,查看cashe miss的比率,从而帮助开发者来优化程序性能。
什么是性能事件?
指在处理器或者操作系统中发生,可能影响到程序性能的硬件事件或者软件事情。
主要关注点在哪里?
算法优化(空间复杂度、时间复杂度)、代码优化(提到执行速度、减少内存占用)
评估程序对硬件资源的使用情况,例如各级cache的访问次数,各级cache的丢失次数、流水线停顿周期、前端总线访问次数等。
评估程序对操作系统资源的使用情况,系统调用次数、上下文切换次数、任务迁移次数。
基本原理?
硬件的话采用PMC(performance monitoring unit)CPU的部件,在特定的条件下探测的性能事件是否发生以及发生的次数。软件性能测试,内置于kernel,分布在各个功能模块中,统计和操作系统相关性能事件。
性能调优工具如 perf,Oprofile 等的基本原理都是对被监测对象进行采样,最简单的情形是根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文。假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,但我想只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 tick 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。
稍微扩展一下思路,就可以发现改变采样的触发条件使得我们可以获得不同的统计数据:
以时间点 ( 如 tick) 作为事件触发采样便可以获知程序运行时间的分布。
以 cache miss 事件触发采样便可以知道 cache miss 的分布,即 cache 失效经常发生在哪些程序代码中。如此等等。
如何使用高精度的采样?
如果需要采用高精度的采样,需要在制定性能事情时,在事件后添加后缀“:p”或者“:pp”
| 1 2 3 4 |
|
使用perf list(在root权限下运行),可以列出所有的采样事件
事件分为以下三种:
1)Hardware Event 是由 PMU 硬件产生的事件,比如 cache 命中,当您需要了解程序对硬件特性的使用情况时,便需要对这些事件进行采样;
2)Software Event 是内核软件产生的事件,比如进程切换,tick 数等 ;
3)Tracepoint event 是内核中的静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等。
上述每一个事件都可以用于采样,并生成一项统计数据,时至今日,尚没有文档对每一个 event 的含义进行详细解释。

List of pre-defined events (to be used in -e):cpu-cycles OR cycles [Hardware event]处理器周期事件stalled-cycles-frontend OR idle-cycles-frontend [Hardware event]stalled-cycles-backend OR idle-cycles-backend [Hardware event]instructions [Hardware event]cache-references [Hardware event]cache-misses [Hardware event]branch-instructions OR branches [Hardware event]branch-misses [Hardware event]bus-cycles [Hardware event]cpu-clock [Software event]task-clock [Software event]page-faults OR faults [Software event]minor-faults [Software event]major-faults [Software event]context-switches OR cs [Software event]cpu-migrations OR migrations [Software event]alignment-faults [Software event]emulation-faults [Software event]L1-dcache-loads [Hardware cache event]L1-dcache-load-misses [Hardware cache event]L1-dcache-stores [Hardware cache event]L1-dcache-store-misses [Hardware cache event]L1-dcache-prefetches [Hardware cache event]L1-dcache-prefetch-misses [Hardware cache event]L1-icache-loads [Hardware cache event]L1-icache-load-misses [Hardware cache event]L1-icache-prefetches [Hardware cache event]L1-icache-prefetch-misses [Hardware cache event]LLC-loads [Hardware cache event]LLC-load-misses [Hardware cache event]LLC-stores [Hardware cache event]LLC-store-misses [Hardware cache event]LLC-prefetches [Hardware cache event]LLC-prefetch-misses [Hardware cache event]dTLB-loads [Hardware cache event]dTLB-load-misses [Hardware cache event]dTLB-stores [Hardware cache event]dTLB-store-misses [Hardware cache event]dTLB-prefetches [Hardware cache event]dTLB-prefetch-misses [Hardware cache event]iTLB-loads [Hardware cache event]iTLB-load-misses [Hardware cache event]branch-loads [Hardware cache event]branch-load-misses [Hardware cache event]
perf的安装?
