1.配置 FindBugs
打开 Eclipse,通过【Window -> Preferences】下【Java -> FindBugs】查看 FindBugs的
配置情况。问题: 这里可以配置 FindBugs的哪些特性?
选择导入的项目,通过【Window -> Preferences】下【Java -> FindBugs】查看 FindBugs的
配置情况,得出由图所示可知FindBugs的特性:
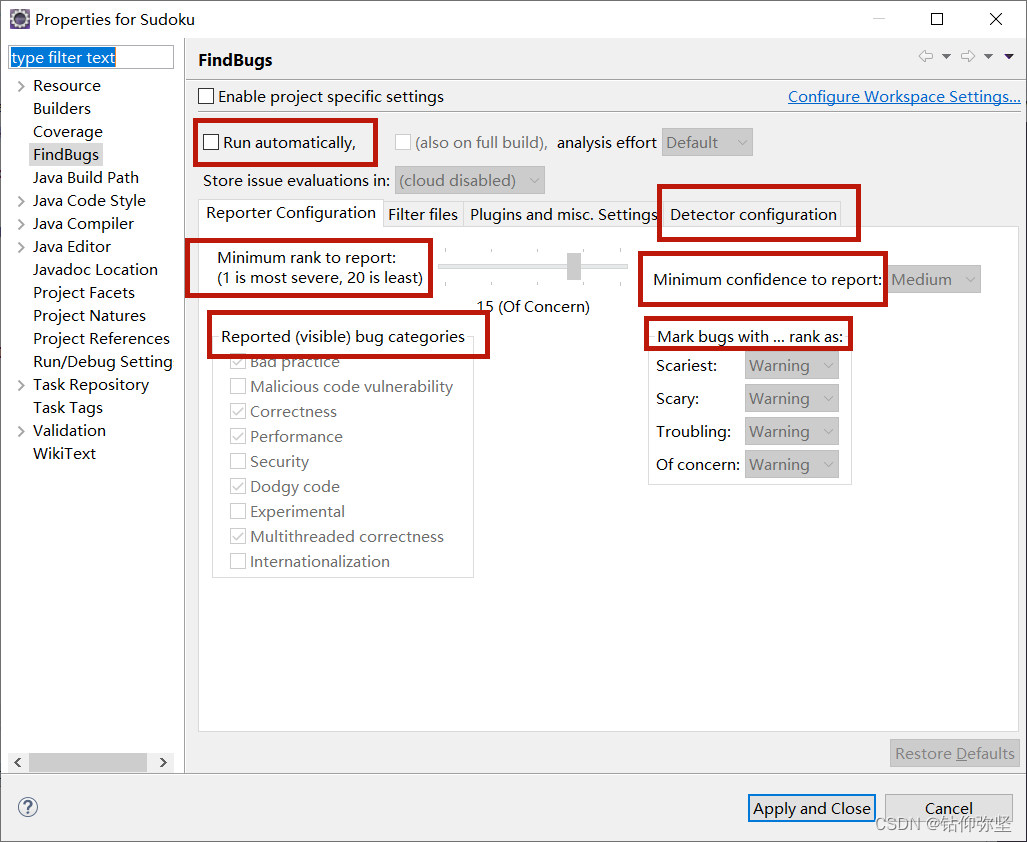
1.Run Automatically开关
(1)当此项选中后,FindBugs将会在你修改Java类时自动运行,如你设置了Eclipse自动编译开关后,当你修改完Java文件保存,FindBugs就会运行,并将相应的信息显示出来。
(2)当此项没有选中,你只能每次在需要的时候自己去运行FindBugs来检查你的代码。
2.Minimum confidence to report选择项
这个选择项是让你选择哪个级别的信息进行显示,有Low、Medium、High三个选择项可以选择,很类似于Log4J的级别设置。 比如:
(1)你选择了High选择项,那么只有是High级别的提示信息才会被显示。
(2)你选择了Medium选择项,那么只有是Medium和High级别的提示信息才会被显示。
(3)你选择了Low选择项,那么所有级别的提示信息都会被显示。
此外,还有一个拖动条供选择rank等级(1-20),rank越高,严重程度越低,显示的信息越多。

3.Reported(visible) bug categories选择项(左侧是分类,右侧是等级)
在这里是一些显示Bug分类的选择:
Correctness关于代码正确性相关方面的
Performance关于代码性能相关方面的
Multithreaded correctness关于代码多线程正确性相关方面的
Malicious code vulnerability关于恶意破坏代码相关方面的
Internationalization关于代码国际化相关方面的

