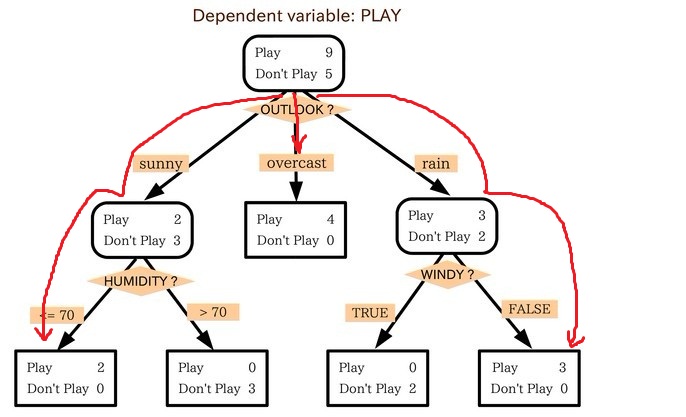
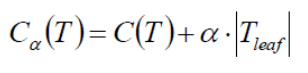决策树是最经常使用的数据挖掘算法,其核心是一个贪心算法,它采用自顶向下的递归方法构建决策树,下面是一个典型的决策树:
目前常用的决策树算法有ID3算法、改进的C4.5,C5.0算法和CART算法

ID3算法的核心是在决策树各级节点上选择属性时,用信息增益作为属性的选择标准,使得在每一个非节点进行测试时,能获得关于被测试记录最大的类别信息。
-
ID3的特点
优点:理论清晰,方法简单,学习能力较强
缺点:
(1) 信息增益的计算比较依赖于特征数目比较多的特征
(2) ID3为非递增算法
(3) ID3为单变量决策树
(4) 抗糙性差 -
熵和信息增益
设S是训练样本集,它包括n个类别的样本,这些方法用 C i {C_i} Ci表示,那么熵和信息增益用下面公式表示:
信息熵:
E ( S ) = − ∑ i = 0 n p i log 2 p i E(S) = - \sum\limits_{i = 0}^n {{p_i}{{\log }_2}{p_i}} E(S)=−i=0∑npilog2pi
其中 p i {p_i} pi表示 C i {C_i} Ci的概率
样本熵:
E A ( S ) = − ∑ j = 1 m ∣ S j ∣ ∣ S ∣ E ( S j ) E{_A}(S) = - \sum\limits_{j = 1}^m {\frac{{|{S_j}|}}{{|S|}}E({S_j})} EA(S)=−j=1∑m∣S∣∣Sj∣E(Sj)
其中 S i {S_i} Si表示根据属性A划分的 S {S} S的第 i {i} i个子集, S {S} S和 S i {S_i} Si表示样本数目
信息增益:
G a i n ( S , A ) = E ( S ) − E A ( S ) Gain(S,A) = E(S) - {E_A}(S) Gain(S,A)=E(S)−EA(S)
ID3中样本分布越均匀,它的信息熵就越大,所以其原则就是样本熵越小越好,也就是信息增益越大越好。 -
算法实例分析
| outlook | tem | hum | windy | play |
|---|---|---|---|---|
| overcast | hot | high | not | no |
| overcast | hot | high | very | no |
| overcast | hot | high | medium | no |
| sunny | hot | high | not | yes |
| sunny | hot | high | medium | yes |
| rain | mild | high | not | no |
| rain | mild | high | medium | no |
| rain | hot | normal | not | yes |
| rain | cool | normal | medium | no |
| rain | hot | normal | very | no |
| sunny | cool | normal | very | yes |
| sunny | cool | normal | medium | yes |
| overcast | mild | high | not | no |
| overcast | mild | high | medium | no |
| overcast | cool | normal | not | yes |
| overcast | cool | normal | medium | yes |
| rain | mild | normal | not | no |
| rain | mild | normal | medium | no |
| overcast | mild | normal | medium | yes |
| overcast | hot | normal | very | yes |
| sunny | mild | high | very | yes |
| sunny | mild | high | medium | yes |
| sunny | hot | normal | not | yes |
| rain | mild | high | very | no |
在上面的样本中,属于 y e s {yes} yes的结果有12个, n o {no} no有12个,于是根据上面的公式算出来训练集的熵为:
E ( S ) = − 12 24 log 2 12 24 − 12 24 log 2 12 24 = 1 E(S) = - \frac{12}{{24}}{\log _2}\frac{12}{{24}} - \frac{12}{{24}}{\log _2}\frac{12}{{24}} = 1 E(S)=−2412log22412−2412log22412=1
下面对属性outlook 、tem 、hum 、windy 计算对应的信息增益。

outlook将S划成三个部分:sunny、rain、overcast,如果用 S v {S_v} Sv表示属性为 v {v} v的样本集,就有 ∣ S s u n n y ∣ = 7 |{S_{sunny}}| = 7 ∣Ssunny∣=7, ∣ S o v e r c a s t ∣ = 9 |{S_{overcast}}| = 9 ∣Sovercast∣=9, ∣ S r a i n ∣ = 8 |{S_{rain}}| = 8 ∣Srain∣=8,而在 S s u n n y {S_{sunny}} Ssunny中,类 y e s {yes} yes的样本有7个,类 n o {no} no的样本有0个, S o v e r c a s t {S_{overcast}} Sovercast中,类 y e s {yes} yes的样本有4个,类 n o {no} no的样本有5个, S r a i n {S_{rain}} Srain中,类 y e s {yes} yes的样本有1个,类 n o {no} no的样本有7个,于是算出outlook的条件熵为:
E ( S , o u t l o o k ) = 7 24 ( − 7 7 log 2 7 7 − 0 ) + 9 24 ( − 4 9 log 2 4 9 − 5 9 log 2 5 9 ) + 8 24 ( − 1 8 log 2 1 8 − 7 8 log 2 7 8 ) = 0.5528 E(S,outlook) = \frac{7}{{24}}( - \frac{7}{7}{\log _2}\frac{7}{7} - 0) + \frac{9}{{24}}( - \frac{4}{9}{\log _2}\frac{4}{9} - \frac{5}{9}{\log _2}\frac{5}{9}) + \frac{8}{{24}}( - \frac{1}{8}{\log _2}\frac{1}{8} - \frac{7}{8}{\log _2}\frac{7}{8}) = 0.5528 E(S,outlook)=247(−77log277−0)+249(−94log294−95log295)+248(−81log281−87log287)=0.5528
G a i n ( S , o u t l o o k ) = 1 − 0.5528 = 0.4472 Gain(S,outlook) = 1 - 0.5528= 0.4472 Gain(S,outlook)=1−0.5528=0.4472
同理:
E ( S , t e m ) = 0.8893 E(S,tem) =0.8893 E(S,tem)=0.8893
G a i n ( S , t e m ) = 0.1107 Gain(S,tem) = 0.1107 Gain(S,tem)=0.1107
E ( S , h u m ) = 0.9183 E(S,hum) =0.9183 E(S,hum)=0.9183
G a i n ( S , h u m ) = 0.0817 Gain(S,hum) = 0.0817 Gain(S,hum)=0.0817
E ( S , w i n d y ) = 1 E(S,windy) =1 E(S,windy)=1
G a i n ( S , w i n d y ) = 0 Gain(S,windy) = 0 Gain(S,windy)=0
从上面可以看出outlook的信息增益最大,所以选择outlook作为根节点的测试属性,windy的信息增益为0,不能做出任何分类信息,产生第一次决策树,然后对每个叶节点再次利用上面的过程,生成最终的决策树。
- 代码分析:
了解了那么多理论,我们将上面根据天气打球的情况使用代码实现 (ID3)。
- 收集数据
利用 createDataSet() 函数输入数据,这里数据比较少,所以就不单独写个文件存放数据了。
def createDataSet():#outlook: 0 rain 1 overcast 2 sunny#tem: 0 cool 1 mild 2 hot#hum: 0 normal 1 high#windy 0 not 1 medium 2 very dataSet = [[1, 2, 1, 0, 'no'],[1, 2, 1, 2, 'no'],[1, 2, 1, 1, 'no'],[2, 2, 1, 0, 'yes'],[2, 2, 1, 1, 'yes'],[0, 1, 1, 0, 'no'],[0, 1, 1, 1, 'no'],[0, 2, 0, 0, 'yes'],[0, 0, 0, 1, 'no'],[0, 2, 0, 2, 'no'],[2, 0, 0, 2, 'yes'],[2, 0, 0, 1, 'yes'],[1, 1, 1, 0, 'no'],[1, 1, 1, 1, 'no'],[1, 0, 0, 0, 'yes'],[1, 0, 0, 1, 'yes'],[0, 1, 0, 0, 'no'],[0, 1, 0, 1, 'no'],[1, 1, 0, 1, 'yes'],[1, 2, 0, 2, 'yes'],[2, 1, 1, 2, 'yes'],[2, 1, 1, 1, 'yes'],[2, 2, 0, 0, 'yes'],[0, 1, 1, 2, 'no'],]return dataSet- 分析数据
计算数据集的香农熵的函数
def calcShannonEnt(dataSet):numEntries = len(dataSet) #获取数据的数目labelCounts = {}for featVec in dataSet:currentLable = featVec[-1] #取得最后一列数据,做为标签if currentLable not in labelCounts.keys(): #获取不同标签的数目labelCounts[currentLable] = 0labelCounts[currentLable] += 1#计算熵Ent = 0.0for key in labelCounts:prob = float(labelCounts[key]) / numEntriesEnt -= prob * log(prob, 2)#print ("信息熵: ", Ent)return Ent按照给定特征划分数据集
def splitDataSet(dataSet, axis, value):retDataSet = [] for featVec in dataSet:if featVec[axis] == value: #每行中第axis个元素和value相等(去除第axis个数据)reducedFeatVec = featVec[:axis]reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec)return retDataSet #返回分类后的新矩阵选择最好的数据集划分方式
#根据香农熵,选择最优的划分方式 #根据某一属性划分后,类标签香农熵越低,效果越好
