perf研究总结
最近在天数搞一个性能的工具,需要抓callstack 包括用户态和内核的太调用栈,那么就顺便研究了一下perf工具。做了一个简单的总结。
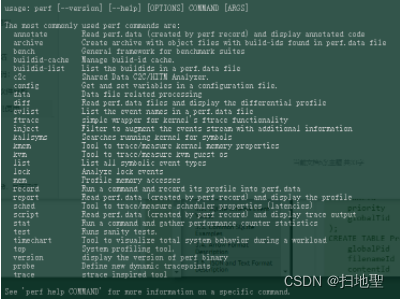
perf --help
显示具体的命令,每个命令如何使用,再perf cmd --help会显示
参考链接
参考链接1
参考链接2
ubuntu安装perf工具
Ubuntu:apt install linux-tools-common
perf 原理
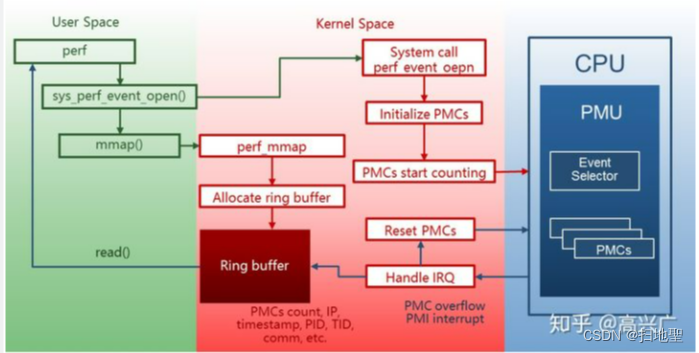
Perf通过系统调用sys_perf_event_open 陷入到内核中,内核根据perf 提供的信息在PMU(Performance Monitoring Unit)上初始化一个硬件性能计数器(PMC: Performance Monitoring Counter)。PMC随着指定硬件事件的发生而自动累加。在PMC 溢出时,PMU 触发一个PMI(Performance Monitoring Interrupt)中断。内核在PMI 中断的处理函数中保存PMC 的计数值,触发中断时的指令地址,当前时间戳以及当前进程的PID,TID,comm 等信息。我们把这些信息统称为一个采样(sample)。内核会将收集到的sample 放入用于跟用户空间通信的Ring Buffer。用户空间里的perf 分析程序采用mmap 机制从ring buffer 中读入采样,并对其解析。
perf支持两种模式:计算模式和采样模式。后面解释perf stat使用的是计数模式,perf record使用的是采样模式
能够定位的性能事件
在程序运行中发生的,可能影响到程序性能的软硬件件事件,使用perf list命令可以显示当前软硬件环境下支持的所有事件,大致可以分为三种:
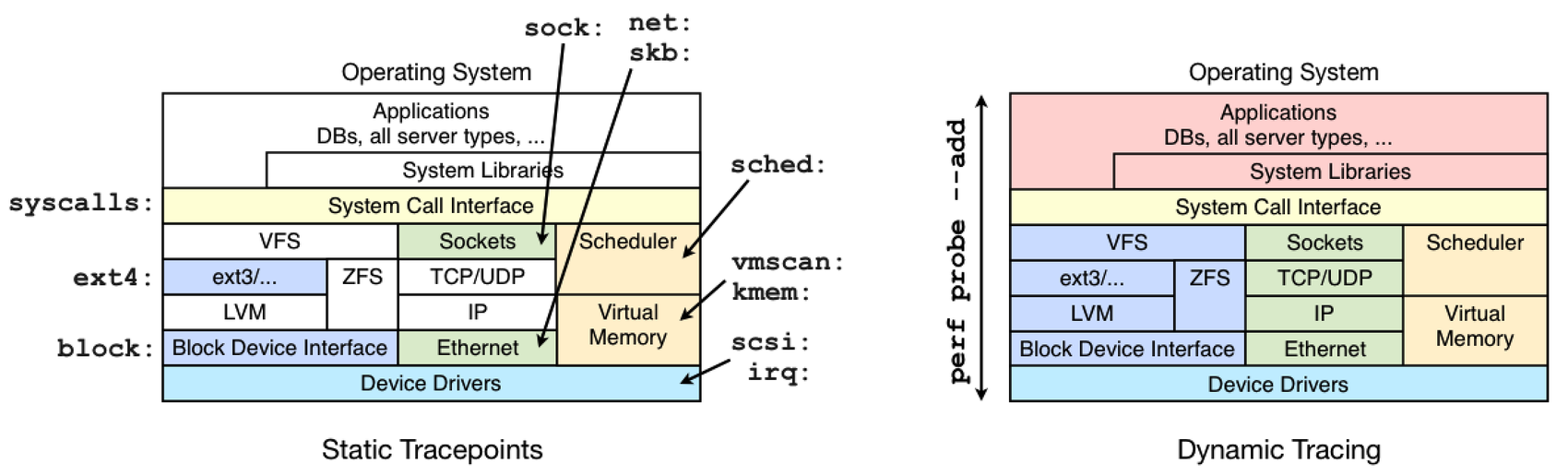
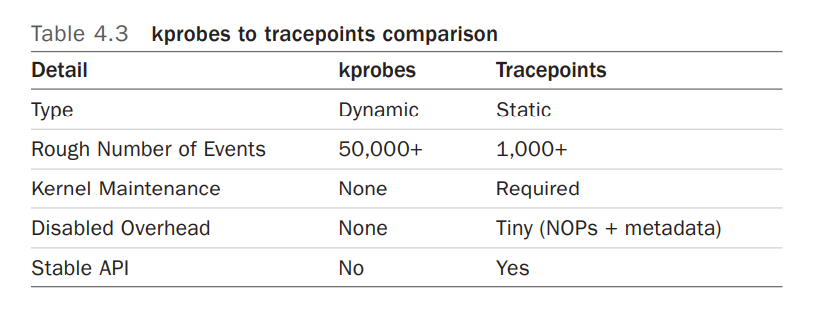
Hardware Event由PMU部件产生,在特定的条件下探测性能事件是否发生以及发生的次数。比如CPU周期、分支指令、TLB重填例外、Cache缺失等。Software Event是内核产生的事件,分布在各个功能模块中,统计和操作系统相关性能事件。比如系统调用次数、上下文切换次数、任务迁移次数、缺页例外次数等。Tracepoint Event是内核中静态tracepoint所触发的事件,这些tracepoint用来判断程序运行期间内核的行为细节,比如slab分配器的分配次数等。基于ftrace框架实现,内核中的所有tracepoint都可以作为perf都性能事件cat /sys/kernel/debug/tracing/available_events,可查看当前系统的所有tracepoint分成了几大类:ext4 文件系统的tracepoint events,如果是其它文件系统,比如XFS,也有对应的tracepoint event;
