文章目录
- 一、什么是决策树?
- 二、决策树算法基本步骤
- 三、算法实例
- 1.数据集描述
- 2.计算数据集香农熵
- 3.数据集划分
- 4.选择最好的数据集划分方式
- 5.递归构建决策树
- 6.创建树
- 7.构造注解树
- 8.使用决策树执行分类
- 9.决策树的保存
- 三、运行结果
一、什么是决策树?
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
二、决策树算法基本步骤
1) 构建根节点,将所有训练数据都放在根节点,根据某种算法选择一个最优特征,按着这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。
2) 如果这些子集已经能够被基本正确分类,那么构建叶节点,并将这些子集分到所对应的叶节点去。
3)如果还有子集不能够被正确的分类,选取子集选择新的最优特征,继续对其进行分割,构建相应的节点,如此递归,直至所有训练数据子集被基本正确的分类,或者没有合适的特征为止。
4)每个子集都被分到叶节点上,即都有了明确的类,这样就生成了一颗决策树。

三、算法实例
1.数据集描述

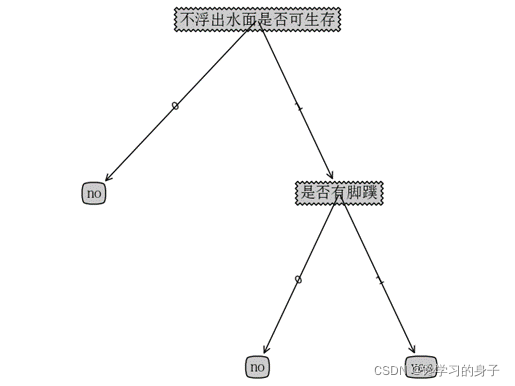
#训练集dataSet = [[0, 1, 0, 0, 'no'],[0, 1, 1, 1, 'yes'],[1, 1, 1, 0, 'no'],[2, 0, 1, 1, 'no'],[2, 0, 1, 0, 'no'],[2, 1, 1, 1, 'yes'],[0, 1, 0, 0, 'no'],[1, 0, 1, 1, 'no'],[2, 0, 1, 0, 'no'],[0, 0, 1, 0, 'no'],[0, 0, 1, 1, 'no'],[2, 1, 1, 0, 'no'],[1, 1, 1, 1, 'yes'],[1, 0, 1, 0, 'no'],[2, 1, 0, 0, 'no']]# 分类属性labels = ['年龄', '地址', '是否学习C语言', '是否学习机器学习']#测试数据testVec = [0, 1, 1, 1]
2.计算数据集香农熵

#计算数据集香农熵
def calcShannonEnt(dataSet):# 统计数据数量numEntries = len(dataSet)# 存储每个label出现次数label_counts = {}# 统计label出现次数for featVec in dataSet:current_label = featVec[-1]if current_label not in label_counts: # 提取label信息label_counts[current_label] = 0 # 如果label未在dict中则加入label_counts[current_label] += 1 # label计数shannon_ent = 0 for key in label_counts:prob = float(label_counts[key]) / numEntriesshannon_ent -= prob * log(prob, 2)return shannon_ent3.数据集划分
#数据集划分
def splitDataSet(data_set, axis, value):ret_dataset = []for feat_vec in data_set:if feat_vec[axis] == value:reduced_feat_vec = feat_vec[:axis]reduced_feat_vec.extend(feat_vec[axis + 1:])ret_dataset.append(reduced_feat_vec)return ret_dataset4.选择最好的数据集划分方式
度量数据集的信息熵并有效划分数据集
#选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet): num_features = len(dataSet[0]) - 1base_entropy = calcShannonEnt(dataSet)best_info_gain = 0.0best_feature = -1#创建唯一的分类标签列表for i in range(num_features):feat_list = [exampel[i] for exampel in dataSet]unique_val = set(feat_list)new_entropy = 0.0# 计算每种划分方式的信息熵for value in unique_val:sub_dataset = splitDataSet(dataSet, i, value)prob = len(sub_dataset) / float(len(dataSet))new_entropy += prob * calcShannonEnt(sub_dataset)# 信息增益info_gain = base_entropy - new_entropyprint("第%d个特征的信息增益为%.3f" % (i, info_gain))# 计算最好的信息增益if info_gain > best_info_gain: best_info_gain = info_gain best_feature = iprint("最优索引值:" + str(best_feature))print()return best_feature
5.递归构建决策树
#递归构建决策树
def majority_cnt(class_list):class_count = {}# 统计class_list中每个元素出现的次数for vote in class_list:if vote not in class_count:class_count[vote] = 0class_count[vote] += 1# 根据字典的值降序排列sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)return sorted_class_count[0][0]
6.创建树
createTree是核心任务函数,它对所有的属性依次调用ID3信息熵增益算法进行计算处理,最终生成决策树
#创建树
def creat_tree(dataSet, labels, featLabels): class_list = [exampel[-1] for exampel in dataSet]# 如果类别完全相同则停止分类if class_list.count(class_list[0]) == len(class_list):return class_list[0]# 遍历完所有特征时返回出现次数最多的类标签if len(dataSet[0]) == 1:return majority_cnt(class_list)best_feature = chooseBestFeatureToSplit(dataSet)best_feature_label = labels[best_feature]featLabels.append(best_feature_label)my_tree = {best_feature_label: {}}del(labels[best_feature])# 得到训练集中所有最优特征的属性值feat_value = [exampel[best_feature] for exampel in dataSet]unique_vls = set(feat_value)for value in unique_vls:my_tree[best_feature_label][value] = creat_tree(splitDataSet(dataSet, best_feature, value), labels, featLabels)return my_tree
7.构造注解树
获取叶节点的数目和树的层数
def get_num_leaves(my_tree):num_leaves = 0first_str = next(iter(my_tree))second_dict = my_tree[first_str]for key in second_dict.keys():#测试节点的数据类型是否为字典if type(second_dict[key]).__name__ == 'dict':num_leaves += get_num_leaves(second_dict[key])else:num_leaves += 1return num_leavesdef get_tree_depth(my_tree):max_depth = 0 firsr_str = next(iter(my_tree)) second_dict = my_tree[firsr_str]for key in second_dict.keys():if type(second_dict[key]).__name__ == 'dict': this_depth = 1 + get_tree_depth(second_dict[key])else:this_depth = 1if this_depth > max_depth:max_depth = this_depth return max_depth
8.使用决策树执行分类
def classify(input_tree, feat_labels, test_vec):# 获取决策树节点first_str = next(iter(input_tree))# 下一个字典second_dict = input_tree[first_str]feat_index = feat_labels.index(first_str)for key in second_dict.keys():if test_vec[feat_index] == key:if type(second_dict[key]).__name__ == 'dict':class_label = classify(second_dict[key], feat_labels, test_vec)else:class_label = second_dict[key]return class_label9.决策树的保存
def storeTree(input_tree, filename):# 存储树with open(filename, 'wb') as fw:pickle.dump(input_tree, fw)def grabTree(filename):# 读取树fr = open(filename, 'rb')return pickle.load(fr)
三、运行结果