严重程度:Scariest>Scary>Troubling>Of concern,这个和rank的设置1-20是匹配的。
4. Detector configuration选择项
在其他的tab标签页中,显示了更多更详细的bug check configuration,用户可以根据需要进行选择和配置。
2.在 Sudoku上运行 FindBugs
打开 Eclipse,在 Sudoku项目上右键选择 FindBugs。
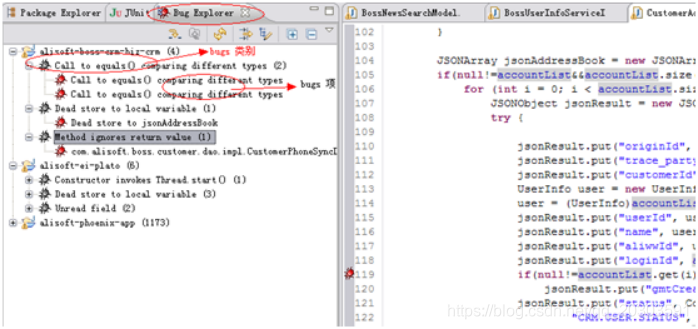
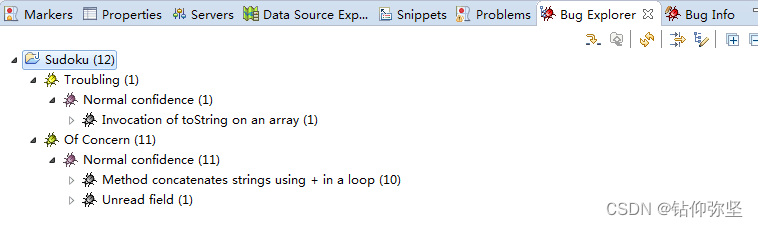
A. 查看 FindBugs发现的问题,一共有几类问题,各是什么含义?将这几类问题翻译成
中文;
答:三类问题。如图:
1. 对数组使用toString方法
Bug: Invocation of toString on combination in solver.Matrix.main(String[])
The code invokes toString on an array, which will generate a fairly useless result such as [C@16f0472. Consider using Arrays.toString to convert the array into a readable String that gives the contents of the array. See Programming Puzzlers, chapter 3, puzzle 12.
解释:在数组上调用toString,这将得到一个没有用处的结果。在考虑使用数组时,toString将数组转换成一个可读的字符串数组的内容。
2. matrix .compute()在循环中使用+连接字符串
Bug: solver.Matrix.compute() concatenates strings using + in a loop
The method seems to be building a String using concatenation in a loop. In each iteration, the String is converted to a StringBuffer/StringBuilder, appended to, and converted back to a String. This can lead to a cost quadratic in the number of iterations, as the growing string is recopied in each iteration.
Better performance can be obtained by using a StringBuffer (or StringBuilder in Java 1.5) explicitly.
解释:该方法似乎是在循环中使用连接构建字符串。在每次迭代中,字符串被转换为
StringBuffer/StringBuilder,附加到字符串,然后再转换回字符串。这可能导致迭代次数的二次成本,因为不断增长的字符串在每次迭代中重复出现。
通过显式地使用StringBuffer(或Java 1.5中的StringBuilder)可以获得更好的性能。
3.读取问题
Bug: Unread field: gui.MainWindow.m_gameOutput
This field is never read. Consider removing it from the class.
解释:存在未读字段:gui.MainWindow.m_gameOutput,也就是说这个字段永远不会被读取。
B. 如何解决 FindBugs指出的问题?请修改 Sudoku程序,以改正所有 FindBugs指出的
问题。注意:同类错误仅需记录一次修改思想即可。
答:修改方法如下:
1. 对数组使用toString方法
解决方法:可以利用Arrays类位于 java.util 包中,主要包含了操纵数组的各种方法
使用时需要导入包:import java.util.Arrays;

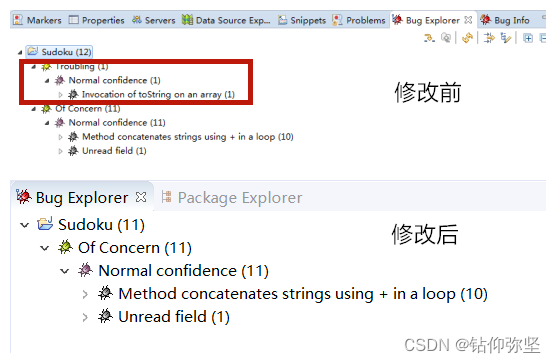
修改之后,我们发现bug已经消失。
解决结果:
2. matrix .compute()在循环中使用+连接字符串
(由于思想一样,这里只举例一个来修改)
旧代码为:
String fixed = "";int total = 0;for(int i=0, rows = m_field.length; i<rows; i++){for(int j=0, cols = m_field[i].length; j<cols; j++) {total ++;index ++;if(m_field[i][j] == 0)m_unfixedNumber ++;elsefixed += m_field[i][j]; }}将原来的代码改成:
StringBuffer buf = new StringBuffer();int total = 0;for(int i=0, rows = m_field.length; i<rows; i++){for(int j=0, cols = m_field[i].length; j<cols; j++) {buf.append(m_field[i][j]);}}{ String fixed = buf.toString();解决结果:
Normal confidence只剩9个。该Bug已经解决。
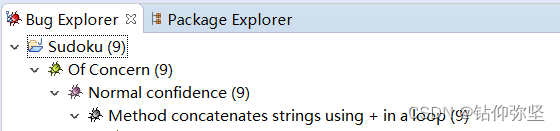
3.读取问题
解决方法:可以将语句private GameOutput m_gameOutput = null; 与m_gameOutput = new GameOutput(m_sashForms, SWT.BORDER, m_gameField);语句删除即可
解决结果:
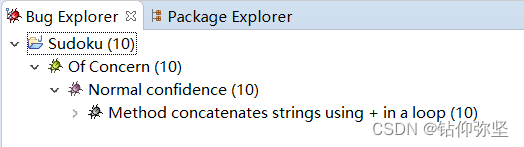
Unread field已经不再提示。该Bug已经解决。