决策树(Decision Tree)是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规 则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。决策树算法容易理解,适用各种数据,在解决各 种问题时都有良好表现,尤其是以树模型为核心的各种集成算法,在各个行业和领域都有广泛的应用。
几乎所有决策树有关的模型调整方法,都围绕这两个问题展开。这两个问题背后的原理十分复杂,我们会在讲解模型参数和属性的时候为大家简单解释涉及到的部分。
文章目录
- 1、构建一棵树决策树
- 2、确定最优的剪枝参数
- 3、交叉验证
- 4 实践
- 4.1 构建一棵决策树
- 4.2确定最优的剪枝参数
- 4.3 交叉验证
1、构建一棵树决策树
决策树算法的本质是一种图结构,我们只需要问一系列问题就可以对数据进行分类了。
我们需要导入数据并查看数据的属性,基于导入的数据构建一棵简单的决策树来对数据进行分类,并查看各个特征的重要性。
现在我们就以scikit-learn中的红酒数据集为例,我们获取红酒数据集的特征矩阵以及标签,特征矩阵包括178个数据项,13个特征点,我们可以分析这13个特征点来对红酒进行分类。因此我们构建决策树模型,通过对决策树模型进行建模,训练,最终可以用训练好的模型预测红酒种类。从结果我们可以知道得知训练的准确度,准确度在0~1之间,越高越好。以及13个特征的重要程度,13个特征之和为1,数值表示所占比重。
1、导入需要的算法库和模块以及数据集
2、实例化数据集
3、查看数据集属性
4、划分数据
5、建立模型
6、训练模型
7、计算准确度
8、查看特征的重要性
2、确定最优的剪枝参数
在不加限制的情况下,一棵决策树会生长到衡量不纯度的指标最优,或者没有更多的特征可用为止。这样的决策树往往会过拟合,这就是说,它会在训练集上表现很好,在测试集上却表现糟糕。我们收集的样本数据不可能和整体的状况完全一致,因此当一棵决策树对训练数据有了过于优秀的解释性,它找出的规则必然包含了训练样本中的噪声,并使它对未知数据的拟合程度不足。
为了让决策树有更好的泛化性,我们要对决策树进行剪枝。剪枝策略对决策树的影响巨大,正确的剪枝策略是优化决策树算法的核心,sklearn为我们提供了不同的剪枝策略:
1、max_depth:
限制树的最大深度,超过设定深度的树枝全部剪掉。这是用得最广泛的剪枝参数,在高维度低样本量时非常有效。决策树多生长一层,对样本量的需求会增加一倍,所以限制树深度能够有效地限制过拟合。在集成算法中也非常实用。实际使用时,建议从max_depth=3开始尝试,看看拟合的效果再决定是否增加设定深度。
2、min_samples_leaf和min_samples_split:
min_samples_leaf限定一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生,或者,分枝会朝着满足每个子节点都包含min_samples_leaf个样本的方向去发生一般搭配max_depth使用。一般来说,建议从min_samples_leaf=5开始使用。对于类别不多的分类问题,min_samples_leaf=1通常就是最佳选择。
min_samples_split限定一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则分枝就不会发生。
那具体怎么来确定每个参数填写什么值呢?这时候,我们就要使用确定超参数的曲线来进行判断了。
超参数的学习曲线,是一条以超参数的取值为横坐标,模型的度量指标为纵坐标的曲线,它是用来衡量不同超参数取值下模型的表现的线。在我们建好的决策树里,我们的模型度量指标就是score。
我们依然是以红酒数据集为例,实例化数据,并建模,最终通过学习曲线选取最佳超参数,通过查看曲线的最大值,也就是最高精度,确定最佳超参数值。
1、导入需要的算法库和模块以及数据集
2、实例化数据集
3、划分数据
4、建立模型
5、训练模型
6、计算准确度
7、可视化超参数学习曲线
3、交叉验证
交叉验证是用来观察模型的稳定性的一种方法,我们将数据划分为n份,依次使用其中一份作为测试集,其他n-1份作为训练集,多次计算模型的精确性来评估模型的平均准确程度。训练集和测试集的划分会干扰模型的结果,因此用交叉验证n次的结果求出的平均值,是对模型效果的一个更好的度量。
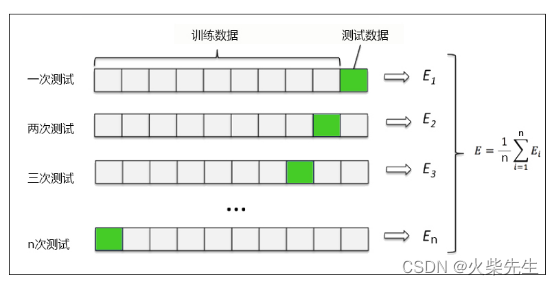
在机器学习任务中,拿到数据后,我们首先会将原始数据集分为三部分:训练集、验证集和测试集。训练集用于训练模型,验证集用于模型的参数选择配置,测试集对于模型来说是未知数据,用于评估模型的泛化能力。这个方法操作简单,只需随机把原始数据分为三组即可。
不过如果只做一次分割,它对训练集、验证集和测试集的样本数比例,还有分割后数据的分布是否和原始数据集的分布相同等因素比较敏感,不同的划分会得到不同的最优模型,而且分成三个集合后,用于训练的数据更少了。于是有了k折交叉验证(k-fold cross validation)加以改进,
优点是训练集的样本总数和原数据集一样都是,并且仍有约1/3的数据不被训练而可以作为测试集。
我们依然是以红酒数据集为例,实例化数据,并建模,最终通过交叉验证得到模型的预测精度,精度范围在0~1之间,越高越好。
1、导入需要的算法库和模块以及数据集
2、实例化数据集
3、建立模型
4、交叉验证
4 实践
4.1 构建一棵决策树