def chooseBestFeatureToSplit(dataSet):baseEntropy = calcShannonEnt(dataSet) #计算数据集的香农熵numFeatures = len(dataSet[0]) - 1bestInfoGain = 0.0 #最大信息增益bestFeature = 0 #最优特征for i in range(0, numFeatures):featList = [example[i] for example in dataSet] #所有子列表(每行)的第i个元素,组成一个新的列表uniqueVals = set(featList)newEntorpy = 0.0for value in uniqueVals: #数据集根据第i个属性进行划分,计算划分后数据集的香农熵subDataSet = splitDataSet(dataSet, i, value)prob = len(subDataSet)/float(len(dataSet))newEntorpy += prob*calcShannonEnt(subDataSet)infoGain = baseEntropy-newEntorpy #划分后的数据集,香农熵越小越好,即信息增益越大越好if(infoGain > bestInfoGain):bestInfoGain = infoGainbestFeature = ireturn bestFeature- 训练算法
#如果数据集已经处理了所有属性,但叶子结点中类标签依然不是唯一的,此时需要决定如何定义该叶子结点。这种情况下,采用多数表决方法,对该叶子结点进行分类
def majorityCnt(classList): classCount = {}for vote in classList:if vote not in classCount.keys():classCount[vote] = 0classCount[vote] += 1sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)return sortedClassCount[0][0]def createTree(dataSet, labels): #创建树classList = [example[-1] for example in dataSet] #数据集样本的类标签if classList.count(classList[0]) == len(classList): #如果数据集样本属于同一类,说明该叶子结点划分完毕return classList[0]if len(dataSet[0]) == 1: #如果数据集样本只有一列(该列是类标签),说明所有属性都划分完毕,则根据多数表决方法,对该叶子结点进行分类return majorityCnt(classList)bestFeat = chooseBestFeatureToSplit(dataSet) #根据香农熵,选择最优的划分方式bestFeatLabel = labels[bestFeat] #记录该属性标签myTree = {bestFeatLabel:{}} #树del(labels[bestFeat]) #在属性标签中删除该属性#根据最优属性构建树featValues = [example[bestFeat] for example in dataSet]uniqueVals = set(featValues)for value in uniqueVals:subLabels = labels[:]subDataSet = splitDataSet(dataSet, bestFeat, value)myTree[bestFeatLabel][value] = createTree(subDataSet, subLabels)print ("myTree:", myTree)return myTree- 分类
#测试算法:使用决策树,对待分类样本进行分类
def classify(inputTree, featLabels, testVec): #传入参数:决策树,属性标签,待分类样本firstStr = list(inputTree.keys())[0] #树根代表的属性secondDict = inputTree[firstStr]featIndex = featLabels.index(firstStr) #树根代表的属性,所在属性标签中的位置,即第几个属性for key in secondDict.keys():if testVec[featIndex] == key:if type(secondDict[key]).__name__ == 'dict':classLabel = classify(secondDict[key], featLabels, testVec)else:classLabel = secondDict[key]return classLabel- 测试
if __name__ == '__main__':dataSet = createDataSet()labels = ['outlook', 'tem', 'hum', 'windy']labelsForCreateTree = labels[:]Tree = createTree(dataSet, labelsForCreateTree )testvec = [2, 2, 1, 0]print (classify(Tree, labels, testvec))

最终产生的决策树为:

决策树有分类和回归两种功能,分别调用下面的两个库函数,如下所示:
from sklearn import datasetsfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifier # 分类from sklearn.tree import DecisionTreeRegressor # 回归iris = datasets.load_iris() # 加载iris数据集X = iris.datay = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)clf = DecisionTreeClassifier()clf.fit(X_train, y_train)ans = clf.predict(X_test)# 计算准确率cnt = 0for i in range(len(y_test)):if ans[i] - y_test[i] < 1e-1:cnt += 1print("准确率: ", (cnt * 100.0 / len(y_test)),"%")