谱聚类
1. 基本原理
它的主要思想:把所有数据看成空间中的点,这些点之间可以用变连接起来,距离较远的两个点之间的边权重较低,而距离较近的两个点之间的权重较高,通过对所有数据点组成的图进行切图,让切图后的不同的子图间边权重和尽可能小(即距离远),而子图内的边权重和尽可能高(即距离近)。
难点:
- 如何构建图?
- 如何切分图?
2. 谱聚类基础
2.1 无向权重图
对于一个图 G G G,我们一般用点集合 V = { v 1 , v 2 , . . . . , v n } V=\{v_1,v_2,....,v_n\} V={v1,v2,....,vn}和边集合 E E E来描述,即 G = ( V , E ) G=(V,E) G=(V,E)。我们定义权重 w i j w_{ij} wij为点 v i , v j v_i,v_j vi,vj之间的权重,由于是无向图,故 w i j = w j i w_{ij}=w_{ji} wij=wji。
对于有边连接的两个点 v i 和 v j v_i和v_j vi和vj, w i j > 0 w_{ij} > 0 wij>0;对于没有边连接的两个点 v i 和 v j v_i和v_j vi和vj, w i j = 0 w_{ij} = 0 wij=0。
对于图中的任意一个点 v i v_i vi,它的度 d i d_i di定义为和它相连的所有边权重之和,即
d i = ∑ j = 1 n w i j d_i=\sum_{j=1}^nw_{ij} di=j=1∑nwij
利用每个点度的定义,我们可以得到一个 n × n n \times n n×n的度矩阵 D D D,它是一个对角阵,只有主对角有值,对应第 i i i行为第 i i i个点的度;利用所有点之间的权重,我们可以得到图的邻接矩阵 W W W,它也是一个 n × n n \times n n×n矩阵,第 i i i行的第 j j j个值对应权重 w i j w_{ij} wij
除此之外,对于点集 V V V的一个子集 A ⊂ V A \subset V A⊂V,我们定义:
∣ A ∣ : = 子 集 A 中 点 的 个 数 v o l ( A ) : = ∑ i ∈ A d i |A|:=子集A中点的个数 \\ vol(A):=\sum_{i \in A}d_i ∣A∣:=子集A中点的个数vol(A):=i∈A∑di
2.2 拉普拉斯矩阵
拉普拉斯矩阵 L = D − W L=D-W L=D−W,其性质如下:
- 对称矩阵,由于 D 和 W D和W D和W都为对称矩阵
- 由于是对称矩阵,它的所有特征值都是实数
- 对于任意向量 f f f,有
f T L f = f T D f − f T W f = ∑ i = 1 n d i f i 2 − ∑ i , j = 1 n w i j f i f j = 1 2 ( ∑ i = 1 n d i f i 2 − 2 ∑ i , j = 1 n w i j f i f j + ∑ j = 1 n d j f j 2 ) = 1 2 ∑ i , j = 1 n w i j ( f i − f j ) 2 f^TLf=f^TDf-f^TWf=\sum_{i=1}^nd_if_i^2-\sum_{i,j=1}^nw_{ij}f_if_j\\=\frac {1} {2}(\sum_{i=1}^nd_if_i^2-2\sum_{i,j=1}^nw_{ij}f_if_j+\sum_{j=1}^nd_jf_j^2)=\frac {1} {2}\sum_{i,j=1}^nw_{ij}(f_i-f_j)^2 fTLf=fTDf−fTWf=i=1∑ndifi2−i,j=1∑nwijfifj=21(i=1∑ndifi2−2i,j=1∑nwijfifj+j=1∑ndjfj2)=21i,j=1∑nwij(fi−fj)2 - 由于拉普拉斯矩阵是半正定的,其对应的 n n n个特征值都大于等于0。
3. 构建图——构建邻接矩阵
3.1 ϵ \epsilon ϵ邻近法
通过设置一个阈值 ϵ \epsilon ϵ,然后利用欧氏距离 s i j s_{ij} sij度量任意两点 v i 和 v j v_i和v_j vi和vj的距离,即 s i j = ∣ ∣ v i − v j ∣ ∣ 2 2 s_{ij}=||v_i-v_j||_2^2 sij=∣∣vi−vj∣∣22,然后根据 s i j 和 ϵ s_{ij}和\epsilon sij和ϵ的大小关系,来定义邻接矩阵 W W W:
w i j = { 0 , s i j > ϵ ϵ , s i j ≤ ϵ w_{ij}= \begin{cases} 0, \quad & s_{ij} >\epsilon \\ \epsilon, \quad & s_{ij} \leq \epsilon \end{cases} wij={0,ϵ,sij>ϵsij≤ϵ
从上式可知,两点间的权重要么 ϵ \epsilon ϵ,要么0,就没有其他信息了,距离远近度量很不明确,因此在实际应用中,很少采用。