安装 perf 非常简单, 只要内核版本高于2.6.31的, perf已经被内核支持. 首先安装内核源码:
apt-get install linux-source
那么在 /usr/src 目录下就已经下载好了内核源码, 我们对源码包进行解压, 然后进入 tools/perf 目录然后敲入下面两个命令即可:
make
make install
可能因为系统原因, 需要提前安装下面的开发包:
- apt-get install -y binutils-dev
- apt-get install -y libdw-dev
- apt-get install -y python-dev
- apt-get install -y libnewt-dev
提示:
1)可能在编译的时候,有报错大概是由于平台问题,数据类型不匹配,导致所有的warning都被当作error对待:出现这问题的原因是-Werror这个gcc编译选项。只要在makefile中找到包含这个-Werror选项的句子,将-Werror删除,或是注释掉就行了
2)安装完毕,perf可执行程序往往位于当前目录,可能不在系统的PATH路径中,此时需要改变环境变量PATH
使用实例
perf COMMAND [-e event ...] PROGRAM, perf 是采用的这么一个命令格式,
COMMAND一般常用的就是 top, stat, record, report等. 然后用 -e 参数来统计需要关注的事件. 多个事件就用多个 -e 连接.
命令1:perf stat分析程序的整体性能
利用10个典型事件剖析了应用程序。
-
task-clock:目标任务真真占用处理器的时间,单位是毫秒,我们称之为任务执行时间,后面是任务的处理器占用率(执行时间和持续时间的比值)。持续时间值从任务提交到任务结束的总时间(总时间在stat结束之后会打印出来)。CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。
-
context-switches:上下文切换次数,前半部分是切换次数,后面是平均每秒发生次数(M是10的6次方)。
-
cpu-migrations:处理器迁移,linux为了位置各个处理器的负载均衡,会在特定的条件下将某个任务从一个处理器迁往另外一个处理器,此时便是发生了一次处理器迁移。即被调度器从一个 CPU 转移到另外一个 CPU 上运行。
-
page-fault:缺页异常,linux内存管理子系统采用了分页机制,
当应用程序请求的页面尚未建立、请求的页面不在内存中或者请求的页面虽在在内存中,
但是尚未建立物理地址和虚拟地址的映射关系是,会触发一次缺页异常。
-
cycles:任务消耗的处理器周期数;处理器时钟,一条机器指令可能需要多个 cycles;
-
instructions:任务执行期间产生的处理器指令数,IPC(instructions perf cycle)
IPC(Instructions/Cycles )是评价处理器与应用程序性能的重要指标。(很多指令需要多个处理周期才能执行完毕),
IPC越大越好,说明程序充分利用了处理器的特征。
-
branches:程序在执行期间遇到的分支指令数。
-
branch-misses:预测错误的分支指令数
-
cache-misses:cache时效的次数
-
cache-references:cache的命中次数
常用的参数如下
| 1 2 3 4 5 |
|
一次分析后的结果如下:
Performance counter stats for process id '21787':42677.253367 task-clock # 0.142 CPUs utilized 587,906 context-switches # 0.014 M/sec 29,209 CPU-migrations # 0.001 M/sec 117 page-faults # 0.000 M/sec 82,341,400,508 cycles # 1.929 GHz [83.48%]61,262,984,952 stalled-cycles-frontend # 74.40% frontend cycles idle [83.28%]43,113,701,768 stalled-cycles-backend # 52.36% backend cycles idle [66.72%]44,023,301,495 instructions # 0.53 insns per cycle # 1.39 stalled cycles per insn [83.50%]8,137,448,528 branches # 190.674 M/sec [83.22%]430,957,756 branch-misses # 5.30% of all branches [83.34%]300.393753095 seconds time elapsed
考查下面这个例子程序。其中函数 longa() 是个很长的循环,比较浪费时间。函数 foo1 和 foo2 将分别调用该函数 10 次,以及 100 次。
//t1.c void longa() { int i,j; for(i = 0; i < 1000000; i++) j=i; //am I silly or crazy? I feel boring and desperate. } void foo2() { int i; for(i=0 ; i < 10; i++) longa(); } void foo1() { int i; for(i = 0; i< 100; i++) longa(); } int main(void) { foo1(); foo2(); }