jbd2 文件日志的tracepoint events;
skb 内存的tracepoint events;
net,napi,sock,udp:网络的tracepoint events;
scsi, block, writeback 磁盘IO
kmem 内存
sched 调度
syscalls 系统调用
性能事件属性
硬件性能事件由处理器中的PMU提供支持。由于现代处理器的主频非常高,再加上深度流水线机制,从性能事件被触发,到处理器响应 PMI中断,流水线上可能已处理过数百条指令。那么PMI中断采到的指令地址就不再是触发性能事件的那条指令的地址了,而且可能具有非常严重的偏差。为了解决这个问题,Intel处理器通过PEBS机制实现了高精度事件采样。PEBS通过硬件在计数器溢出时将处理器现场直接保存到内存(而不是在响应中断时才保存寄存器现场),从而使得 perf能够采到真正触发性能事件的那条指令的地址,提高了采样精度。在默认条件下,perf不使用PEBS机制。用户如果想要使用高精度采样,需要在指定性能事件时,在事件名后添加后缀”:p”或”:pp”。Perf在采样精度上定义了4个级别,如下表所示。
级别描述
0 无精度保证
1 采样指令与触发性能事件的指令之间的偏差为常数(:p)
2 需要尽量保证采样指令与触发性能事件的指令之间的偏差为0(:pp)
3 保证采样指令与触发性能事件的指令之间的偏差必须为0(:ppp)
性能事件的精度级别目前的X86处理器,包括Intel处理器与AMD处理器均仅能实现前 3 个精度级别。
除了精度级别以外,性能事件还具有其它几个属性,均可以通过”event:X”的方式予以指定
标志属性
u 仅统计用户空间程序触发的性能事件
k 仅统计内核触发的性能事件
h 仅统计Hypervisor触发的性能事件
G 在KVM虚拟机中,仅统计Guest系统触发的性能事件
H 仅统计 Host 系统触发的性能事件
p 精度级别
常用命令
perf共22种子命令,常用的是以下5种:
perf list:查看当前软硬件环境支持的性能事件
perf stat:分析指定程序的性能概况默认事件
task-clock:任务真正占用的处理器时间,单位为ms。CPUs utilized = task-clock / time elapsed,CPU的占用率,值高,说明程序的多数时间花费在CPU计算上而非IO。
context-switches:上下文的切换次数。 CPU-migrations:处理器迁移次数。Linux为了维持多个处理器的负载均衡,在特定条件下会将某个任务从一个CPU迁移到另一个CPU。
page-faults:缺页异常的次数。当应用程序请求的页面尚未建立、请求的页面不在内存中,或者请求的页面虽然在内存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页异常。另外TLB不命中,页面访问权限不匹配等情况也会触发缺页异常。