3.2 k k k近邻法
利用KNN算法遍历所有的样本点,取每个样本最近的 k k k个点作为近邻,只有和样本距离最近的 k k k个点之间的 w i j > 0 w_{ij}>0 wij>0。但是这种方法会造成重构之后的邻接矩阵 W W W非对称,我们后面的算法需要邻接矩阵对称。为了解决这种问题,一般采取下面两种方法之一:
- 只要一个点在另一个点的K近邻中,就保留 w i j w_{ij} wij
w i j = w j i = { 0 v i ∉ K N N ( v j ) a n d v j ∉ K N N ( v i ) e x p ( − ∣ ∣ v i − x j ∣ ∣ 2 2 2 σ 2 ) v i ∈ K N N ( v j ) o r v j ∈ K N N ( v i ) w_{ij}=w_{ji}= \begin{cases} 0 & v_i \notin KNN(v_j) \quad and \quad v_j \notin KNN(v_i) \\ exp(-\frac {||v_i-x_j||_2^2} {2\sigma^2}) & v_i \in KNN(v_j) \quad or \quad v_j \in KNN(v_i) \end{cases} wij=wji={0exp(−2σ2∣∣vi−xj∣∣22)vi∈/KNN(vj)andvj∈/KNN(vi)vi∈KNN(vj)orvj∈KNN(vi) - 必须两个点互为 K K K近邻中,才能保留 w i j w_{ij} wij
w i j = w j i = { 0 v i ∉ K N N ( v j ) o r v j ∉ K N N ( v i ) e x p ( − ∣ ∣ v i − x j ∣ ∣ 2 2 2 σ 2 ) v i ∈ K N N ( v j ) a n d v j ∈ K N N ( v i ) w_{ij}=w_{ji}= \begin{cases} 0 & v_i \notin KNN(v_j) \quad or \quad v_j \notin KNN(v_i) \\ exp(-\frac {||v_i-x_j||_2^2} {2\sigma^2}) & v_i \in KNN(v_j) \quad and \quad v_j \in KNN(v_i) \end{cases} wij=wji={0exp(−2σ2∣∣vi−xj∣∣22)vi∈/KNN(vj)orvj∈/KNN(vi)vi∈KNN(vj)andvj∈KNN(vi)
3.3 全连接法
比前两种方法,第三种方法所有的点之间的权重值都大于0,因此称之为全连接法。可以选择不同的核函数来定义边权重,常用的有多项式核函数,高斯核函数和Sigmoid核函数。最常用的是高斯核函数RBF
w i j = e x p ( − ∣ ∣ v i − v j ∣ ∣ 2 2 2 σ 2 ) w_{ij}=exp(-\frac {||v_i-v_j||_2^2} {2\sigma^2}) wij=exp(−2σ2∣∣vi−vj∣∣22)
在实际的应用中,使用第三种全连接法来建立邻接矩阵是最普遍的,而在全连接法中使用高斯径向核RBF是最普遍的。
4. 图的切分
对于无向图 G G G的切分,我们的目标是将图 G ( V , E ) G(V,E) G(V,E)切成相互没有连接的 k k k个子图,每个子图集合为: A 1 , A 2 , . . . , A k A_1,A_2,...,A_k A1,A2,...,Ak,它们满足 A i ∩ A j = ∅ 且 A 1 ∪ A 2 ∪ . . . ∪ A k = V A_i \cap A_j=\varnothing 且 A_1 \cup A_2 \cup ...\cup A_k=V Ai∩Aj=∅且A1∪A2∪...∪Ak=V
对于任意两个子图点的集合 A , B ⊂ V , A ∩ B = ∅ A,B \subset V, A \cap B=\varnothing A,B⊂V,A∩B=∅,我们定义 A 和 B A和B A和B之间的切图权重为:
W ( A , B ) = ∑ i ∈ A , j ∈ B w i j W(A,B)=\sum_{i\in A,j\in B}w_{ij} W(A,B)=i∈A,j∈B∑wij
那么对于我们 k k k个子图点的集合: A 1 , A 2 , . . . , A k A_1,A_2,...,A_k A1,A2,...,Ak,我们定义切图 c u t cut cut为:
c u t ( A 1 , A 2 , . . . , A k ) = 1 2 ∑ i = 1 k W ( A i , A ˉ i ) cut(A_1,A_2,...,A_k)=\frac {1} {2}\sum_{i=1}^kW(A_i, \bar A_i) cut(A1,A2,...,Ak)=21i=1∑kW(Ai,Aˉi)
其中 A ˉ i \bar A_i Aˉi为 A i A_i Ai的补集
那么如何切图可以让子图内的点权重和高,子图间的点权重和低呢?