然后编译它: gcc -o t1 -g t1.c
下面演示了 perf stat 针对程序 t1 的输出:
root@ubuntu-test:~# perf stat ./t1Performance counter stats for './t1':218.584169 task-clock # 0.997 CPUs utilized 18 context-switches # 0.000 M/sec 0 CPU-migrations # 0.000 M/sec 82 page-faults # 0.000 M/sec 771,180,100 cycles # 3.528 GHz <not counted> stalled-cycles-frontend <not counted> stalled-cycles-backend 550,703,114 instructions # 0.71 insns per cycle 110,117,522 branches # 503.776 M/sec 5,009 branch-misses # 0.00% of all branches 0.219155248 seconds time elapsed程序 t1 是一个 CPU bound 型,因为 task-clock-msecs 接近 1
对 t1 进行调优应该要找到热点 ( 即最耗时的代码片段 ),再看看是否能够提高热点代码的效率。
通过指定 -e 选项,您可以改变 perf stat 的缺省事件 ( 关于事件,可以通过 perf list 来查看 )。假如您已经有很多的调优经验,可能会使用 -e 选项来查看您所感兴趣的特殊的事件。
有些程序慢是因为计算量太大,其多数时间都应该在使用 CPU 进行计算,这叫做 CPU bound 型;有些程序慢是因为过多的 IO,这种时候其 CPU 利用率应该不高,这叫做 IO bound 型;对于 CPU bound 程序的调优和 IO bound 的调优是不同的。
命令2:perf top实时显示系统/进程的性能统计信息
默认性能事件“cycles CPU周期数”进行全系统的性能剖析
常见的参数如下:
| 1 2 3 4 |
|
结果输出中,比例是该符号引发的性能时间在整个监测域中占的比例,通常称为热度。
samples pcnt function DSO _______ _____ ______________________________________________________________________________________ _________61.00 19.4% native_write_msr_safe [kernel]18.00 5.7% JVM_InternString libjvm.so17.00 5.4% find_busiest_group [kernel]17.00 5.4% _spin_lock [kernel]12.00 3.8% dev_hard_start_xmit [kernel]11.00 3.5% tg_load_down [kernel]9.00 2.9% futex_wake [kernel]8.00 2.5% do_futex [kernel]7.00 2.2% load_balance_fair [kernel]7.00 2.2% weighted_cpuload [kernel]7.00 2.2% update_cfs_shares [kernel]7.00 2.2% JVM_LatestUserDefinedLoader libjvm.so6.00 1.9% update_cfs_load [kernel]5.00 1.6% _ZN16SystemDictionary30resolve_instance_class_or_nullE12symbolHandle6HandleS1_P6Thread libjvm.so5.00 1.6% br_sysfs_delbr [bridge]5.00 1.6% futex_wait
使用 perf stat 的时候,往往您已经有一个调优的目标。比如程序 t1。也有些时候,只是发现系统性能无端下降,并不清楚究竟哪个进程成为了贪吃的 hog。
此时需要一个类似 top 的命令,列出所有值得怀疑的进程,从中找到需要进一步审查的家伙。
Perf top 用于实时显示当前系统的性能统计信息。该命令主要用来观察整个系统当前的状态,比如可以通过查看该命令的输出来查看当前系统最耗时的内核函数或某个用户进程。
让再设计一个例子来演示:
//t2.c
main(){int i;while(1) i++;
}
编译:gcc -o t2 -g t2.c
运行这个程序后, 运行perf top来看看:
PerfTop: 705 irqs/sec kernel:60.4% [1000Hz cycles] -------------------------------------------------- sampl pcnt function DSO 1503.00 49.2% t2 72.00 2.2% pthread_mutex_lock /lib/libpthread-2.12.so 68.00 2.1% delay_tsc [kernel.kallsyms] 55.00 1.7% aes_dec_blk [aes_i586] 55.00 1.7% drm_clflush_pages [drm] 52.00 1.6% system_call [kernel.kallsyms] 49.00 1.5% __memcpy_ssse3 /lib/libc-2.12.so 48.00 1.4% __strstr_ia32 /lib/libc-2.12.so 46.00 1.4% unix_poll [kernel.kallsyms] 42.00 1.3% __ieee754_pow /lib/libm-2.12.so 41.00 1.2% do_select [kernel.kallsyms] 40.00 1.2% pixman_rasterize_edges libpixman-1.so.0.18.0 37.00 1.1% _raw_spin_lock_irqsave [kernel.kallsyms] 36.00 1.1% _int_malloc /lib/libc-2.12.so ^C