cycles:消耗的处理器周期数。
instructions:执行了多少条指令。IPC为平均每个cpu cycle执行了多少条
branches:遇到的分支指令数。
branch-misses:预测错误的分支指令数
参数
-e <event>:指定性能事件(可以是多个,用,分隔列表)-p <pid>:指定待分析进程的 pid(可以是多个,用,分隔列表)-t <tid>;:指定待分析线程的 tid(可以是多个,用,分隔列表)-a:从所有 CPU 收集系统数据-d:打印更详细的信息,可重复 3 次 -d:L1 和 LLC data cache -d -d:dTLB 和 iTLB events -d -d -d:增加 prefetch events-r <n>;:重复运行命令 n 次,打印平均值。n 设为 0 时无限循环打印-c <cpu-list>:只统计指定 CPU 列表的数据,如:0,1,3或1-2-A:与-a选项联用,不要将 CPU 计数聚合-I <N msecs>:每隔 N 毫秒打印一次计数器的变化,N 最小值为 100 毫秒
perf top:实时显示系统/进程的性能统计信息
参数
常用命令行参数:-e <event>:指明要分析的性能事件。-p <pid>:仅分析目标进程及其创建的线程。-k <path>:带符号表的内核映像所在的路径。-K:不显示属于内核或模块的符号。-U:不显示属于用户态程序的符号。-d <n>:界面的刷新周期,默认为2s。-g:得到函数的调用关系图
perf record:记录一段时间内系统/进程的性能事件
收集一段时间内的性能事件到文件 perf.data,随后需要用perf report命令分析参数-e <event>:指定性能事件(可以是多个,用,分隔列表)-p <pid>:指定待分析进程的 pid(可以是多个,用,分隔列表)-t <tid>:指定待分析线程的 tid(可以是多个,用,分隔列表)-u <uid>:指定收集的用户数据,uid为名称或数字-a:从所有 CPU 收集系统数据-g:开启 call-graph (stack chain/backtrace) 记录-C <cpu-list>:只统计指定 CPU 列表的数据,如:0,1,3或1-2-r <RT priority>:perf 程序以SCHED_FIFO实时优先级RT priority运行这里填入的数值越大,进程优先级越高(即 nice 值越小)-c <count>: 事件每发生 count 次采一次样-F <n>:每秒采样 n 次-o <output.data>:指定输出文件output.data,默认输出到perf.data
perf report:读取perf record生成的perf.data文件,并显示分析数据
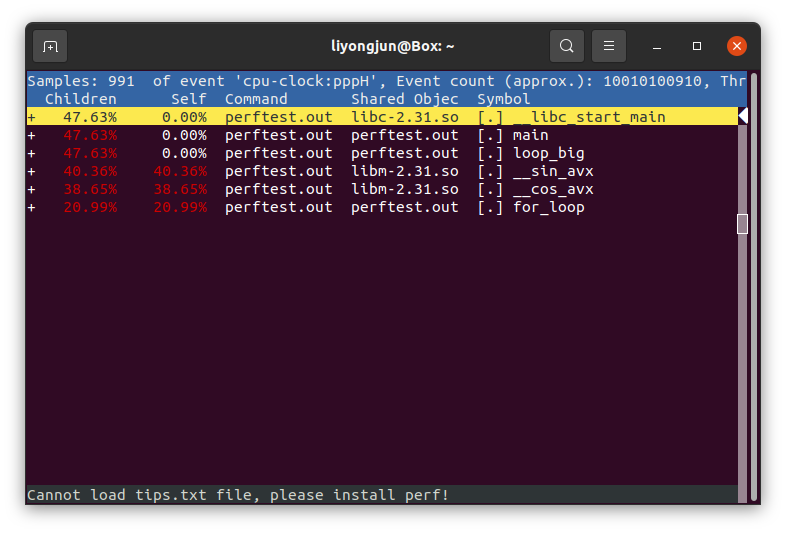