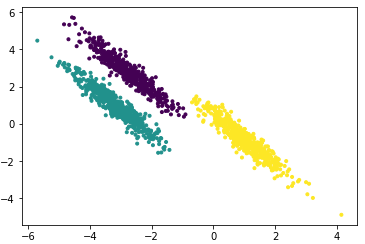
一个自然的想法就是最小化 c u t ( A 1 , A 2 , . . . A k ) cut(A_1,A_2,...A_k) cut(A1,A2,...Ak), 但是可以发现,这种极小化的切图存在问题,如下图:

为了避免最小切图导致的切图效果不佳,我们需要对每个子图的规模做出限定,一般来说,有两种切图方式,第一种是 R a t i o C u t RatioCut RatioCut,第二种是 N c u t Ncut Ncut。
4.1 R a t i o C u t RatioCut RatioCut切图
对于每个切图,不仅要考虑最小化 c u t ( A 1 , A 2 , . . . , A k ) cut(A_1,A_2,...,A_k) cut(A1,A2,...,Ak),还要考虑最大化每个子图样本的个数,即最小化 R a t i o C u t RatioCut RatioCut函数:
R a t i o C u t ( A 1 , A 2 , . . . , A k ) = 1 2 ∑ i = 1 k W ( A i , A ˉ i ) ∣ A i ∣ RatioCut(A_1,A_2,...,A_k)=\frac {1} {2}\sum_{i=1}^k\frac {W(A_i, \bar A_i)}{|A_i|} RatioCut(A1,A2,...,Ak)=21i=1∑k∣Ai∣W(Ai,Aˉi)
我们引入指示向量 h j ∈ { h 1 , h 2 , . . . , h k } h_j\in \{h_1,h_2,...,h_k\} hj∈{h1,h2,...,hk},对于任意一个向量 h j = ( h 1 , j , h 2 , j , . . . , h n , j ) T h_j=(h_{1,j},h_{2,j},...,h_{n,j})^T hj=(h1,j,h2,j,...,hn,j)T,它是一个 n n n维向量( n n n为样本数),我们定义 h i j h_{ij} hij为:
h i j = { 0 v i ∉ A j 1 ∣ A j ∣ v i ∈ A j h_{ij}= \begin{cases} 0 & v_i \notin A_j \\ \frac {1} {|A_j|} & v_i \in A_j \end{cases} hij={0∣Aj∣1vi∈/Ajvi∈Aj
对于 h i T L h i h_i^TLh_i hiTLhi有:
h i T L h i = 1 2 ∑ m = 1 ∑ n = 1 w m n ( h m , i − h n , i ) 2 = 1 2 ( ∑ m ∈ A i , n ∉ A i w m n ( 1 ∣ A i ∣ − 0 ) 2 + ∑ m ∉ A i , n ∈ A i w m n ( 0 − 1 ∣ A i ∣ ) 2 ) = 1 2 ( ∑ m ∈ A i , n ∉ A i w m n 1 ∣ A i ∣ + ∑ m ∉ A i , n ∈ A i w m n 1 ∣ A i ∣ ) = 1 2 ( c u t ( A i , A ˉ i ) 1 ∣ A i ∣ + c u t ( A i , A ˉ i ) 1 ∣ A i ∣ ) = c u t ( A i , A ˉ i ) ∣ A i ∣ h_i^TLh_i=\frac {1} {2}\sum_{m=1}\sum_{n=1}w_{mn}(h_{m,i}-h_{n,i})^2 \\ =\frac {1}{2}(\sum_{m \in A_i, n \notin A_i}w_{mn}(\frac {1}{\sqrt {|A_i|}}-0)^2+\sum_{m \notin A_i, n \in A_i}w_{mn}(0-\frac {1} {\sqrt {|A_i|}})^2)\\=\frac {1}{2}(\sum_{m \in A_i,n \notin A_i}w_{mn}\frac {1}{|A_i|}+\sum_{m \notin A_i,n \in A_i}w_{mn}\frac {1}{|A_i|})\\=\frac {1}{2}(cut(A_i,\bar A_i)\frac{1}{|A_i|}+cut(A_i,\bar A_i)\frac{1}{|A_i|})=\frac {cut(A_i,\bar A_i)} {|A_i|} hiTLhi=21m=1∑n=1∑wmn(hm,i−hn,i)2=21(m∈Ai,n∈/Ai∑wmn(∣Ai∣1−0)2+m∈/Ai,n∈Ai∑wmn(0−∣Ai∣1)2)=21(m∈Ai,n∈/Ai∑wmn∣Ai∣1+m∈/Ai,n∈Ai∑wmn∣Ai∣1)=21(cut(Ai,Aˉi)∣Ai∣1+cut(Ai,Aˉi)∣Ai∣1)=∣Ai∣cut(Ai,Aˉi)