很容易便发现 t2 是需要关注的可疑程序。
关于perf top具节的一些命令:
1)perf top -e cpu-clock: 查看CPU的使用
2)perf top -e faults : 查看 page faults
3)perf top -e block:block_rq_issue : 查看系统IO的请求
比如可以在发现系统IO异常时,可以使用该命令进行调查,就能指定到底是什么原因导致的IO异常。 block_rq_issue 表示 block_request_issue 就是IO请求数。其实从这些可以看出,分析和调查Linux上的各种性能问题,需要我们对Linux内核有比较多的了解,不然恐怕是无从下手的。
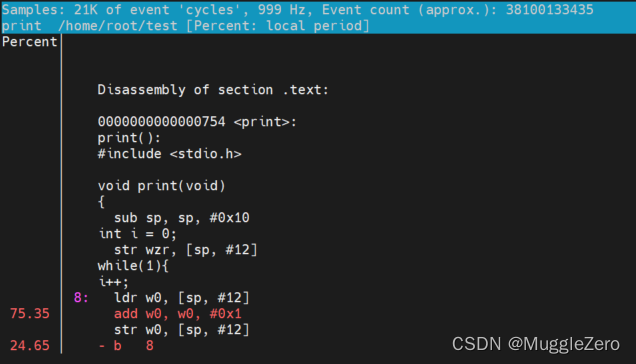
命令3:perf record/report记录一段时间内系统/进程的性能事件
默认在当前目录下生成数据文件:perf.data 。report读取生成的perf.data文件,-i参数指定路径
使用 top 和 stat 之后,您可能已经大致有数了。要进一步分析,便需要一些粒度更细的信息。比如说您已经断定目标程序计算量较大,也许是因为有些代码写的不够精简。那么面对长长的代码文件,究竟哪几行代码需要进一步修改呢?这便需要使用 perf record 记录单个函数级别的统计信息,并使用 perf report 来显示统计结果。
您的调优应该将注意力集中到百分比高的热点代码片段上,假如一段代码只占用整个程序运行时间的 0.1%,即使您将其优化到仅剩一条机器指令,恐怕也只能将整体的程序性能提高 0.1%。俗话说,好钢用在刀刃上,不必我多说了。
perf record -e cpu-clock ./t1 perf reportperf report 输出结果:
Events: 229 cpu-clock 100.00% t1 t1 [.] longa
不出所料,hot spot 是 longa( ) 函数。
但,代码是非常复杂难说的,t1 程序中的 foo1() 也是一个潜在的调优对象,为什么要调用 100 次那个无聊的 longa() 函数呢?但我们在上图中无法发现 foo1 和 foo2,更无法了解他们的区别了。
我曾发现自己写的一个程序居然有近一半的时间花费在 string 类的几个方法上,string 是 C++ 标准,我绝不可能写出比 STL 更好的代码了。因此我只有找到自己程序中过多使用 string 的地方。因此我很需要按照调用关系进行显示的统计信息。
使用 perf 的 -g 选项便可以得到需要的信息:
perf record -e cpu-clock -g ./t1 perf report输出结果:
Events: 270 cpu-clock - 100.00% t1 t1 [.] longa- longa+ 91.85% foo1+ 8.15% foo2
命令4:使用 tracepoint
当 perf 根据 tick 时间点进行采样后,人们便能够得到内核代码中的 hot spot。那什么时候需要使用 tracepoint 来采样呢?
我想人们使用 tracepoint 的基本需求是对内核的运行时行为的关心,如前所述,有些内核开发人员需要专注于特定的子系统,比如内存管理模块。这便需要统计相关内核函数的运行情况。另外,内核行为对应用程序性能的影响也是不容忽视的:
以之前的遗憾为例,假如时光倒流,我想我要做的是统计该应用程序运行期间究竟发生了多少次系统调用。在哪里发生的?
下面我用 ls 命令来演示 sys_enter 这个 tracepoint 的使用:
| 1 2 3 4 5 6 7 8 9 |
|
这个报告详细说明了在 ls 运行期间发生了多少次系统调用 ( 上例中有 111 次 )
主要参考文章:
Perf -- Linux下的系统性能调优工具,第 1 部分
Perf -- Linux下的系统性能调优工具,第 2 部分
perf学习-linux自带性能分析工具
Perf使用教程
Linux 性能优化工具 perf top
http://blog.csdn.net/bluebeach/article/details/5912062
http://lenky.info/2012/10/31/perf%E5%88%9D%E8%AF%95%E7%94%A8
转自https://www.cnblogs.com/kongzhongqijing/articles/5121620.html





![[JavaScript] 理解 e.clientX,e.clientY e.pageX e.pageY e.offsetX e.offsetY](https://img-blog.csdnimg.cn/20200917224556661.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQzNTQwMjE5,size_16,color_FFFFFF,t_70#pic_center)