# 1、导入需要的算法库和模块以及数据集
# 2、实例化数据集
# 3、查看数据集属性
# 4、划分数据
# 5、建立模型
# 6、训练模型
# 7、计算准确度
# 8、查看特征的重要性from sklearn.datasets import load_wine # 红酒数据集
from sklearn import tree # 决策树
from sklearn.model_selection import train_test_split # 划分训练集和测试集wine = load_wine() # 实例化数据集
print(wine.data.shape) # 特征矩阵
print(wine.target) # 标签Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data, wine.target, test_size=0.3) # 将数据集的30%划分为测试集,其他的划分为训练集
clf = tree.DecisionTreeClassifier(criterion="entropy") # 实例化树模型
clf = clf.fit(Xtrain, Ytrain) # 训练树模型
score = clf.score(Xtest, Ytest) # 返回预测的准确度
print("准确度:", score)
print("特征的重要性:", clf.feature_importances_) # 查看特征的重要性
4.2确定最优的剪枝参数
# 1、导入需要的算法库和模块以及数据集
# 2、实例化数据集
# 3、划分数据
# 4、建立模型
# 5、训练模型
# 6、计算准确度
# 7、可视化超参数学习曲线from sklearn.datasets import load_wine # 红酒数据集
from sklearn import tree # 决策树
from sklearn.model_selection import train_test_split # 划分训练集和测试集
import matplotlib.pyplot as pltwine = load_wine() # 实例化数据集Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data, wine.target, test_size=0.3) # 将数据集的30%划分为测试集,其他的划分为训练集
# 确认最优的剪枝参数
test = [] # 保存不同max_depth下计算得到的精度
for i in range(10):clf = tree.DecisionTreeClassifier(max_depth=i + 1, criterion="entropy", random_state=30,splitter="random") # 实例化树模型clf = clf.fit(Xtrain, Ytrain) # 训练树模型score = clf.score(Xtest, Ytest) # 训练集上的准确度test.append(score)
print("最高精度为:", max(test), "所对应的树的深度:", test.index(max(test)) + 1) # 输出最高精度以及所对应的树的深度
# 可视化
plt.plot(range(1, 11), test, color="red", label="max_depth")
plt.legend() # 显示标签
plt.savefig("2.png")
4.3 交叉验证
from sklearn import tree # 决策树
from sklearn.datasets import load_wine # 红酒数据集
from sklearn.model_selection import cross_val_score # 交叉验证
import matplotlib.pyplot as plt # 可视化工具包wine = load_wine() # 实例化数据集clf = tree.DecisionTreeClassifier(criterion="entropy") # 实例化树模型clf_s = cross_val_score(clf, wine.data, wine.target, cv=10) # 进行10次交叉验证得到每一次的准确度
print(clf_s) # 十次交叉验证的结果
print(clf_s.mean()) # 十次交叉验证的平均值# 利用交叉验证确认最优的剪枝参数
test = [] # 保存不同max_depth下计算得到的精度
for i in range(10): # 构建200次不同规模的随机森林(n_estimators表示随机森林含有多少课随机树)clf = tree.DecisionTreeClassifier(max_depth=i + 1, criterion="entropy", random_state=0,splitter="random") # 实例化树模型rfc_s = cross_val_score(clf, wine.data, wine.target, cv=10).mean() # 进行10次交叉验证得到准确度的平均值test.append(rfc_s) # 将结果加入数组中
print("最高精度为:", max(test), "所对应的随机森林规模为:", test.index(max(test)) + 1) # 输出最高精度以及所对应的最佳max_depth# 可视化
plt.plot(range(1, 11), test, color="red", label="max_depth")
plt.legend() # 显示标签
plt.savefig("3.png")