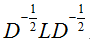聚类讲到此,也是我聚类系列的最后一篇博客了,最后一篇的话我们就来讲一下谱聚类。谱聚类(spectral clustering)是一种基于图论的聚类方法,主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远(或者相似度较低)的两个点之间的边权重值较低,而距离较近(或者相似度较高)的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的
谱聚类相较于前面讲到的最最传统的k-means(当然了,也是很好的一个聚类方法,只不过大家都拿它来做个baseline)聚类方法,谱聚类又具有许多的优点:
1.只需要待聚类点之间的相似度矩阵就可以做聚类了。
2.对于不规则的数据(或者说是离群点)不是那么敏感,个人感觉主要体现在最小化图切割的公式中(因为在RatioCut的优化策略中要除以一个分母|A|,表示当前聚类中含有点 的个数;另外一种策略是Ncut,会除以一个分母vol(A),表示的是当前聚类中的点的度的集合;有了这两个分母的话,若是离群点单独成一个聚类,会造成这两个优化函数的值变大)
3.k-means聚类算法比较适合于凸数据集(数据集内的任意两点之间的连线都在该数据集以内,简单理解就是圆形,可能不准确),而谱聚类则比较通用。
由谱聚类的思想我们可以知道这个算法原理的确简单,但是要完全理解这个算法的话,需要对图论中的无向图,线性代数和矩阵分析都要有一定的了解。我们在这里对这些数学知识不多讲,因为网上已经有很多的好的文章在介绍这些知识了,后边我会给出连接,大家自己去看吧。
谱聚类的具体步骤:
1.相似度矩阵S的构建,构建相似度的矩阵的过程中,可以使用欧氏距离、余弦相似度、高斯相似度等来计算数据点之间的相似度,选用哪个要根据你自己的实际情况来。不过在谱聚类中推荐使用的是高斯相似度,但是我在我的工程中使用的是余弦相似度。
2.相似度图G的构建,主要有一下三种方法:
近邻图:在这种图中,我们将距离小于某个阈值的点连接起来。
K近邻图:在这种图中,以点i,j为例,如果i是j的k近邻之一,那么将i与j连起来。当然,这会造成相似度图G是一种有向图,因为i是j的k近邻之一,但是j不一定是i的k近邻之一。很像我们生活中:你是我的最好朋友,但是我不一定是你的最好朋友。有两种方法可以将此时的图化为无向图:(1)忽略边的方向性,即只要满足i是j的k近邻之一或者j是i的k近邻之一,那么我们就将与连起来。(2)只有满足i是j的k近邻之一而且j是i的k近邻之一,我们才将与连起来。依照(1)方法所得的图被称为k近邻图,依照(2)方法所得的图被称为互k近邻图。
全连接图:在这种图中,我们将所有的点都相互连接起来,同时所有的边的权重设置为相似度。这种图建立的关键在于相似度函数的确立,相似度函数能够较好地反映实际中的相邻关系,那么效果较好。一个相似度函数的例子为高斯相似度函数:,其中参数的选取是个难点。该方法中的参数的作用与近邻图中的的作用是相似的。
通过构建上述的相似度图G我们可以重新得到一个邻接矩阵W.
3.拉普拉斯矩阵
它的定义很简单,拉普拉斯矩阵 L=D−W 。 D 是度矩阵,也就是相似度矩阵的每一行(或者每一列)加和得到的一个对角矩阵。W就是图的邻接矩阵。
4.无向图的切割(也就是求L的特征值和特征向量,之后对特征向量矩阵进行k-means聚类)
这个里面牵扯的只是比较多,图分割理论,求最优化的分割,怎么从图分割就转成了求拉普拉斯的特征值和特征向量等我那个等我那个问题,这里不多介绍,看我后边的参考文献完全可以理解。
算法流程:
输入:样本集D= (x1,x2,...,xn) ,相似矩阵的生成方式, 降维后的维度 k1 , 聚类方法,聚类后的维度 k2
输出: 簇划分 C(c1,c2,...ck2)
.
1) 根据输入的相似矩阵的生成方式构建样本的相似矩阵S
2)根据相似矩阵S构建邻接矩阵W,构建度矩阵D
3)计算出拉普拉斯矩阵L
4)求L的最小的 k1 个特征值所各自对应的特征向量 f
6) 将特征向量组成 n×k1 维的特征矩阵F
7)对F中的每一行作为一个 k1 维的样本,共n个样本,用输入的聚类方法进行聚类,聚类维数为 k2 。
8)得到簇划分 C(c1,c2,...ck2)
代码:
因为自己写出来的代码效率有些慢,所以借用了sklearn包里面的的谱聚类算法,具体代码如下:
#coding:utf-8
from numpy import *
import numpy as np
from sklearn.cluster import SpectralClustering#定义欧式距离
def ou_dis(v1,v2):return norm(v1-v2)#定义余弦相似度
def cosin_sim(v1,v2):product=v1.dot(v2)normA=sqrt(v1.dot(v1))normB=sqrt(v2.dot(v2))return product / (normA*normB)#定义高斯相似度
def gaussian_simfunc(v1,v2,sigma=1):tee=(-norm(v1-v2)**2)/(2*(sigma**2))return exp(tee)#构建相似度矩阵W
def construct_W (vec):n = len (vec)W = zeros ((n, n))for i in xrange(n):if(i % 1000==0):print "c--"+str(i)for j in xrange(i,n):W[i,j] = W[j,i] = cosin_sim (vec[i], vec[j]) #选用的是高斯相似度函数就算相似度return Wif __name__=='__main__':f=open(r'E:\test_sc\vec_30.txt') #打开待聚类文本list=f.readlines() #将数据全部读到list中roW=len(list) #得到待聚类的数据点的个数col=len(list[0].split())-1 #得到待聚类的数据点的维度(因为含有标签,所以要减去一)dict_my={} #key-数字,value-词语,是数字和词语对应的词典,后边将词归到类别中用flag=0 #计数作用vec=zeros((roW,col)) #存放词语的向量 for line in list: #循环遍历每一个样本点,将标签存到dict中,将向量存放到vec中if flag%1000==0:print 'read--'+str(flag)s=line.split()dict_my[flag]=s[0]del s[0]vec[flag]=sflag+=1f.close()W=construct_W(vec) #构建相似度矩阵labels=SpectralClustering(n_clusters=6,affinity='nearest_neighbors',n_neighbors=4,eigen_solver='arpack',n_jobs=20).fit_predict(W)relDict={}for i in range(8):relDict[i]=[]num=0for i in labels:relDict[i].append(dict_my[num])num=num+1file_w=open(r'E:\test_sc\rel_200.txt','w')for key,value in relDict.items():file_w.write(str(key)+':')for word in value:file_w.write(word+" ")file_w.write("\n")file_w.close()print 'over-----'

参考目录:
1.http://www.cnblogs.com/pinard/p/6221564.html
2.http://www.cnblogs.com/FengYan/archive/2012/06/21/2553999.html
3.http://blog.csdn.net/zhangyi880405/article/details/39781817
4.http://www.cnblogs.com/pinard/p/6221564.html
5.http://blog.csdn.net/u014568921/article/details/49287565#t8
6.http://www.cnblogs.com/pinard/p/6235920.html
7.http://scikit-learn.org/dev/modules/generated/sklearn.cluster.SpectralClustering.html#sklearn.cluster.SpectralClustering