由上式可知, R a t i o C u t RatioCut RatioCut函数表达式可改写为:
R a t i o C u t ( A 1 , A 2 , . . . , A k ) = ∑ i = 1 k h i T L h i = ∑ i = 1 k ( H T L H ) i i = t r ( H T L H ) RatioCut(A_1,A_2,...,A_k)=\sum_{i=1}^kh_i^TLh_i=\sum_{i=1}^k(H^TLH)_{ii}=tr(H^TLH) RatioCut(A1,A2,...,Ak)=i=1∑khiTLhi=i=1∑k(HTLH)ii=tr(HTLH)
其中 t r ( H T L H ) tr(H^TLH) tr(HTLH)为矩阵的迹,即我们的 R a t i o C u t RatioCut RatioCut切图,实际上是最小化迹 t r ( H T L H ) tr(H^TLH) tr(HTLH)。注意到 H T H = I H^TH=I HTH=I,则我们的优化目标为:
a r g min H t r ( H T L H ) s . t . H T H = I arg\min_{H}tr(H^TLH)\\s.t. \quad H^TH=I argHmintr(HTLH)s.t.HTH=I
注意观察 t r ( H T L H ) tr(H^TLH) tr(HTLH)的每一个优化子目标 h i T L h i h_i^TLh_i hiTLhi,其中 h i h_i hi是单位正交基, L L L是对称矩阵,此时 h i T L h i h_i^TLh_i hiTLhi是矩阵 L L L的一个特征值。对于 h i T L h i h_i^TLh_i hiTLhi,我们的目标是找到矩阵 L L L的最小特征值,而对于 t r ( H T L H ) = ∑ i = 1 k h i T L h i tr(H^TLH)=\sum_{i=1}^kh_i^TLh_i tr(HTLH)=∑i=1khiTLhi,我们的目标就是找到矩阵 L L L的 k k k个最小特征值。
4.2 N c u t Ncut Ncut切图
N c u t Ncut Ncut切图与 R a t i o Ratio Ratio切图类似,只是将 R a t i o C u t RatioCut RatioCut的分母 ∣ A i ∣ |A_i| ∣Ai∣换成 v o l ( A i ) vol(A_i) vol(Ai)。由于子图样本的个数多不一定权重就大,我们切图时基于权重也更符合我们的目标,因此一般来说 N c u t Ncut Ncut优于 R a t i o C u t RatioCut RatioCut,定义如下:
N c u t ( A 1 , A 2 , . . . , A k ) = 1 2 ∑ i = 1 k W ( A i , A ˉ i ) v o l ( A i ) Ncut(A_1,A_2,...,A_k)=\frac {1} {2}\sum_{i=1}^k\frac {W(A_i,\bar A_i)}{vol(A_i)} Ncut(A1,A2,...,Ak)=21i=1∑kvol(Ai)W(Ai,Aˉi)
对应的, N c u t Ncut Ncut切图对指示向量 h h h做了改进,定义如下:
h i j = { 0 v i ∉ A j 1 v o l ( A j ) v i ∈ A j h_{ij}= \begin{cases} 0 & v_i \notin A_j \\ \frac {1} {\sqrt {vol(A_j)}} & v_i \in A_j \end{cases} hij={0vol(Aj)1vi∈/Ajvi∈Aj
我们的优化目标依然是:(推导与 R a t i o C u t RatioCut RatioCut完全一致)