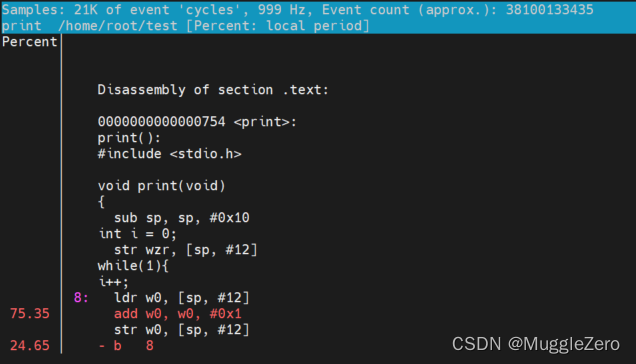
计算开销 perf收集调用链时,开销可以在两列中显示为“Children”和“Self”。“self”开销只是通过所有入口(通常是一个函数,也就是符号)的所有周期值相加来计算的。这是perf传统显示方式,所有“self”开销值之和应为100%。“children”开销是通过将子函数的所有周期值相加来计算的,这样它就可以显示更高级别函数的总开销,即使它们不直接参与更多的执行。这里的“Children”表示从另一个(父)函数调用的函数。所有“children”开销值之和超过100%可能会令人困惑,因为它们中的每一个已经是其子函数的“self”开销的累积。但是如果启用了这个功能,用户可以找到哪一个函数的开销最大,即使样本分布在子函数上。 children(复函数)=self(父函数)+ children(子函数)所有函数的self之和为100%
例如:
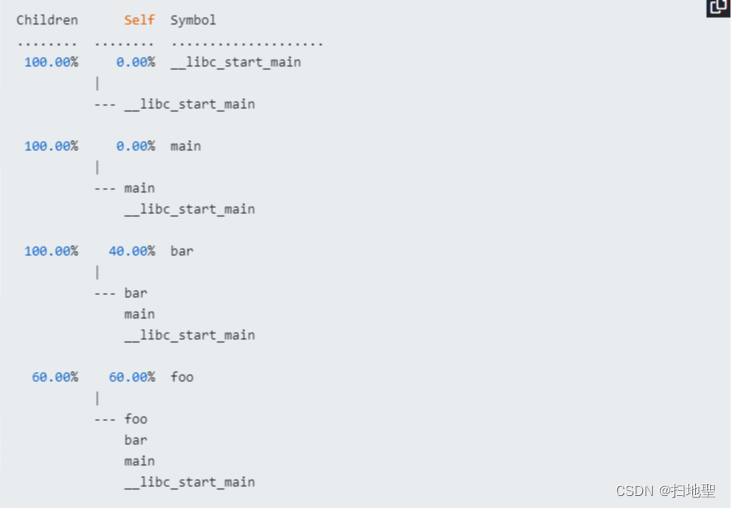
在上述输出中,“foo”的“self”开销(60%)被添加到“bar”、“main”和“__libc_start_main”的“children”开销中。同样,“bar”的“self”开销(40%)添加到“main”和“libc”的“children”开销中。因此,首先显示’__libc_start_main’和’main’,因为它们有相同(100%)的“子”开销(即使它们没有“自”开销),并且它们是’foo’和’bar’的父级
example
分析进程perf top -g -p 1234-g:可以查看堆栈调用-p 指定pid-a:查看所有CPUperf record -g -p pid 需要搭配perf report使用-g:可以查看调用栈 等价与--call-graph fp 默认就是这个--call-graph dwarf/lbr 也是显示调用栈,只是调用栈的原则不一样-o 输出文件名称 不加默认输出perf.data分析线程perf record -g -t tid分析一个可执行程序调用栈sudo perf record -o perf-pi.data --call-graph dwarf ./piperf report -i perf-pi.data --call-graph









![[JavaScript] 理解 e.clientX,e.clientY e.pageX e.pageY e.offsetX e.offsetY](https://img-blog.csdnimg.cn/20200917224556661.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQzNTQwMjE5,size_16,color_FFFFFF,t_70#pic_center)