N c u t ( A 1 , A 2 , . . . , A k ) = ∑ i = 1 k h i T L h i = ∑ i = 1 k ( H T L H ) i i = t r ( H T L H ) Ncut(A_1,A_2,...,A_k)=\sum_{i=1}^kh_i^TLh_i=\sum_{i=1}^k(H^TLH)_{ii}=tr(H^TLH) Ncut(A1,A2,...,Ak)=i=1∑khiTLhi=i=1∑k(HTLH)ii=tr(HTLH)
但是此时我们的 H T H ≠ I H^TH \not=I HTH=I,而是 H T D H = I H^TDH=I HTDH=I。推导如下:
h i T D h i = ∑ j = 1 n h j i 2 d j = ∑ j ∈ A i 1 v o l ( A i ) d j = 1 v o l ( A i ) ∑ j ∈ A i d j = 1 v o l ( A i ) v o l ( A i ) = 1 h_i^TDh_i=\sum_{j=1}^nh_{ji}^2d_j=\sum_{j \in A_i}\frac {1} {vol(A_i)}d_j=\frac {1} {vol(A_i)}\sum_{j \in A_i}d_j=\frac {1} {vol(A_i)}vol(A_i)=1 hiTDhi=j=1∑nhji2dj=j∈Ai∑vol(Ai)1dj=vol(Ai)1j∈Ai∑dj=vol(Ai)1vol(Ai)=1
也就是说,我们的优化目标最终为:
a r g min H t r ( H T L H ) s . t . H T D H = I arg\min_{H}tr(H^TLH) \\ s.t. \quad H^TDH=I argHmintr(HTLH)s.t.HTDH=I
此时我们的 H H H中的指示向量 h h h不是单位正交基,所以我们令 H = D − 1 2 F H=D^{-\frac {1} {2}}F H=D−21F,则 H T L H = F T D − 1 2 L D − 1 2 F , H T D H = F T F = I H^TLH=F^TD^{-\frac {1}{2}}LD^{-\frac {1}{2}}F,H^TDH=F^TF=I HTLH=FTD−21LD−21F,HTDH=FTF=I,也就是优化目标变成了:
a r g min F t r ( F T D − 1 2 L D − 1 2 F ) s . t . F T F = I arg\min_{F}tr(F^TD^{-\frac {1}{2}}LD^{-\frac {1}{2}}F) \\ s.t. \quad F^TF=I argFmintr(FTD−21LD−21F)s.t.FTF=I
可以发现这个式子和 R a t i o C u t RatioCut RatioCut基本一致,只是中间的 L L L变成了 D − 1 2 L D − 1 2 D^{-\frac {1}{2}}LD^{-\frac {1}{2}} D−21LD−21。这样,我们可以按照 R a t i o C u t RatioCut RatioCut的思想,求出 D − 1 2 L D − 1 2 D^{-\frac {1}{2}}LD^{-\frac {1}{2}} D−21LD−21的 k k k个最小特征值
一般来说, D − 1 2 L D − 1 2 D^{-\frac {1}{2}}LD^{-\frac {1}{2}} D−21LD−21相当于对拉普拉斯矩阵 L L L做了一次标准化,即 L i j d i ⋅ d j \frac {L_{ij}}{\sqrt {d_i \cdot d_j}} di⋅djLij
5. 谱聚类算法流程
输 入 : 样 本 集 D = ( x 1 , x 2 , . . . , x n ) , 邻 接 矩 阵 的 生 成 方 式 , 降 维 后 的 维 度 k 1 , 聚 类 方 法 , 聚 类 后 的 维 度 k 2 输入:样本集D=(x_1,x_2,...,x_n),邻接矩阵的生成方式, 降维后的维度k_1, 聚类方法,聚类后的维度k_2 输入:样本集D=(x1,x2,...,xn),邻接矩阵的生成方式,降维后的维度k1,聚类方法,聚类后的维度k2
输 出 : 簇 划 分 C ( c 1 , c 2 , . . . c k 2 ) 输出: 簇划分C(c_1,c_2,...c_{k_2}) 输出:簇划分C(c1,c2,...ck2)
- 根据邻接矩阵生成方式构建邻接矩阵 W W W,构建度矩阵 D D D
- 计算出拉普拉斯矩阵 L L L
- 构建标准化后的拉普拉斯矩阵 D − 1 2 L D − 1 2 D^{-\frac {1}{2}}LD^{-\frac {1}{2}} D−21LD−21
- 计算 D − 1 2 L D − 1 2 D^{-\frac {1}{2}}LD^{-\frac {1}{2}} D−21LD−21最小的 k 1 k_1 k1个特征值所各自对应的特征向量 f f f
- 将各自对应的特征向量 f f f组成的矩阵按行标准化,最终组成 n × k 1 n \times k_1 n×k1维矩阵 F F F
- 对 F F F中的每一行作为一个 k 1 k_1 k1维样本,共 n n n个样本,用输入的聚类方法进行聚类,聚类维数为 k 2 k_2 k2
- 得到簇划分 C ( c 1 , c 2 , . . . c k 2 ) C(c_1,c_2,...c_{k_2}) C(c1,c2,...ck2)
6. 实例演示
import numpy as np
import matplotlib.pyplot as plt from sklearn import cluster, datasets
from sklearn.preprocessing import StandardScalernp.random.seed(0)# 构建数据
n_samples = 1500
noisy_circles = datasets.make_circles(n_samples=n_samples, factor=0.5, noise=0.05)
noisy_moons = datasets.make_moons(n_samples=n_samples, noise=0.05)
blobs = datasets.make_blobs(n_samples=n_samples, random_state=8)data_sets = [(noisy_circles,{"n_clusters": 2}),(noisy_moons,{"n_clusters": 2}), (blobs, {"n_clusters": 3})
]
colors = ["#377eb8", "#ff7f00", "#4daf4a"]
affinity_list = ['rbf', 'nearest_neighbors']plt.figure(figsize=(17, 10))for i_dataset, (dataset, algo_params) in enumerate(data_sets):# 模型参数params = algo_params# 数据X, y = datasetX = StandardScaler().fit_transform(X)for i_affinity, affinity_strategy in enumerate(affinity_list):# 创建SpectralClusterspectral = cluster.SpectralClustering(n_clusters=params['n_clusters'],eigen_solver='arpack', affinity=affinity_strategy)# 训练spectral.fit(X)# 预测y_pred = spectral.labels_.astype(int)y_pred_colors = []for i in y_pred:y_pred_colors.append(colors[i])plt.subplot(3, 4, 4*i_dataset+i_affinity+1)plt.title(affinity_strategy)plt.scatter(X[:, 0], X[:, 1], color=y_pred_colors)plt.show()

7. 谱聚类算法小结
优点:
- 谱聚类只需要数据之间的邻接矩阵,因此对于处理稀疏数据的聚类很有效。这点传统聚类算法比如
K-Means很难做到 - 由于使用了降维,因此在处理高维数据聚类时的复杂度比传统聚类算法好
缺点:
- 如果最终聚类的维度非常高,则由于降维的幅度不够,谱聚类的运行速度和最后的聚类效果均不好
- 聚类效果依赖于邻接矩阵,不同的邻接矩阵得到的最终聚类效果可能很不同